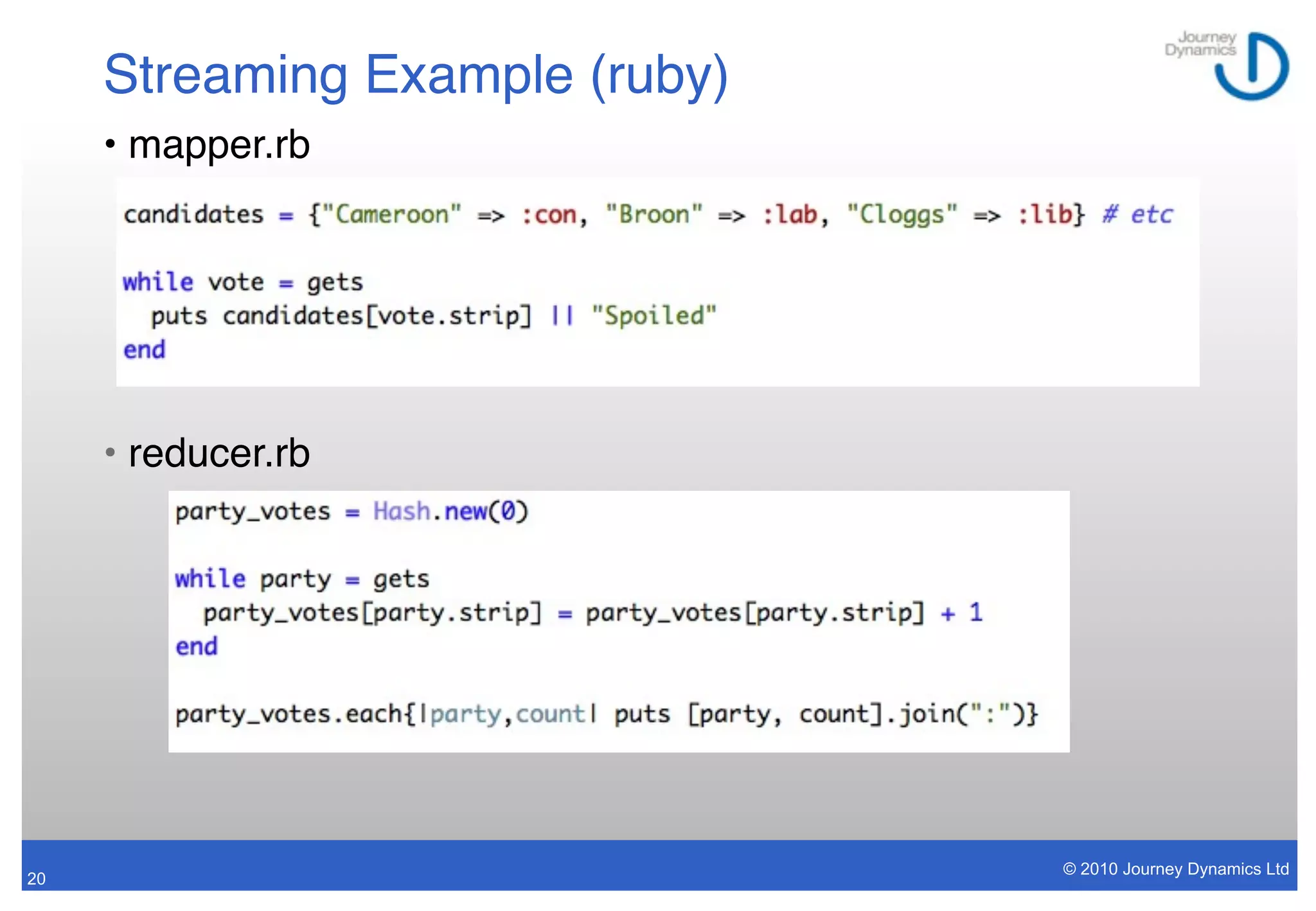
MapReduce with Apache Hadoop is a framework for distributed processing of large datasets across clusters of computers. It allows for parallel processing of data, fault tolerance, and scalability. The framework includes Hadoop Distributed File System (HDFS) for reliable storage, and MapReduce for distributed computing. MapReduce programs can be written in various languages and frameworks provide higher-level interfaces like Pig and Hive.











![MapReduce
• “Single Threaded” MapReduce:
cat input/* | map | sort | reduce > output
• Map program parses the input and emits [key,value] pairs
• Sort by key
• Reduce computes output from values with same key
Reduce
Map Sort
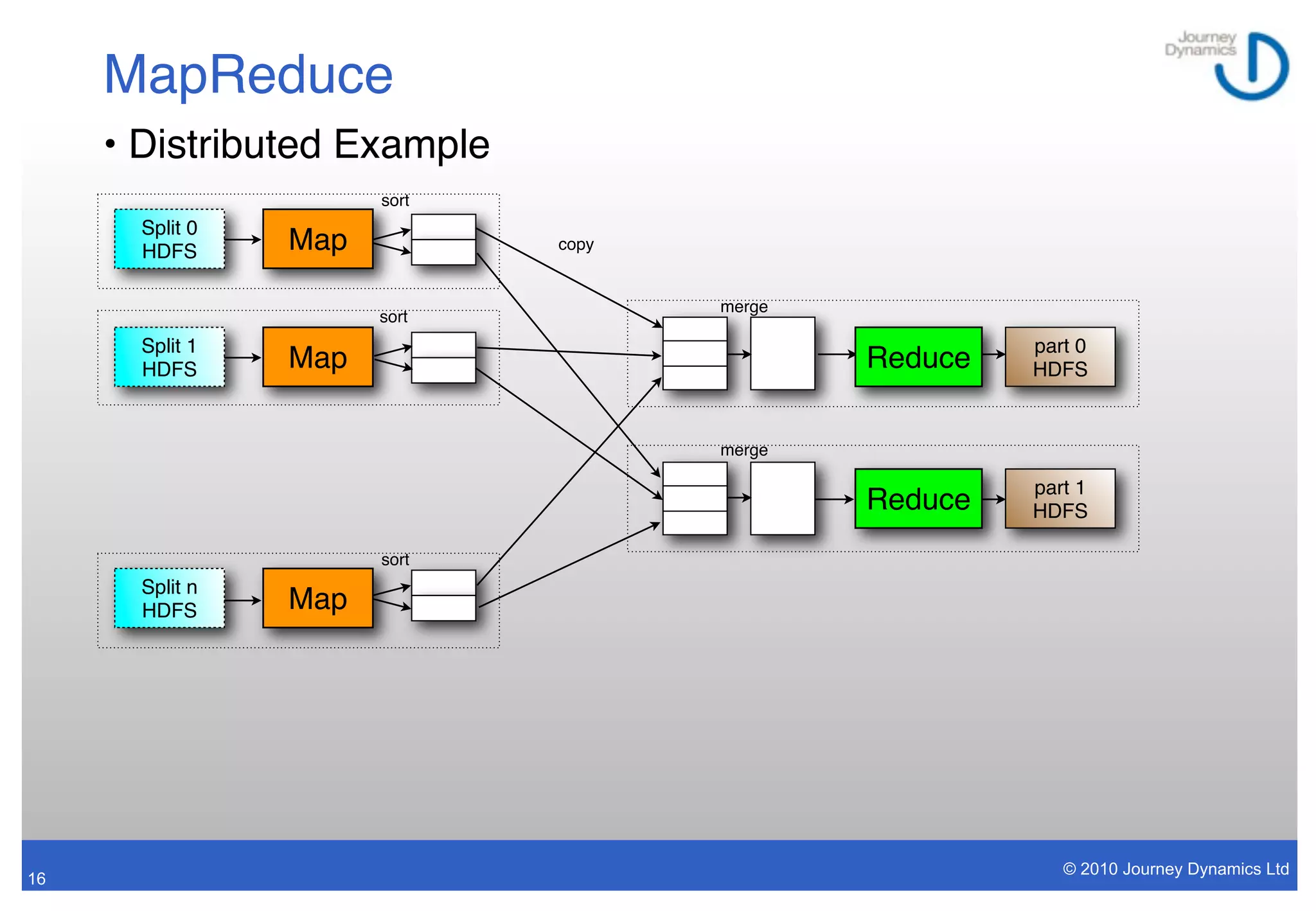
• Extrapolate to PB of data on thousands of nodes
© 2010 Journey Dynamics Ltd
15](https://image.slidesharecdn.com/hadoop-accu2010-100416011416-phpapp01/75/Introduction-to-Hadoop-ACCU2010-16-2048.jpg)