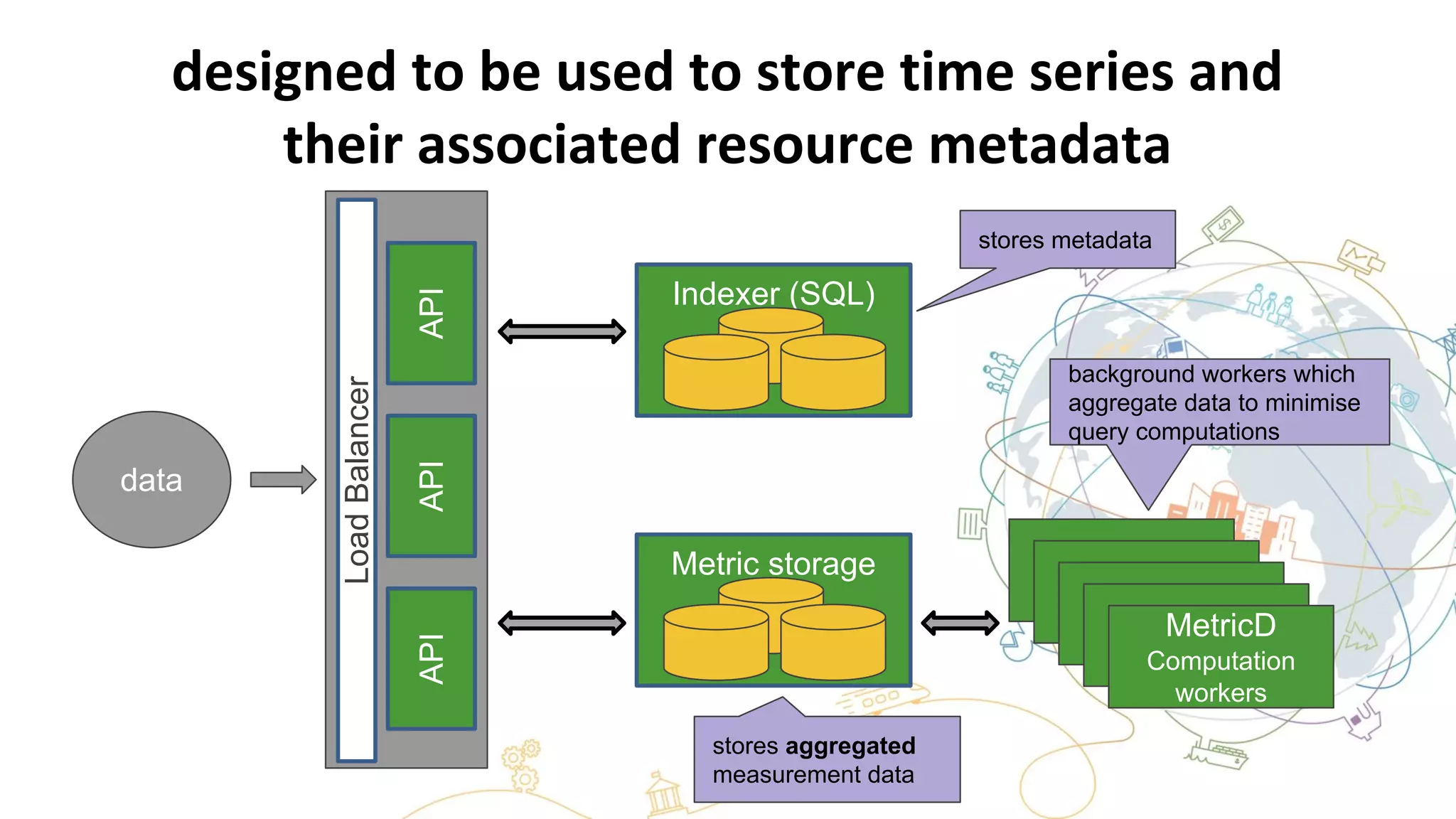
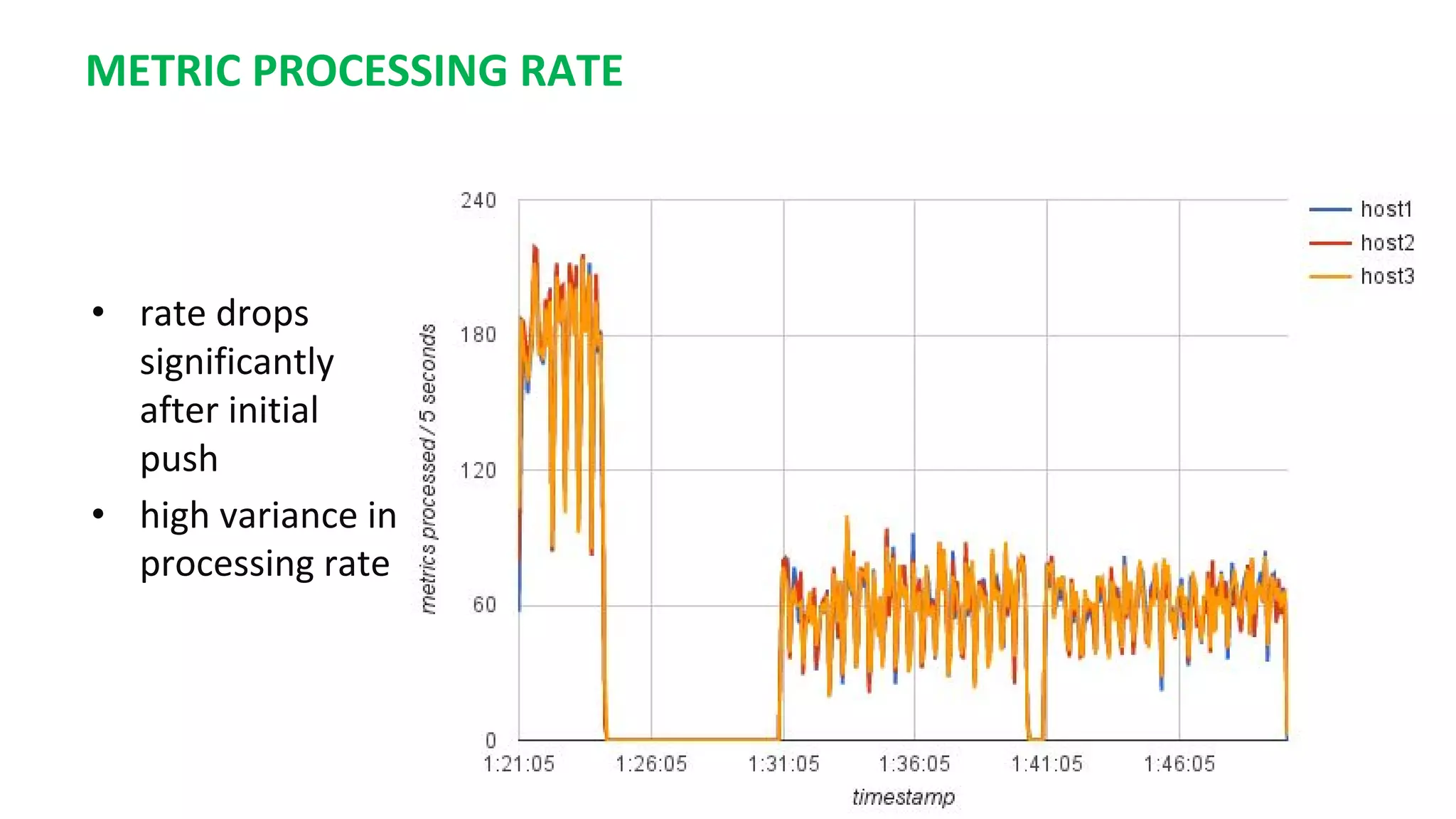
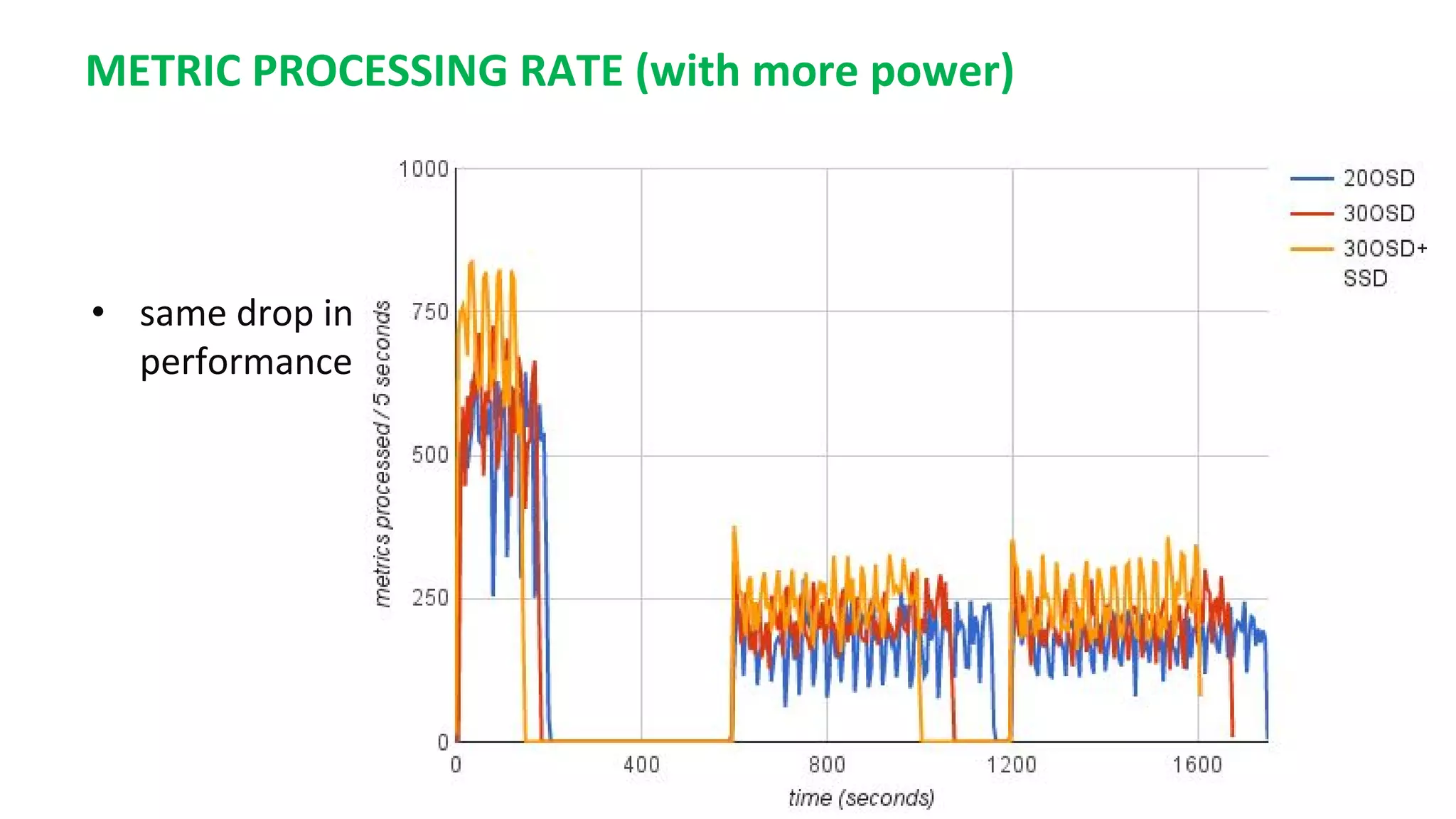
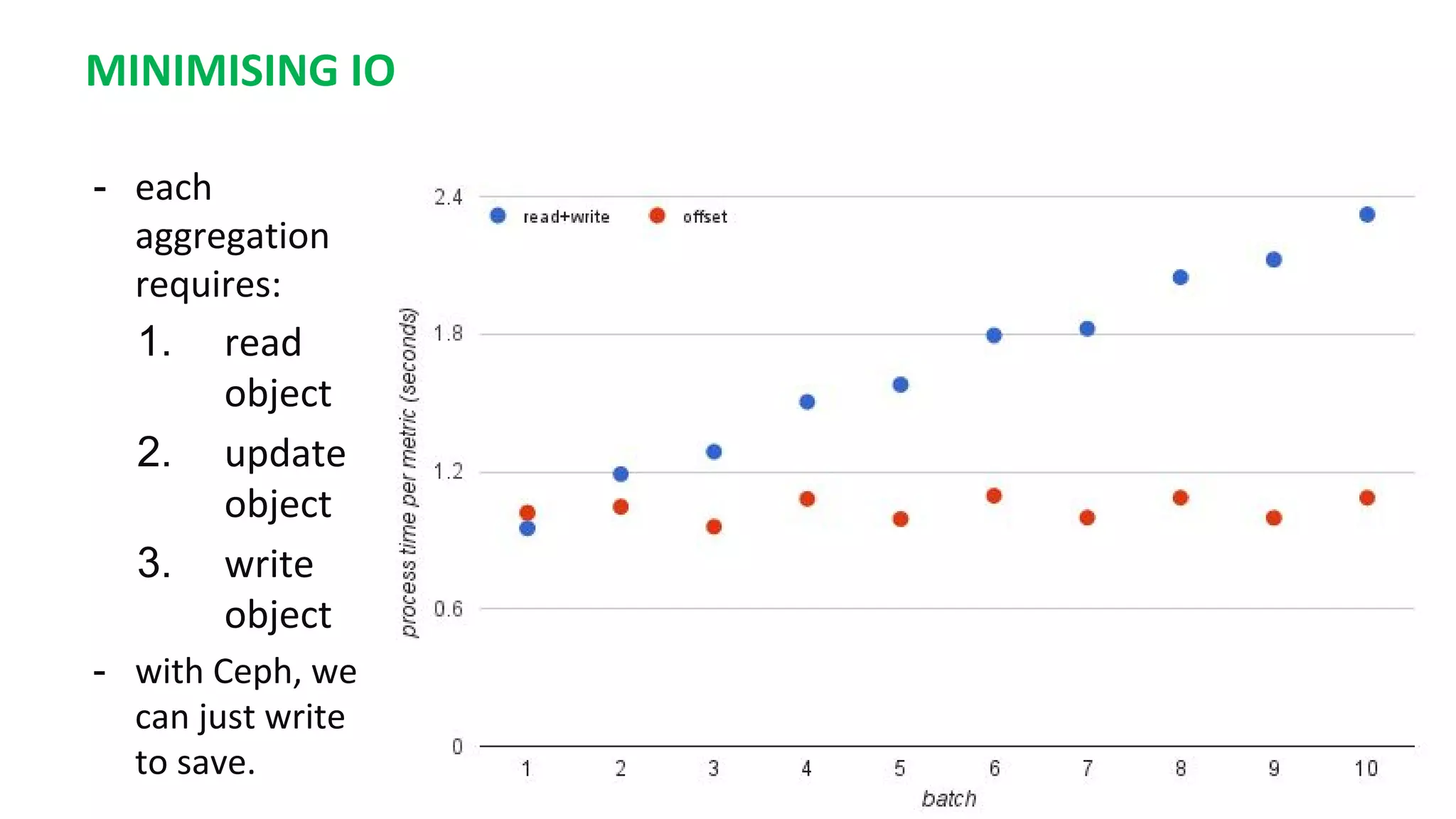
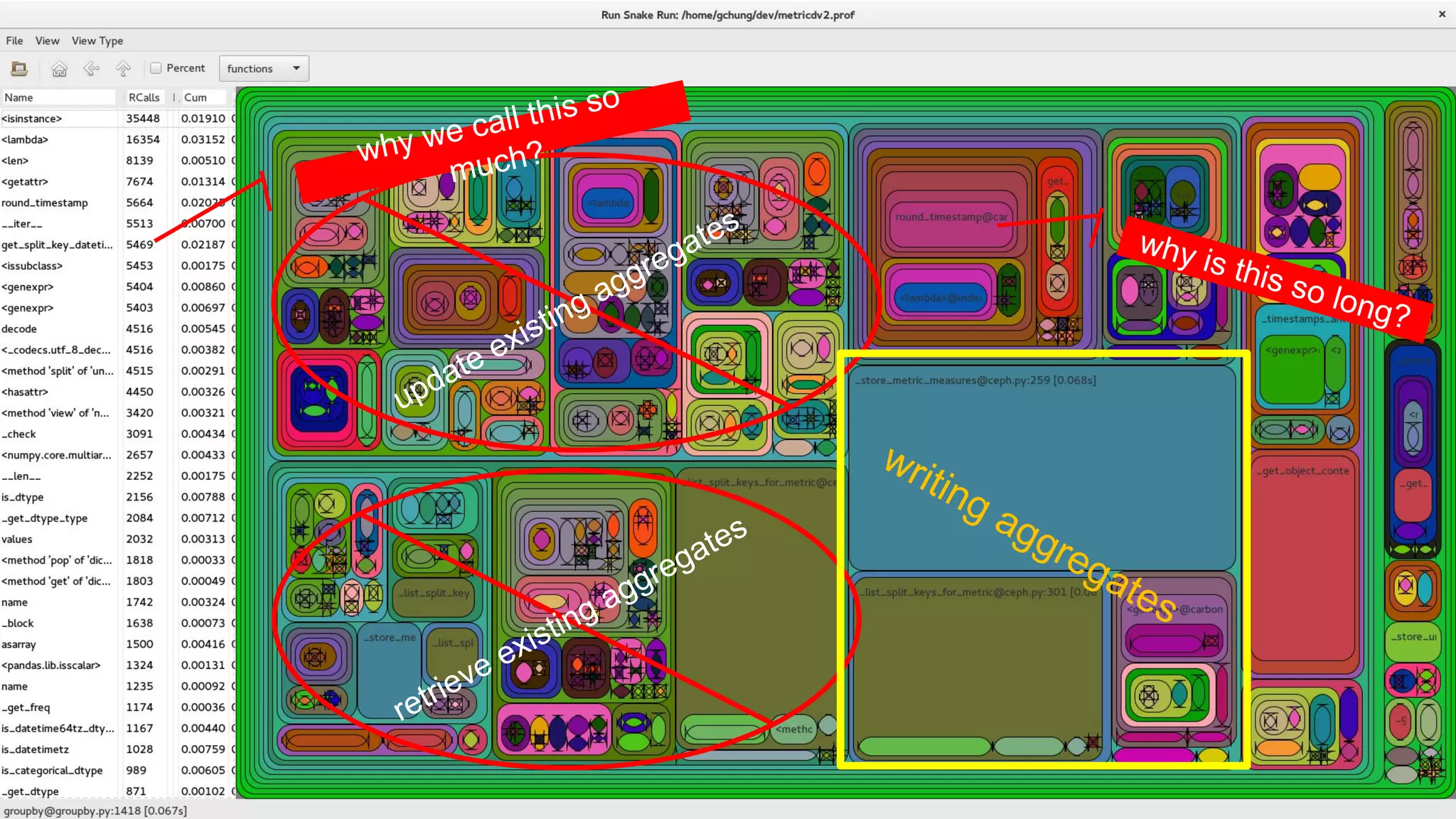
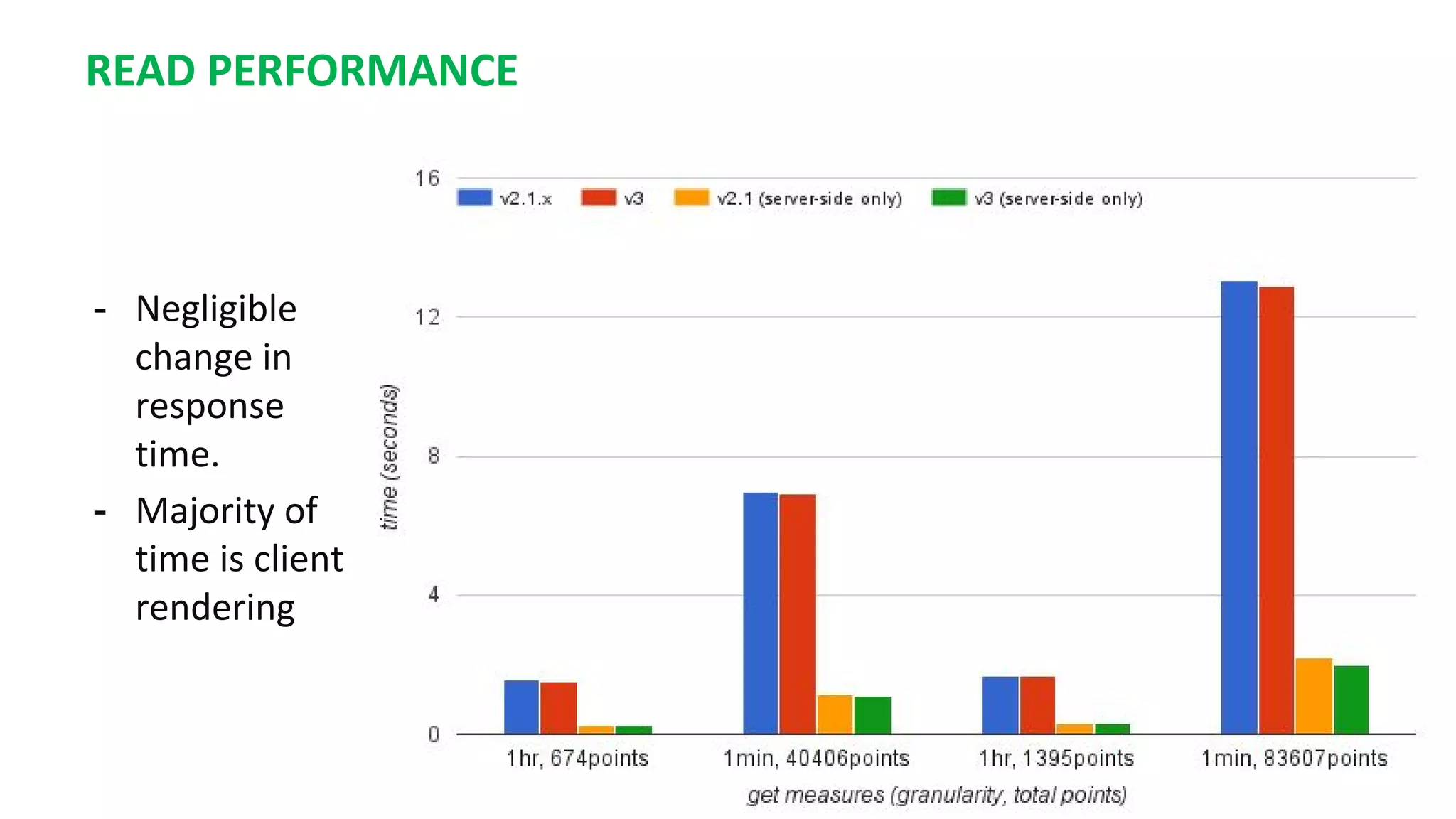
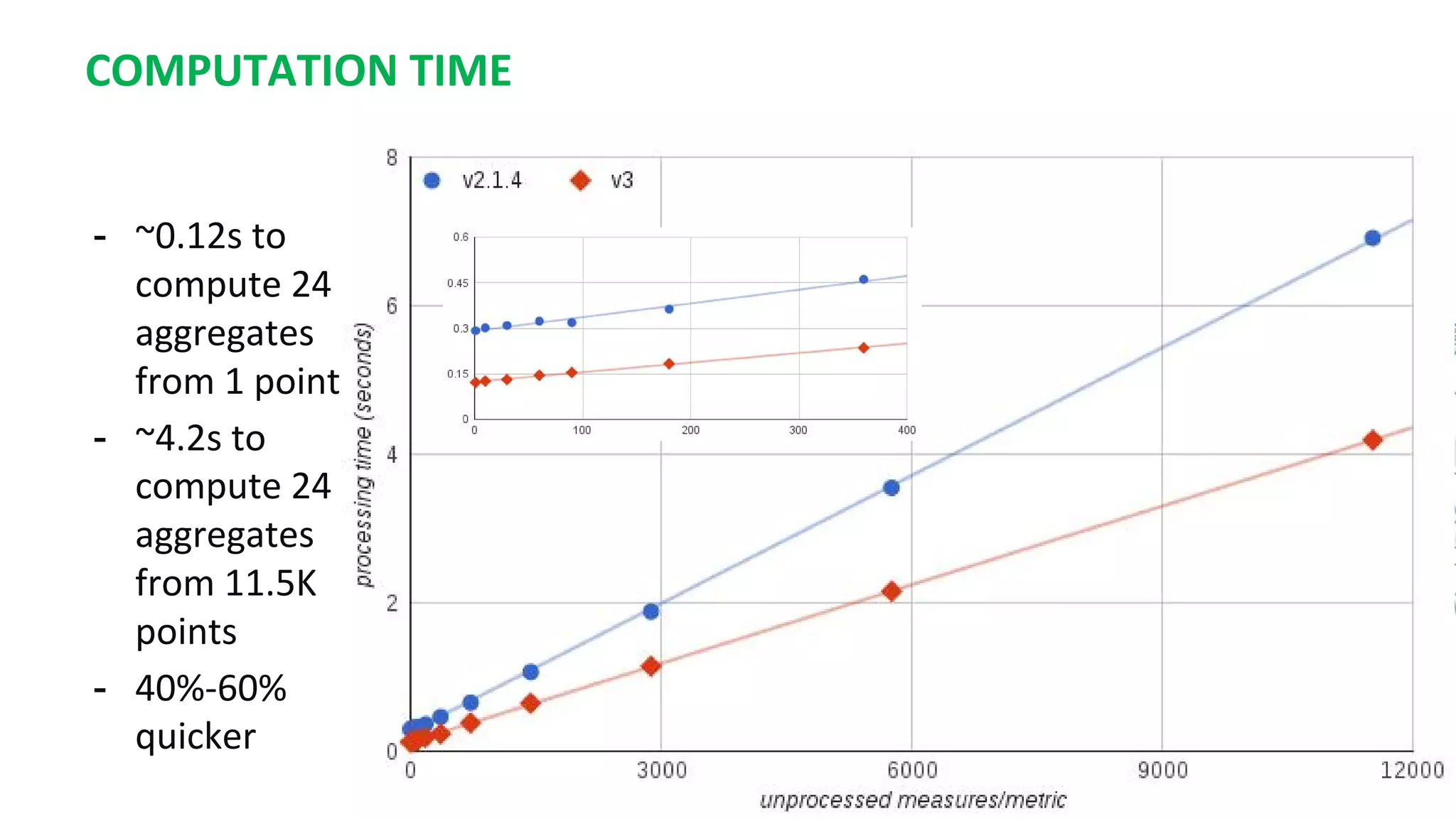
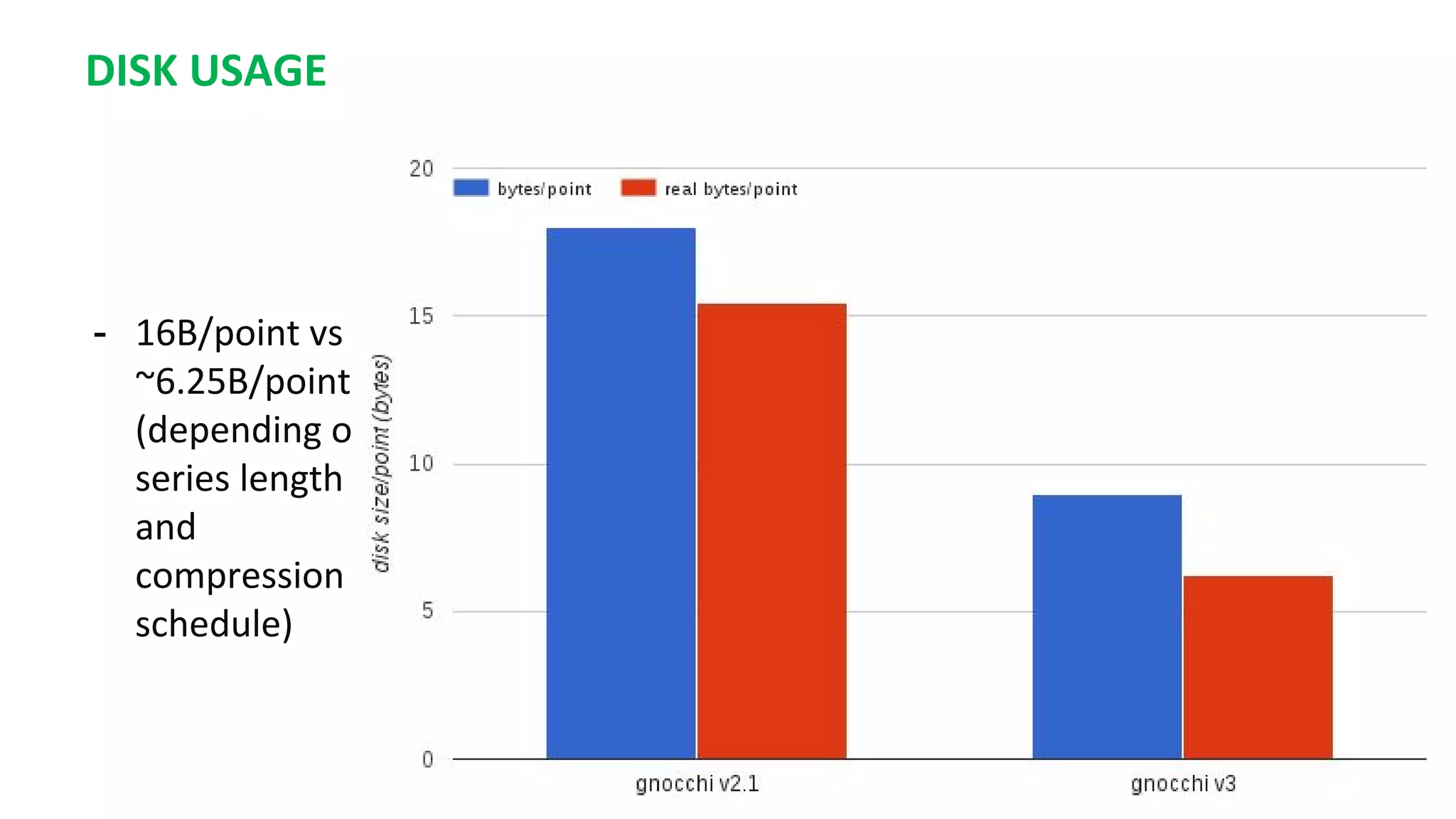
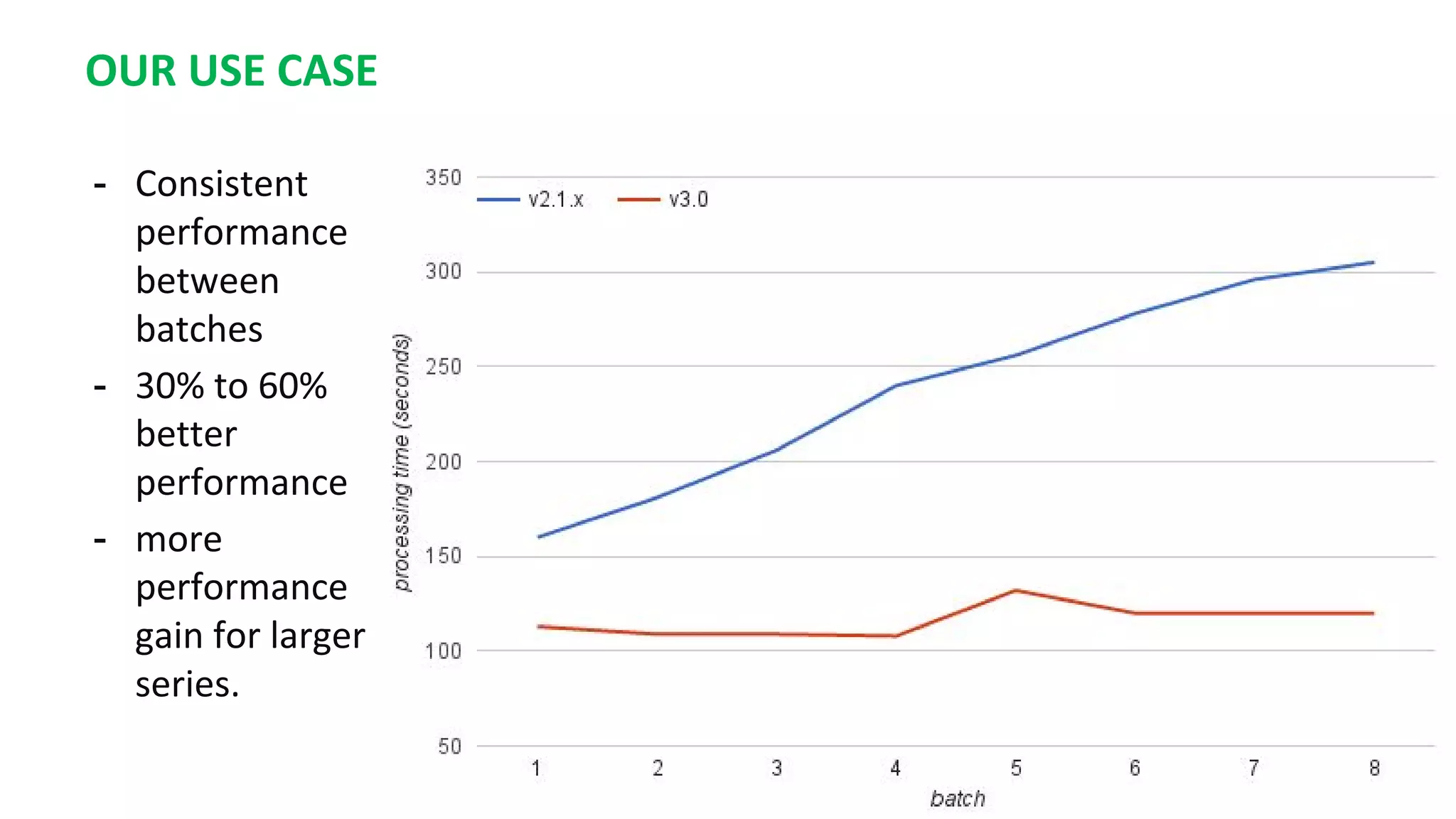
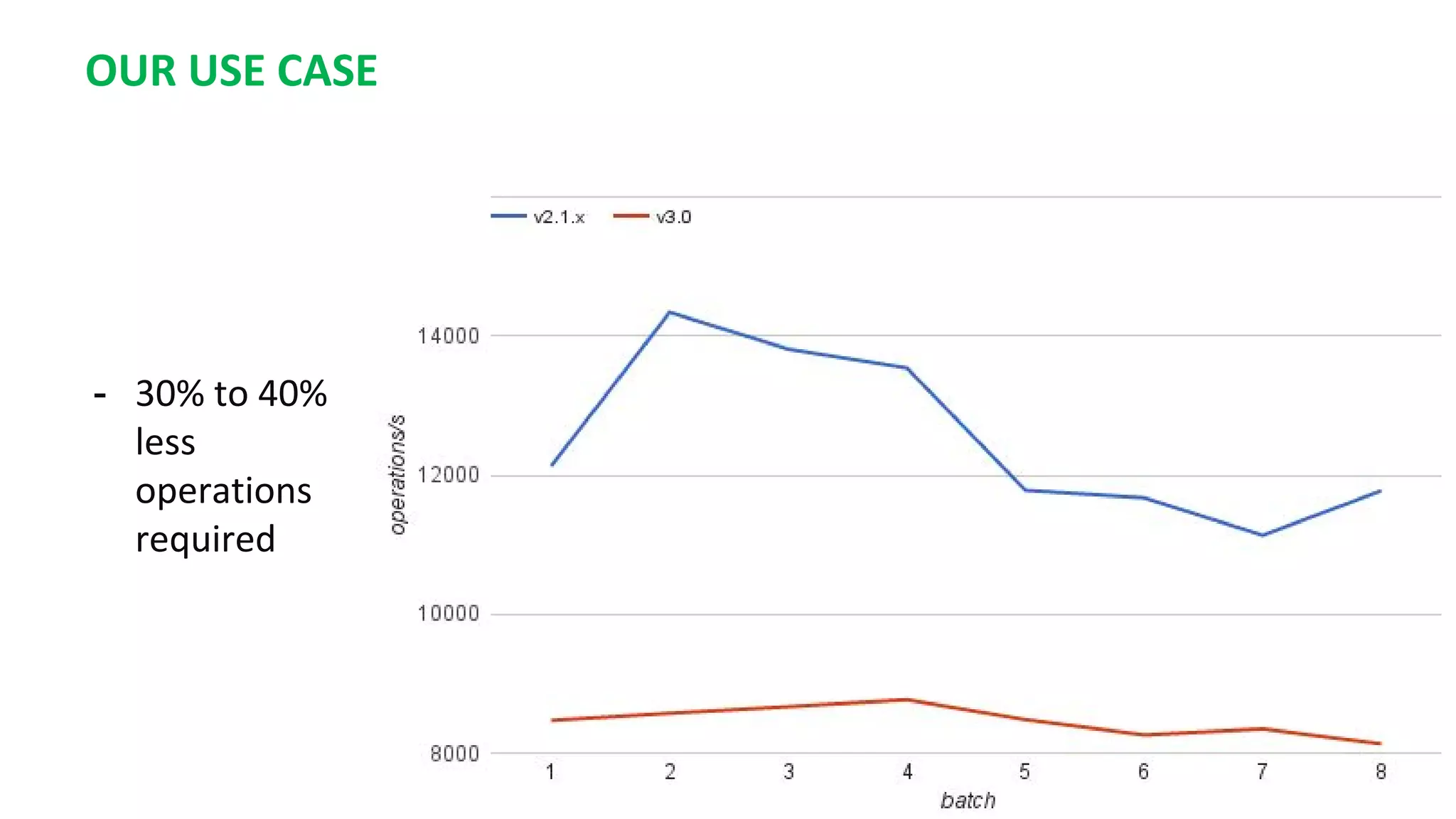
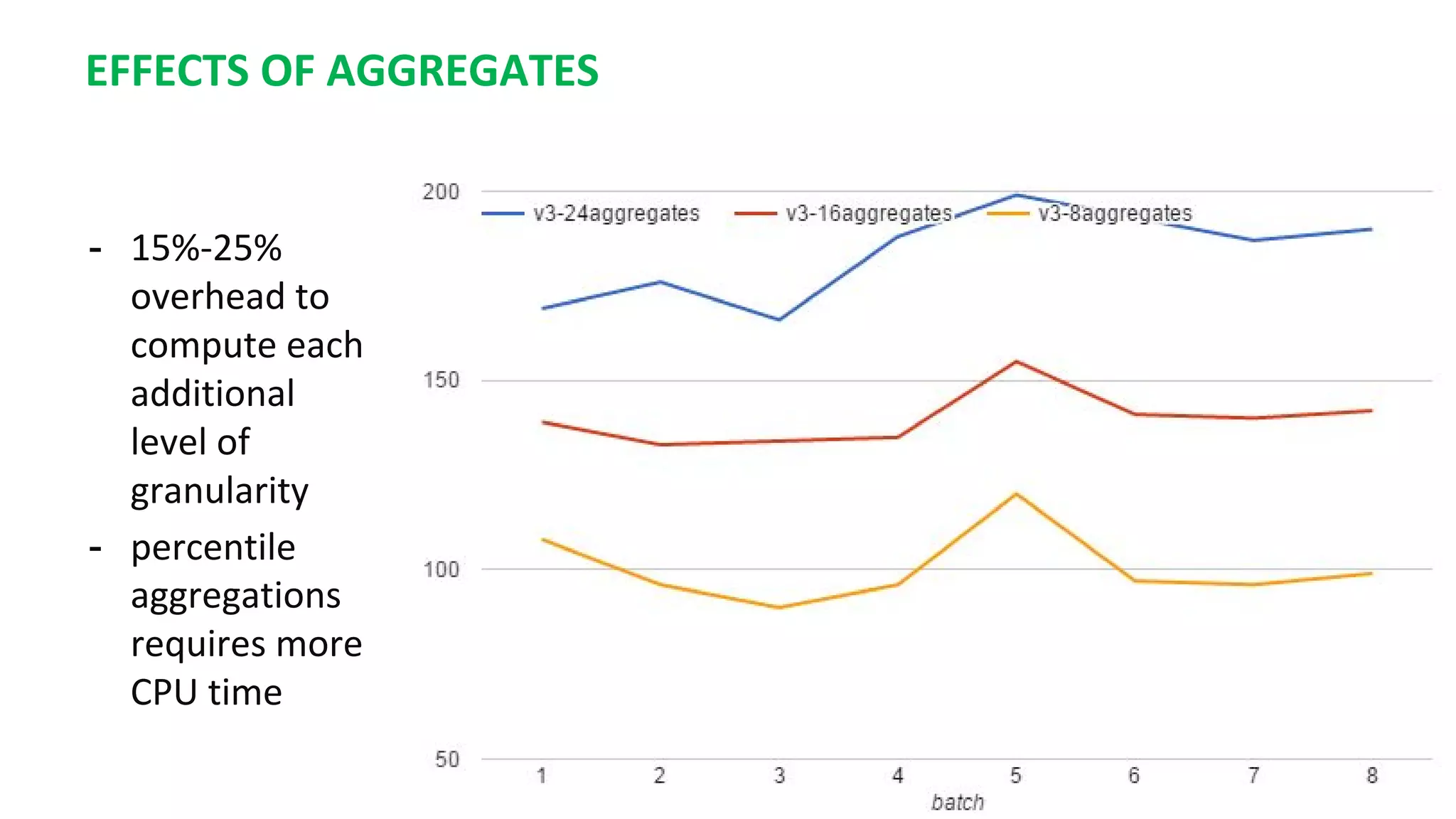
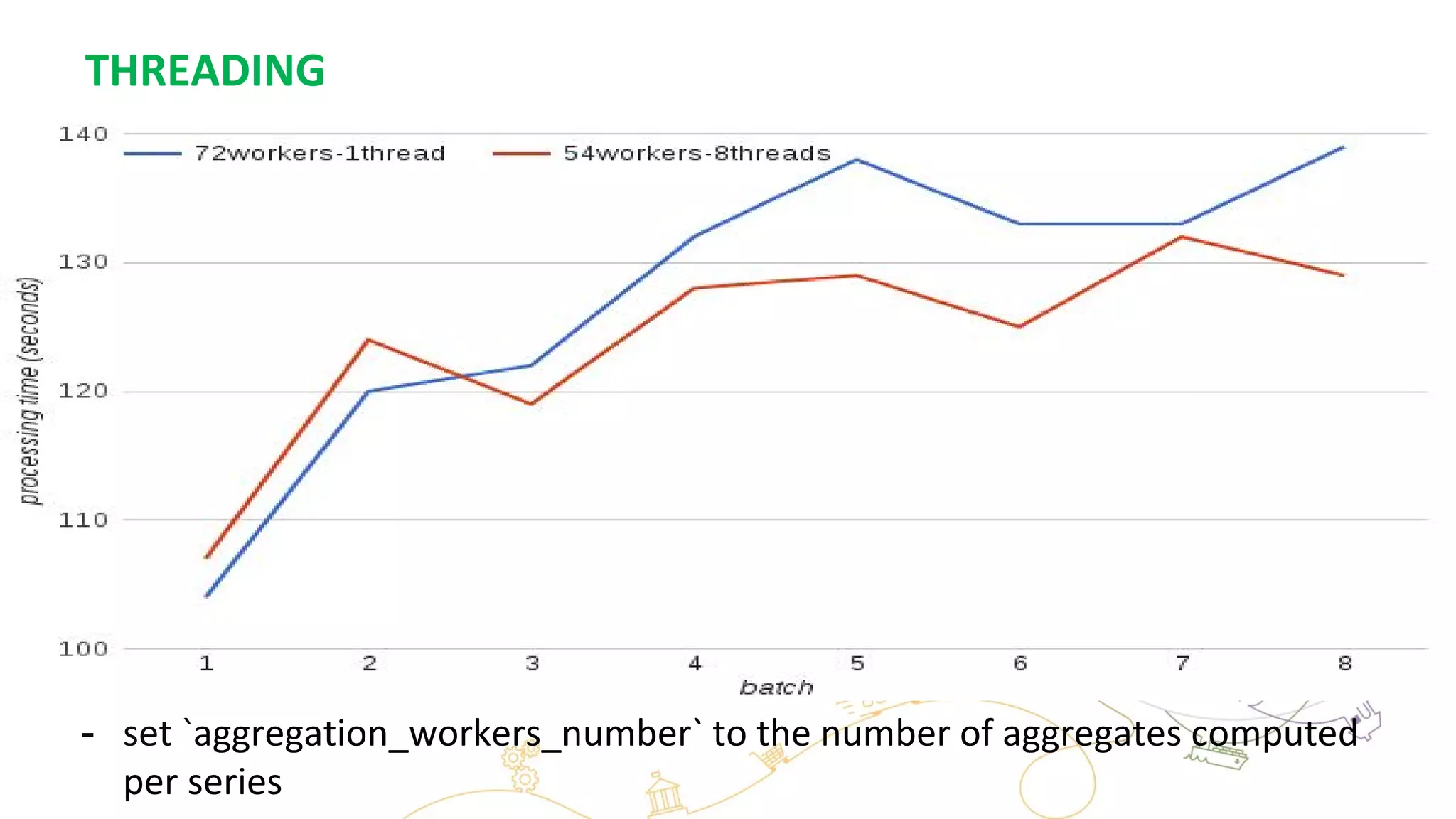
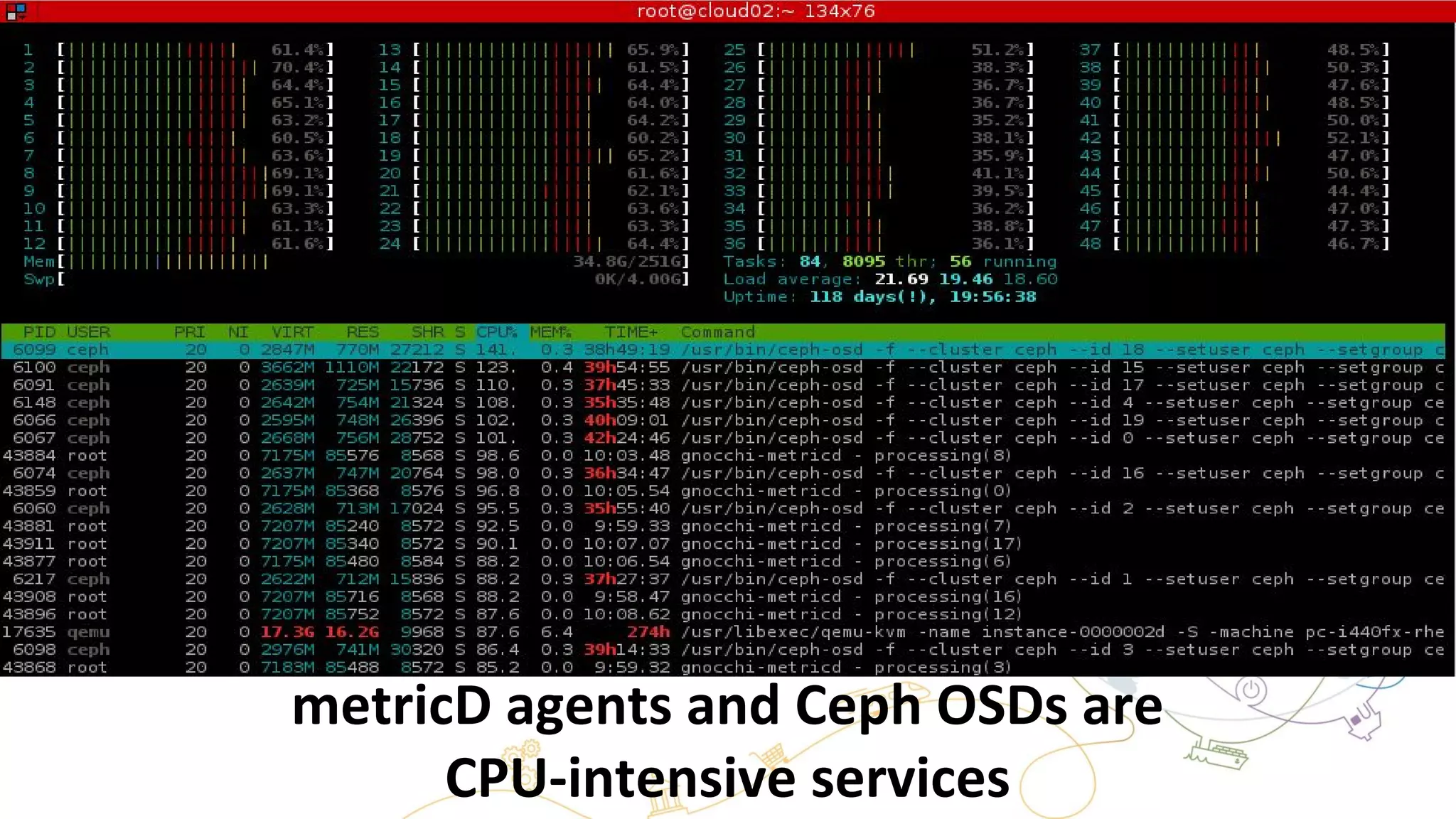
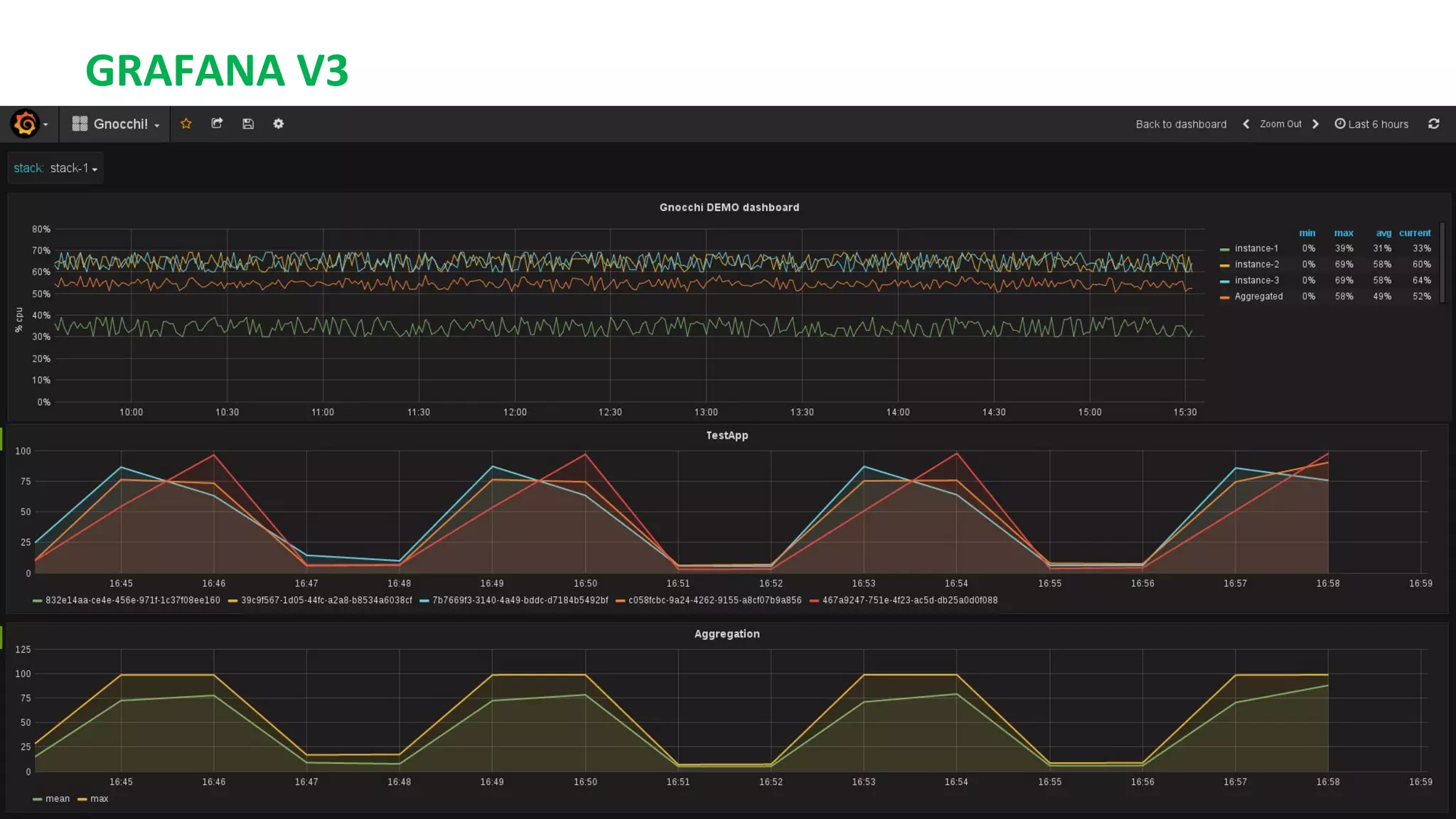
This document summarizes the author's experience optimizing Gnocchi, an open source time-series database, to store metrics for hundreds of thousands of resources over many months. The author describes improving performance by adding Ceph storage nodes, tuning Ceph configurations, minimizing I/O operations, and improving the storage format. Benchmark results show the new version achieves 50% higher write throughput, 40-60% faster computation times, 30-60% better overall performance, and 30-40% fewer operations. Usage hints are also provided to help optimize for different use cases.















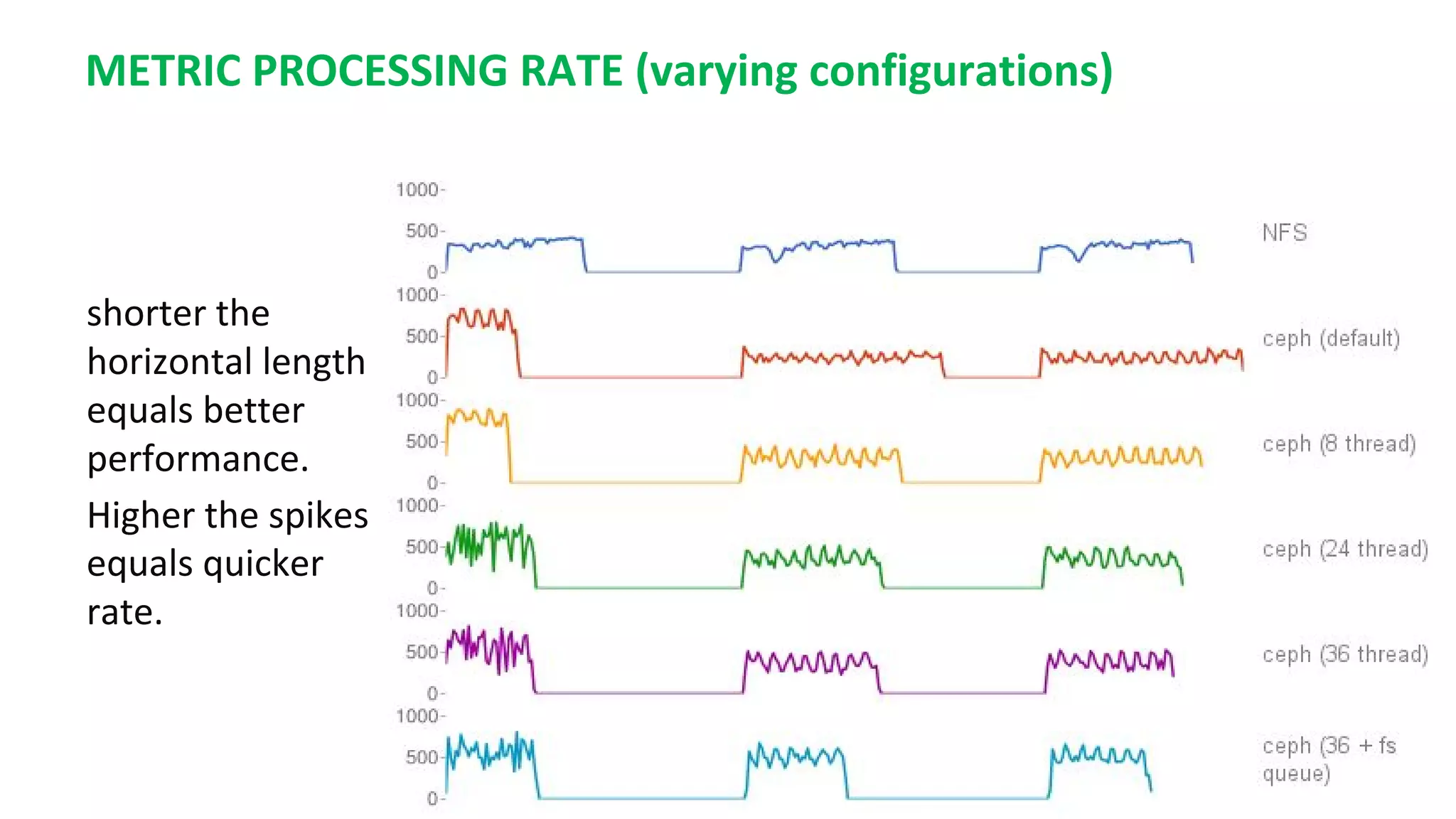
![CEPH CONFIGURATIONS
original conf
[osd]
osd journal size = 10000
osd pool default size = 3
osd pool default min size = 2
osd crush chooseleaf type = 1
[osd]
osd journal size = 10000
osd pool default size = 3
osd pool default min size = 2
osd crush chooseleaf type = 1
osd op threads = 36
filestore op threads = 36
filestore queue max ops = 50000
filestore queue committing max
ops = 50000
journal max write entries = 50000
journal queue max ops = 50000
good enough conf
http://ceph.com/pgcalc/ to calculate required # of placement groups](https://image.slidesharecdn.com/gnocchiv3brownbag-161101165626/75/Gnocchi-v3-brownbag-19-2048.jpg)






























































![[BDD 2025 - Full-Stack Development] The Modern Stack: Building Web & AI Appli...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-themodernstackbuildingwebaiapplicationswithserverless-251124030844-388cf04f-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Full-Stack Development] Agentic AI Architecture: Redefining Syste...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-agenticaiarchitectureredefiningsystemcommunication-251124030838-e6c70cc2-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Full-Stack Development] Digital Accessibility: Why Developers nee...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-digitalaccessibilitywhydevelopersneedtoknowandcarein2025-251127011019-0674441d-thumbnail.jpg?width=640&height=640&fit=bounds)


![[BDD 2025 - Artificial Intelligence] Building AI Systems That Users (and Comp...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-buildingaisystemsthatusersandcompanieslove-251124030845-038f7732-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Mobile Development] Crafting Immersive UI with E2E and AGSL Shade...](https://cdn.slidesharecdn.com/ss_thumbnails/md-craftingimmersiveuiwithe2eandagslshaderveronicaputrianggraini-251124030840-0c677f44-thumbnail.jpg?width=640&height=640&fit=bounds)





![[BDD 2025 - Artificial Intelligence] AI for the Underdogs: Innovation for Sma...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-aifortheunderdogsinnovationforsmallbusinesses-251124030839-72a599a4-thumbnail.jpg?width=640&height=640&fit=bounds)




