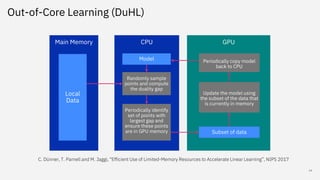
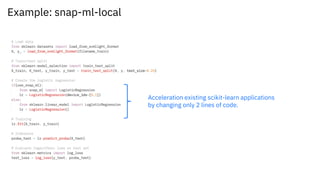
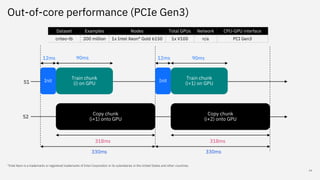
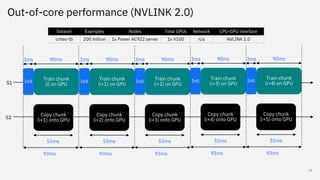
Snap ML is a machine learning framework for fast training of generalized linear models (GLMs) that can scale to large datasets. It uses multi-level parallelism across nodes and GPUs. Snap ML implementations include snap-ml-local for single nodes, snap-ml-mpi for multi-node HPC environments, and snap-ml-spark for Apache Spark clusters. Experimental results show Snap ML can train a logistic regression model on a 3TB Criteo dataset within 1.5 minutes using 16 GPUs.











![Each local sub-task
can be solved
effectively using
stochastic coordinate
descent (SCD).
[Shalev-Schwartz
2013]
Recently,
asynchronous variants
of SCD have been
proposed to run on
multi-core CPUs.
[Liu 2013]
[Tran 2015]
[Hsiesh 2015]
Twice parallel asynchronous SCD (TPA-SCD) is a
another recent variant designed to run on GPUs.
It assigns each coordinate update to a different
block of threads that executed asynchronously.
Within each thread block, the coordinate update is
computed using many tightly coupled threads.
GPU Acceleration
13
Local Model
T. Parnell, C. Dünner, K. Atasu, M. Sifalakis and H. Pozidis, "Large-
scale stochastic learning using GPUs”, ParLearning 2017](https://image.slidesharecdn.com/bsc-presentation-snapml-public-180620082614/85/SNAP-MACHINE-LEARNING-13-320.jpg)