Downloaded 135 times

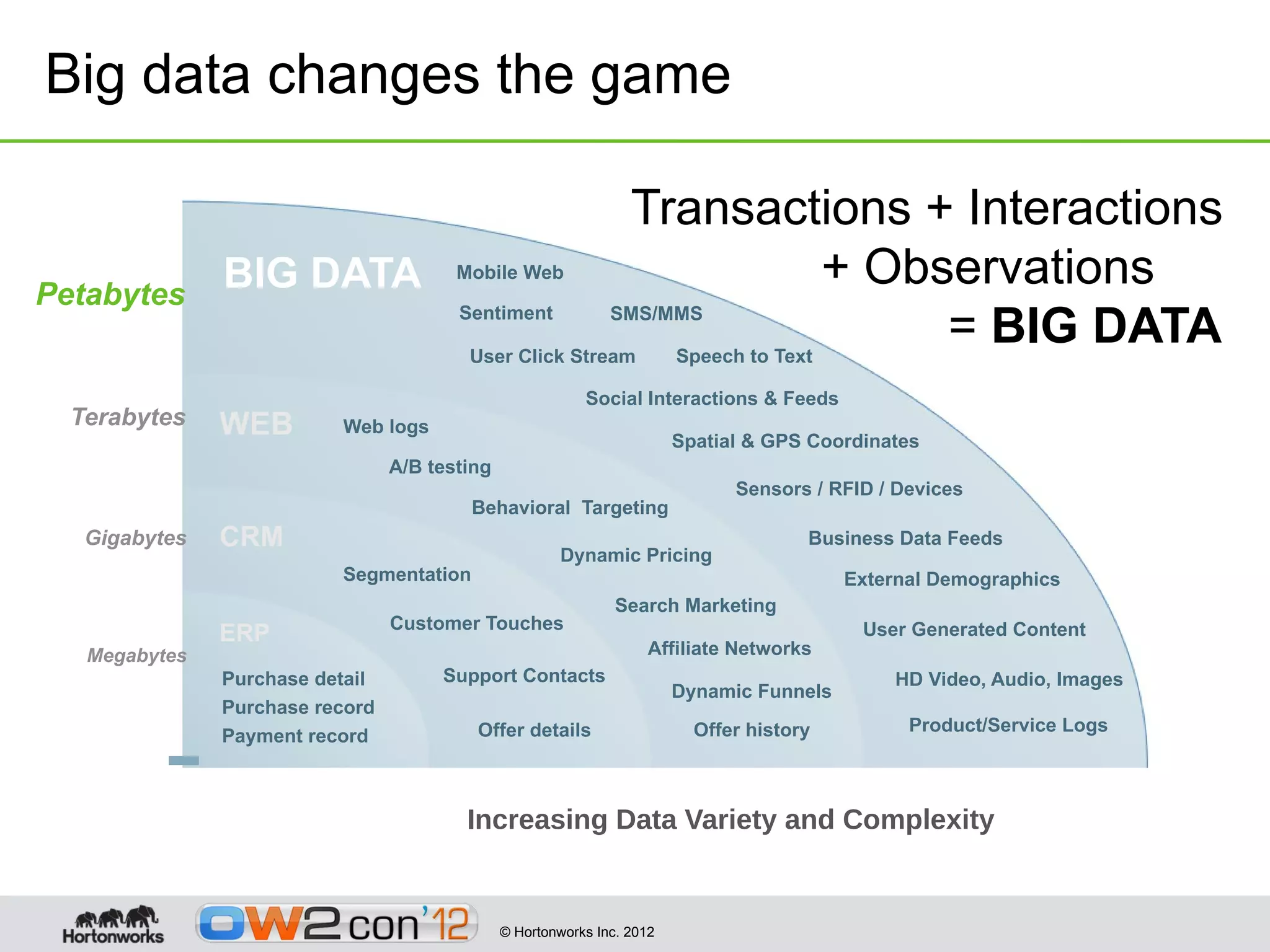



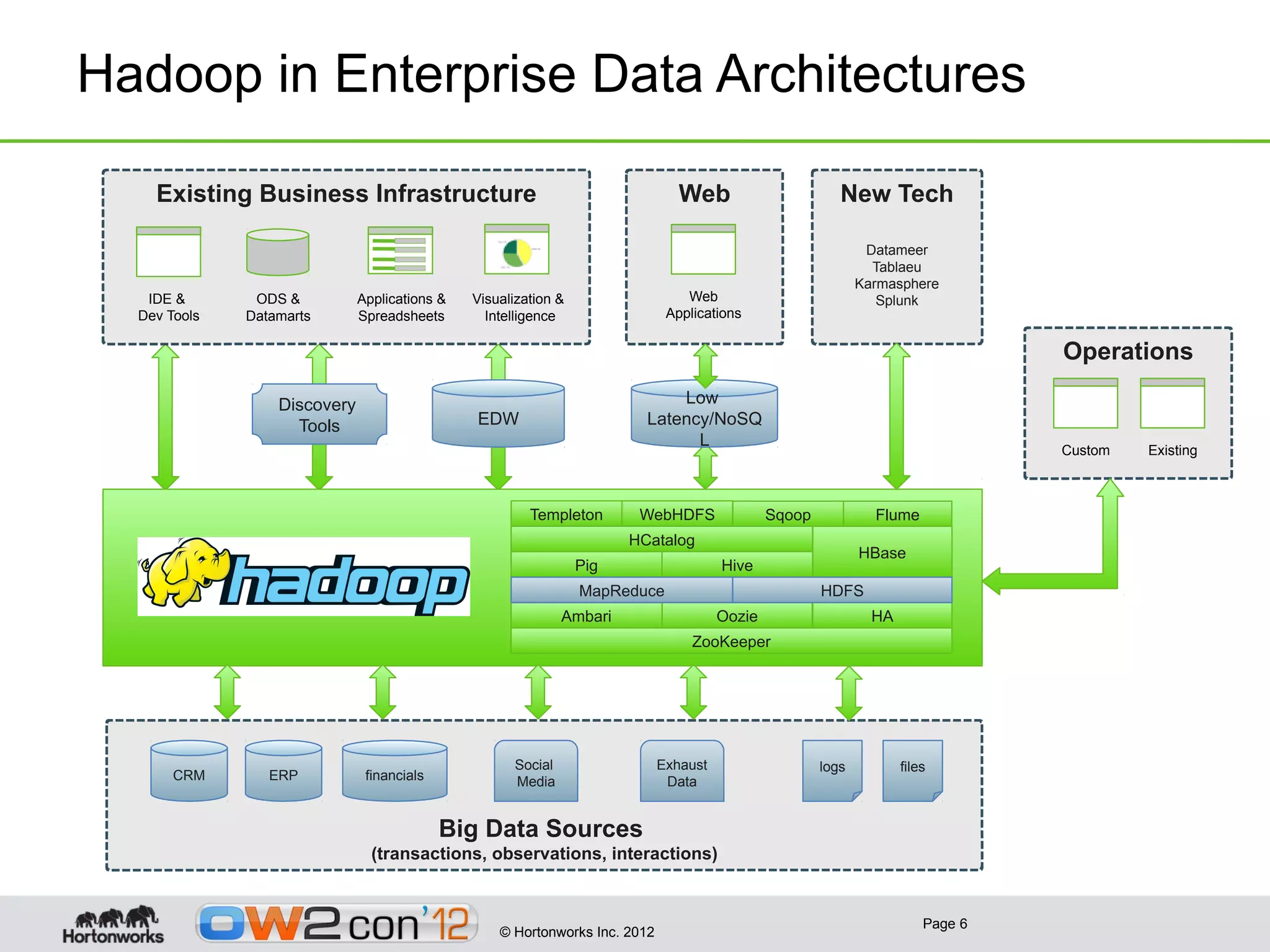
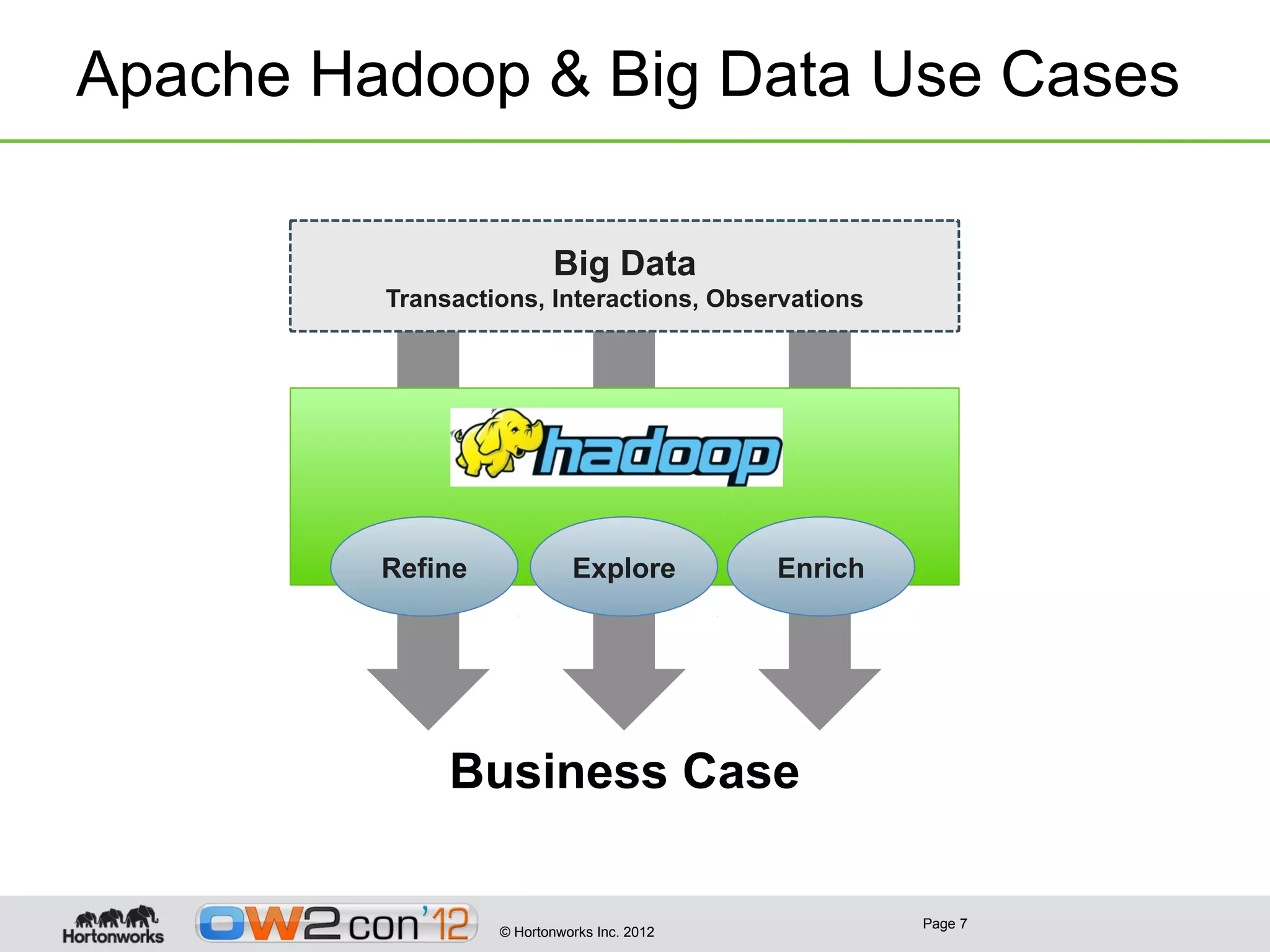
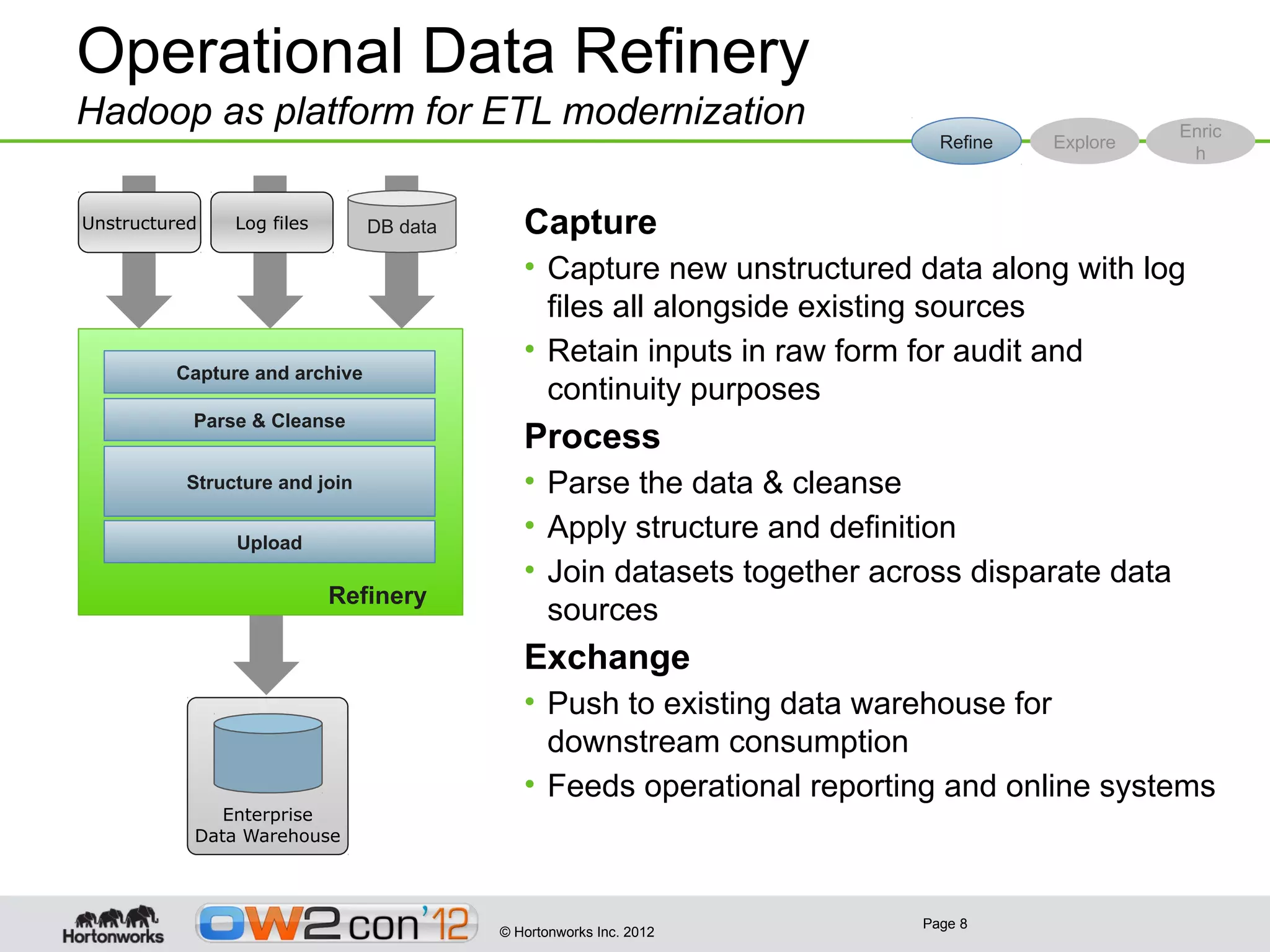
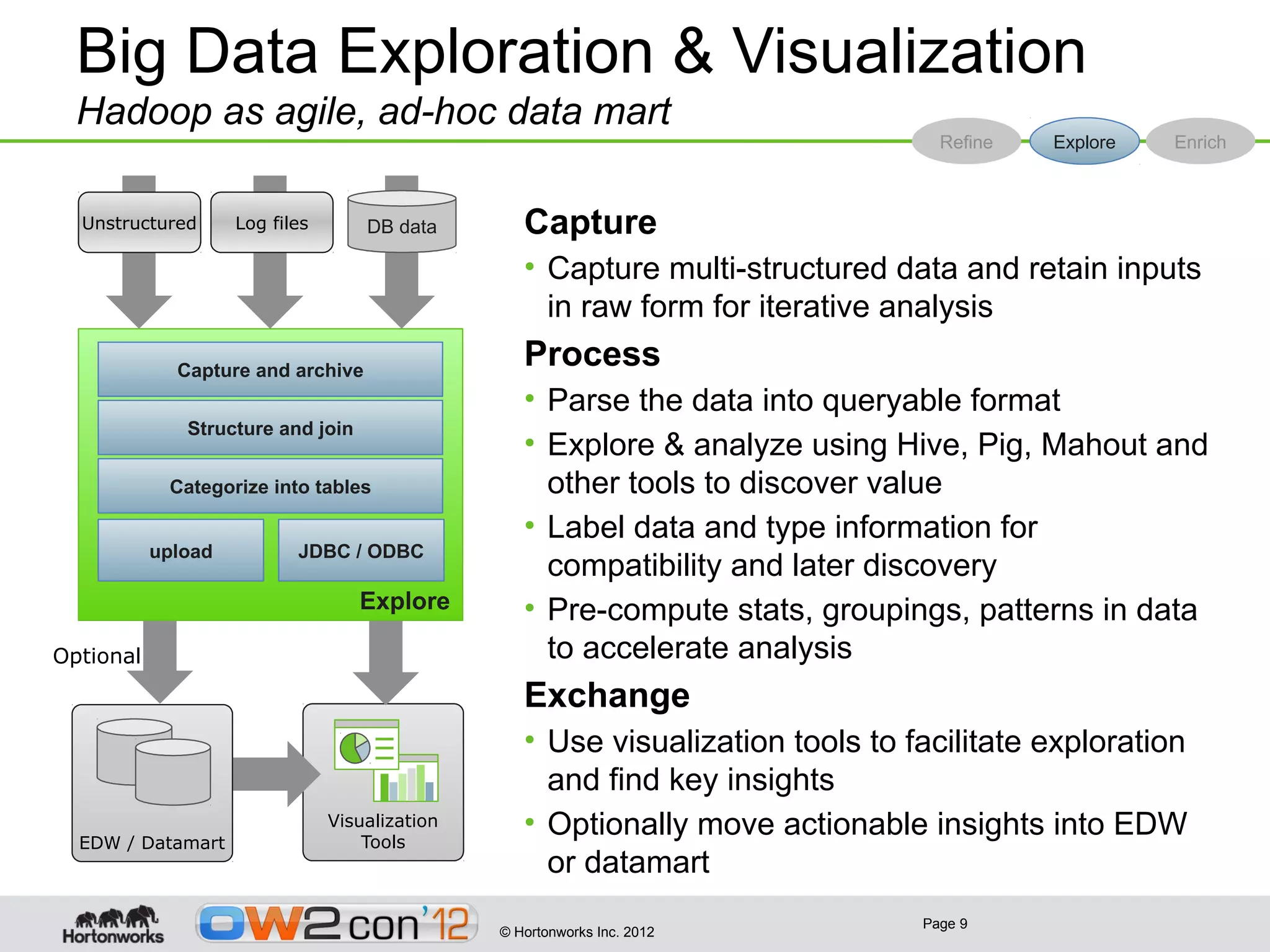
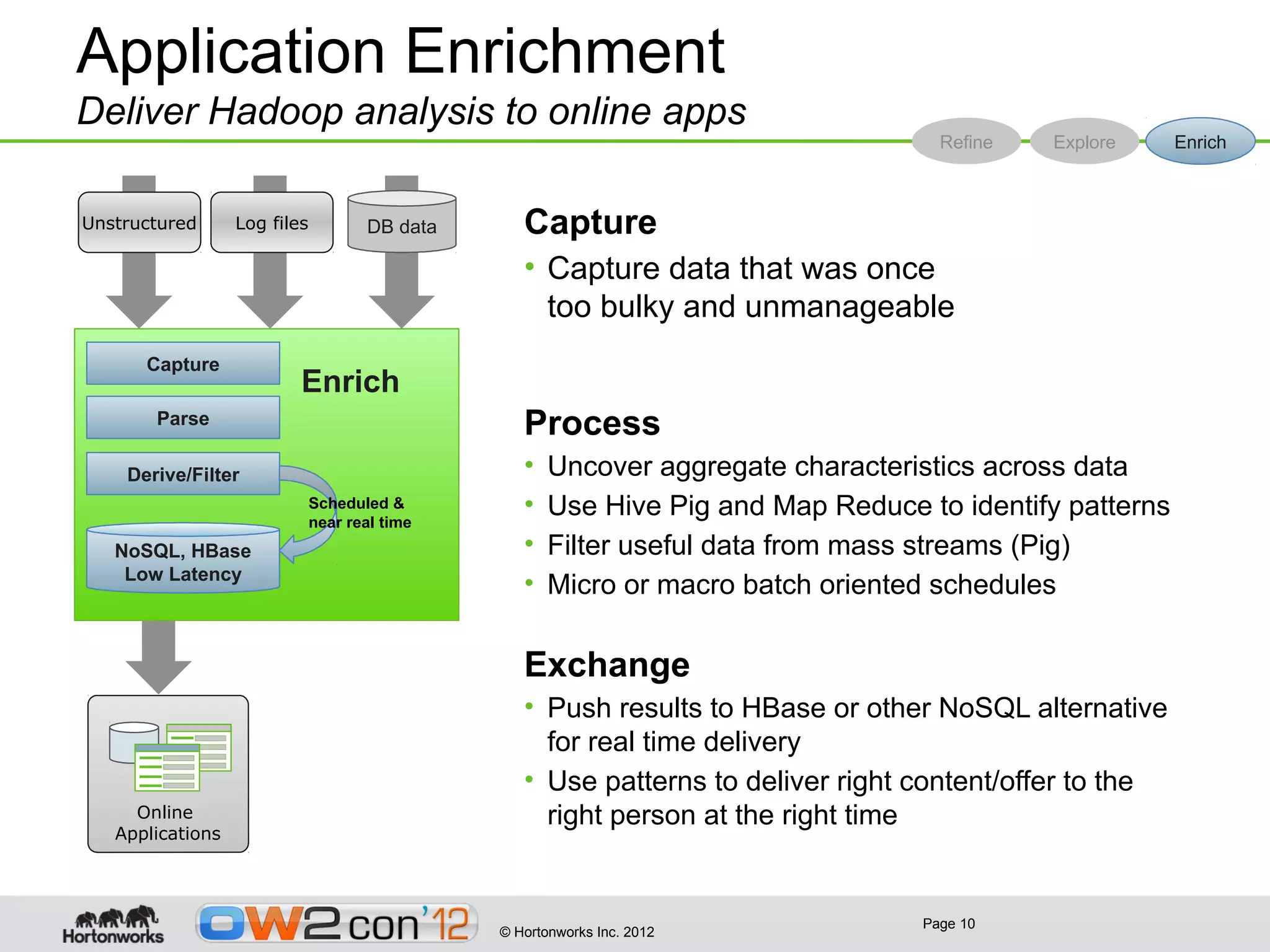
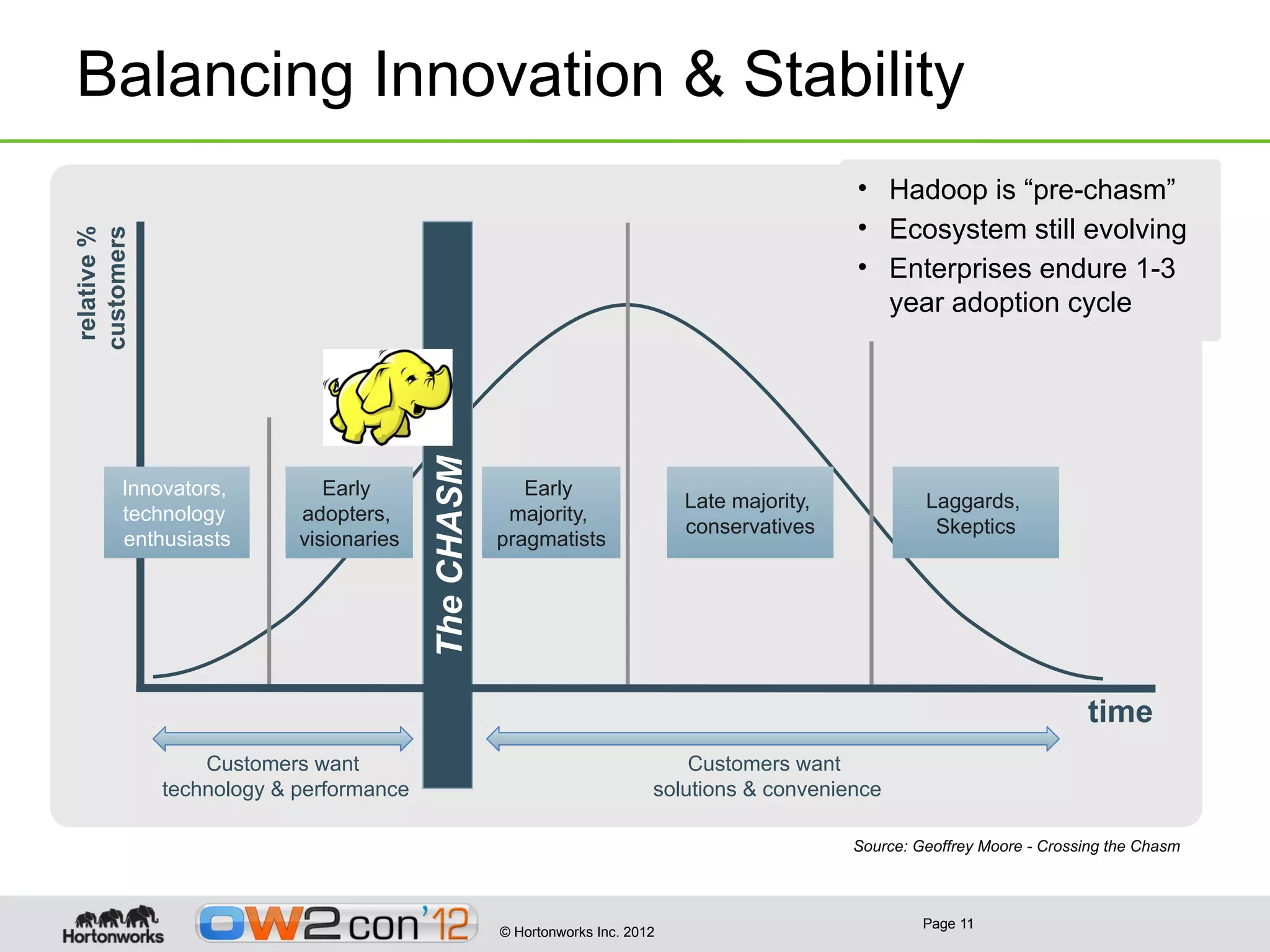



This document discusses big data and Hadoop. It provides an overview of what constitutes big data, how Hadoop works, and how organizations can use Hadoop and its ecosystem to gain insights from large and diverse data sources. Specific use cases discussed include using Hadoop for operational data refining, exploration and visualization of data, and enriching online applications. The document also outlines Hortonworks' strategy of focusing on Apache Hadoop to make it the enterprise big data platform and providing support services around their Hadoop distribution.





































![[2D1]Elasticsearch 성능 최적화](https://cdn.slidesharecdn.com/ss_thumbnails/2d1elasticsearch-140929192211-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)





































































