Download as PDF, PPTX














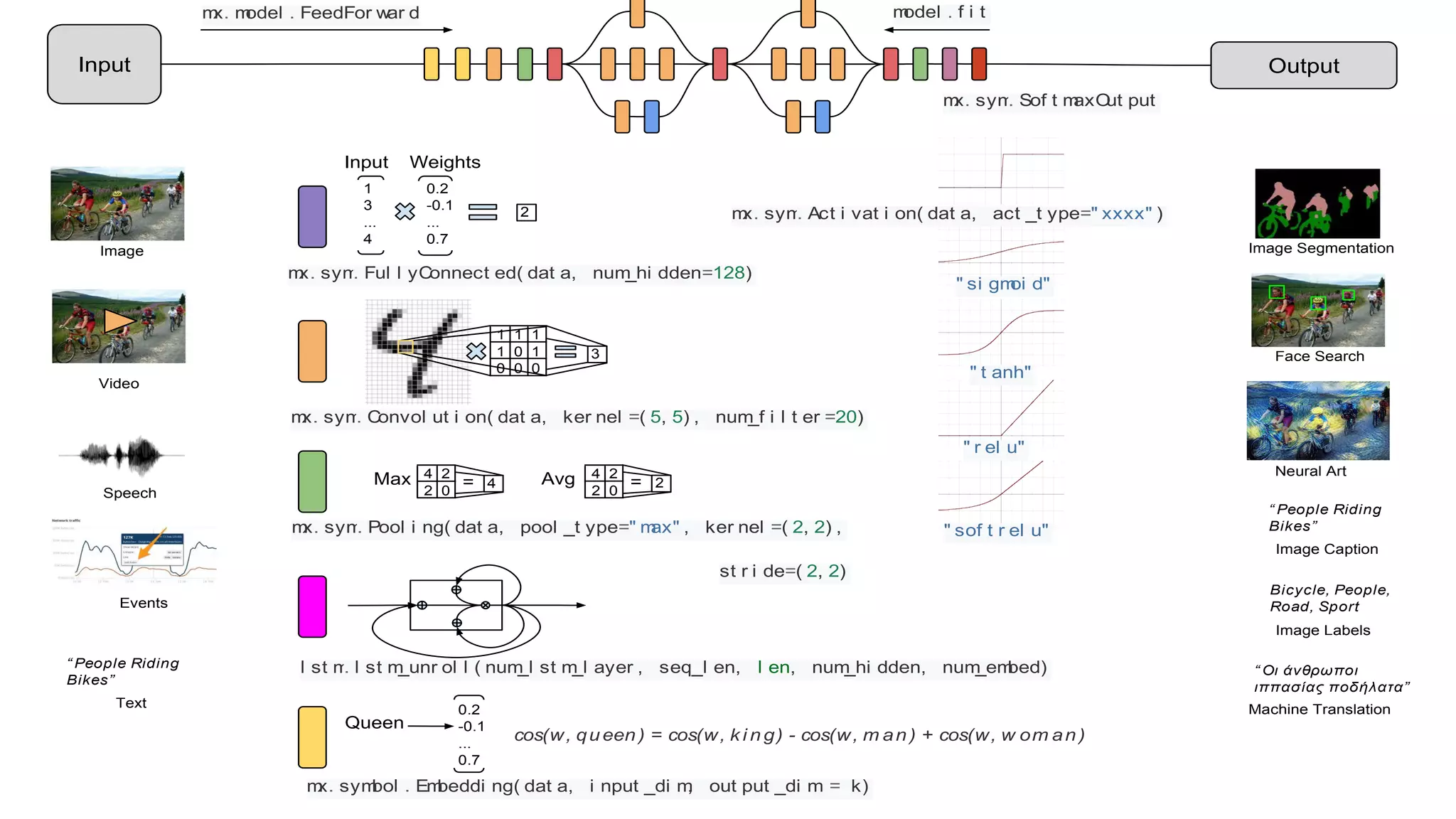



![Gluon CV: classification, detection, segmentation
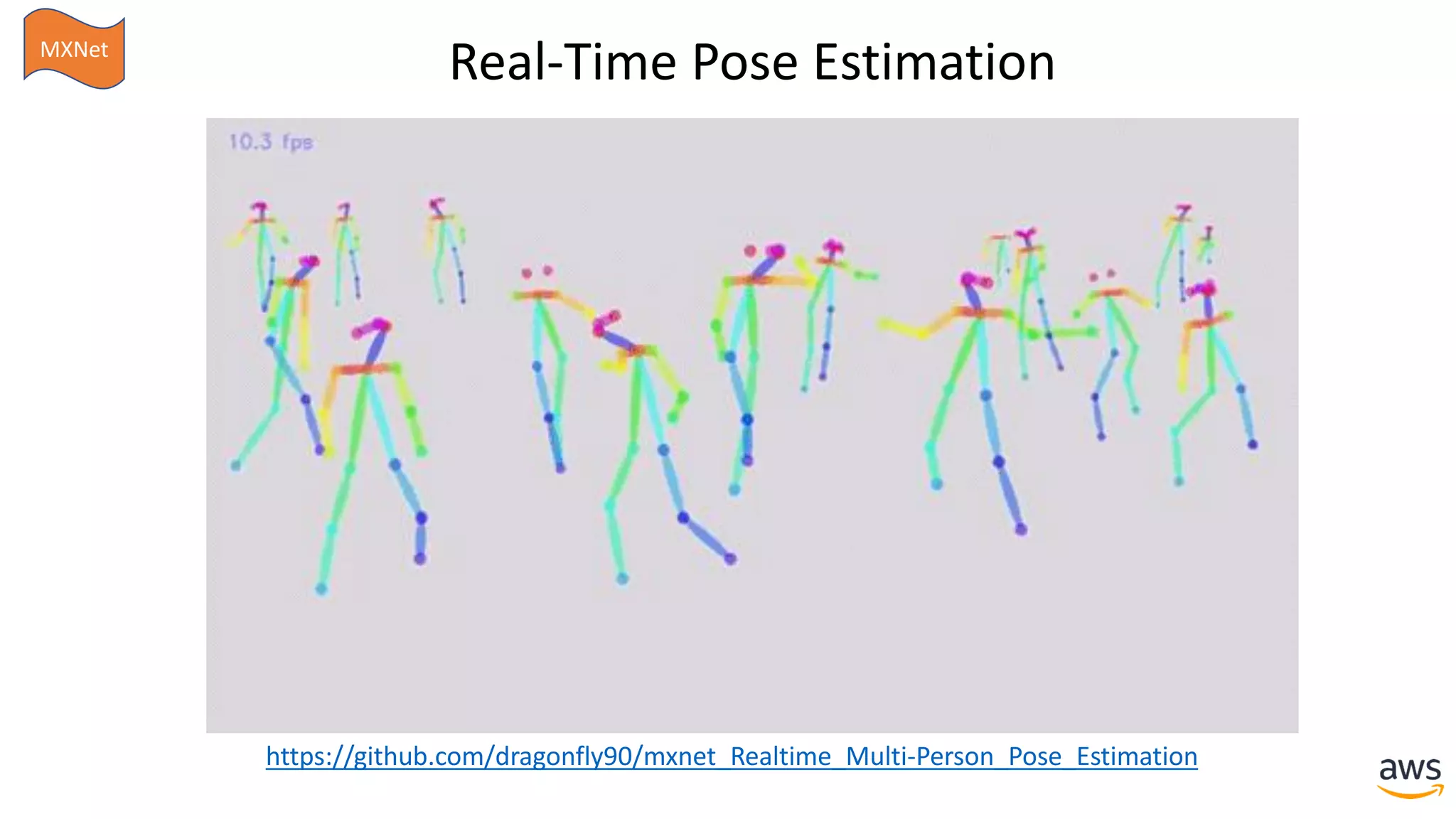
https://github.com/dmlc/gluon-cv
[electric_guitar],
with probability 0.671](https://image.slidesharecdn.com/20180606berlinsummit-180606151740/75/Deep-Dive-on-Deep-Learning-June-2018-35-2048.jpg)




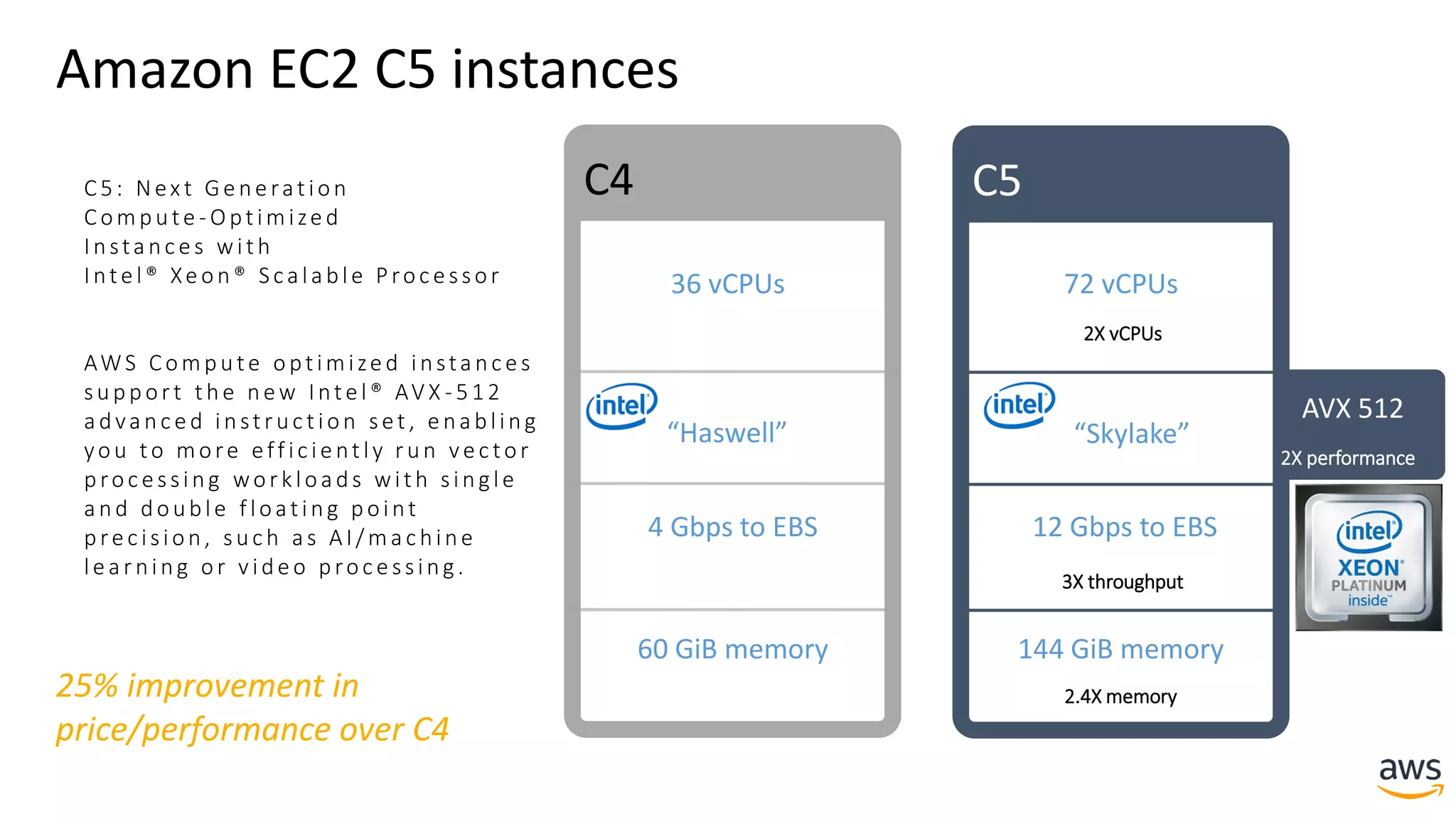
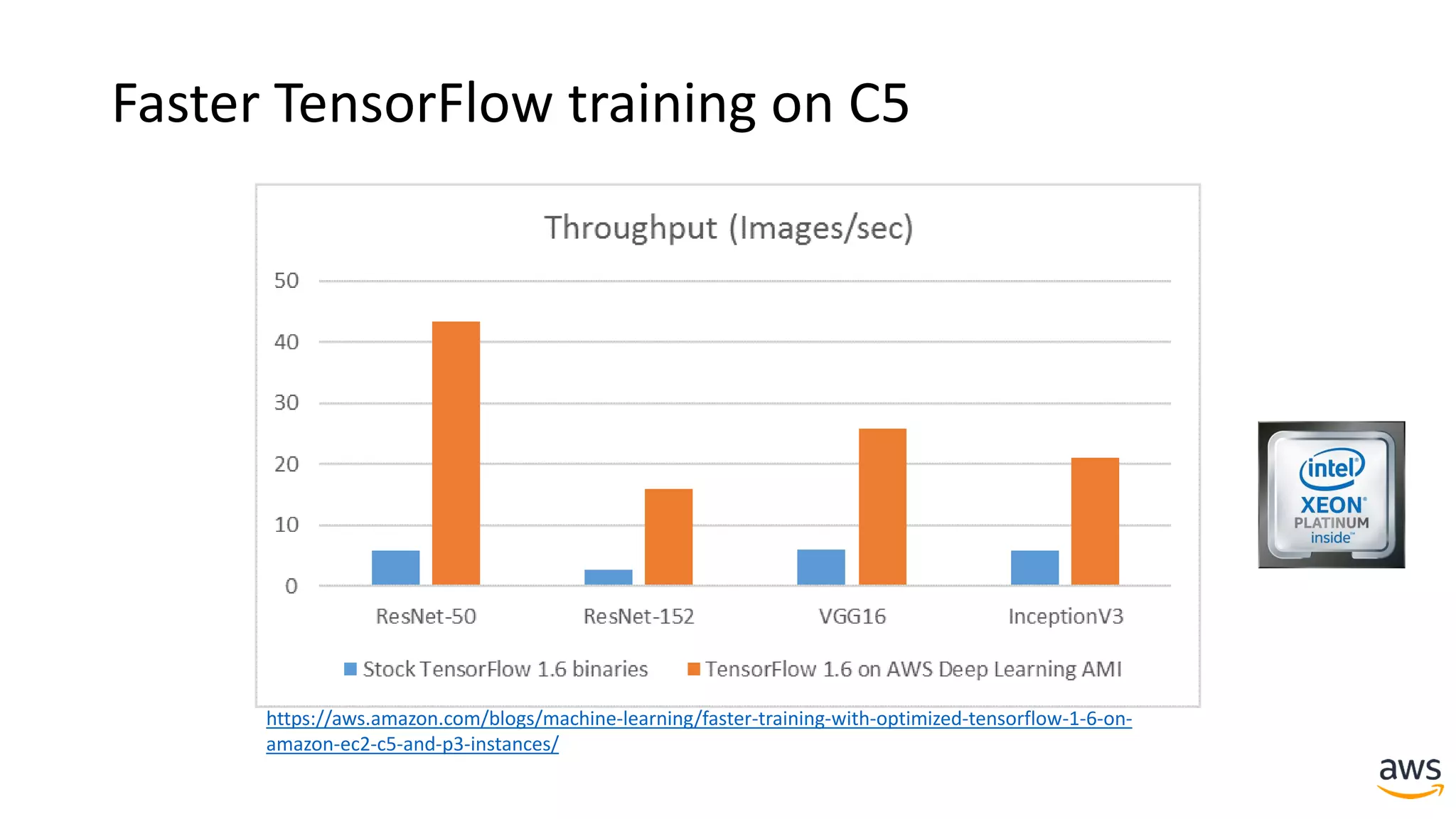


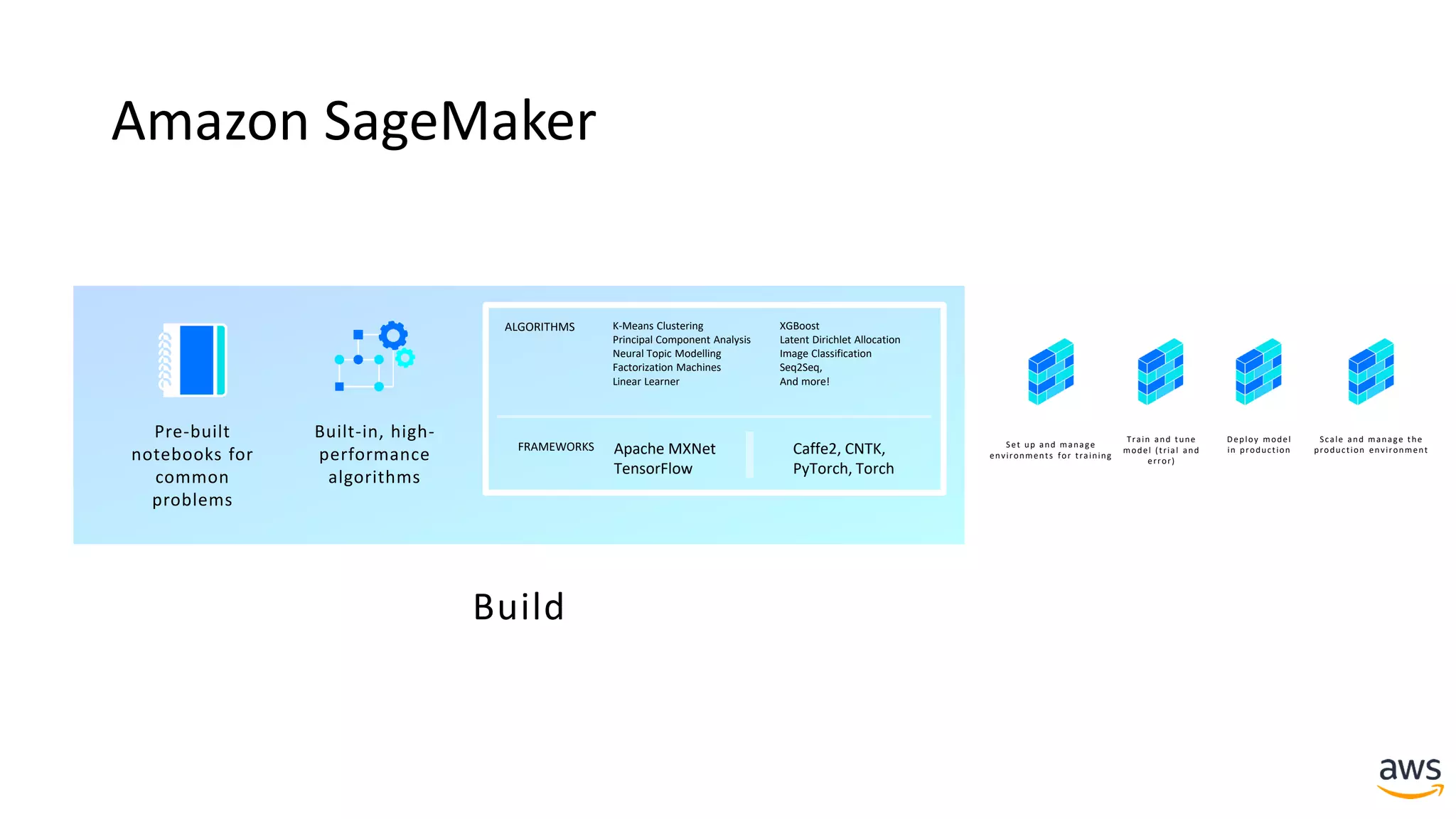
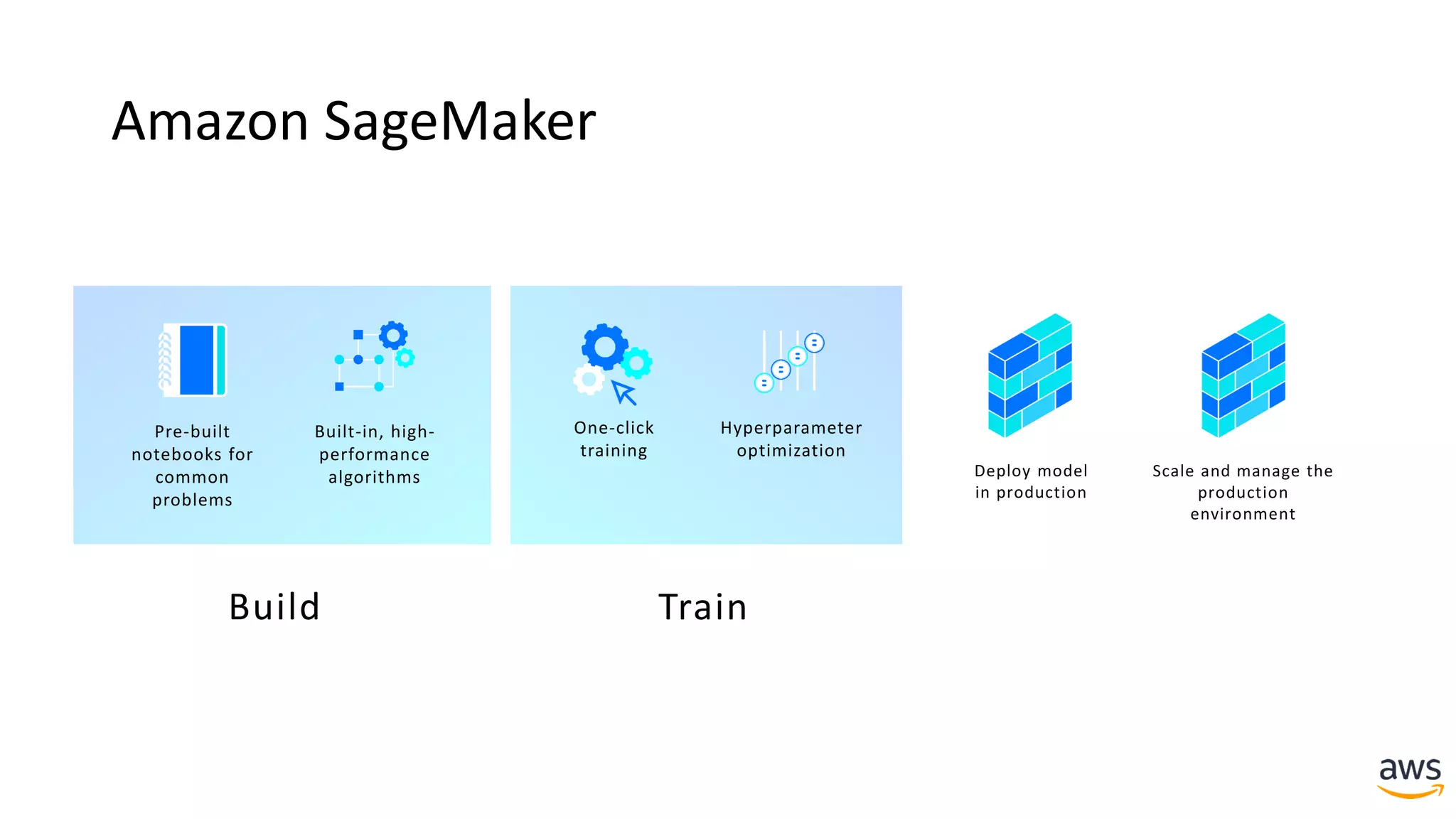
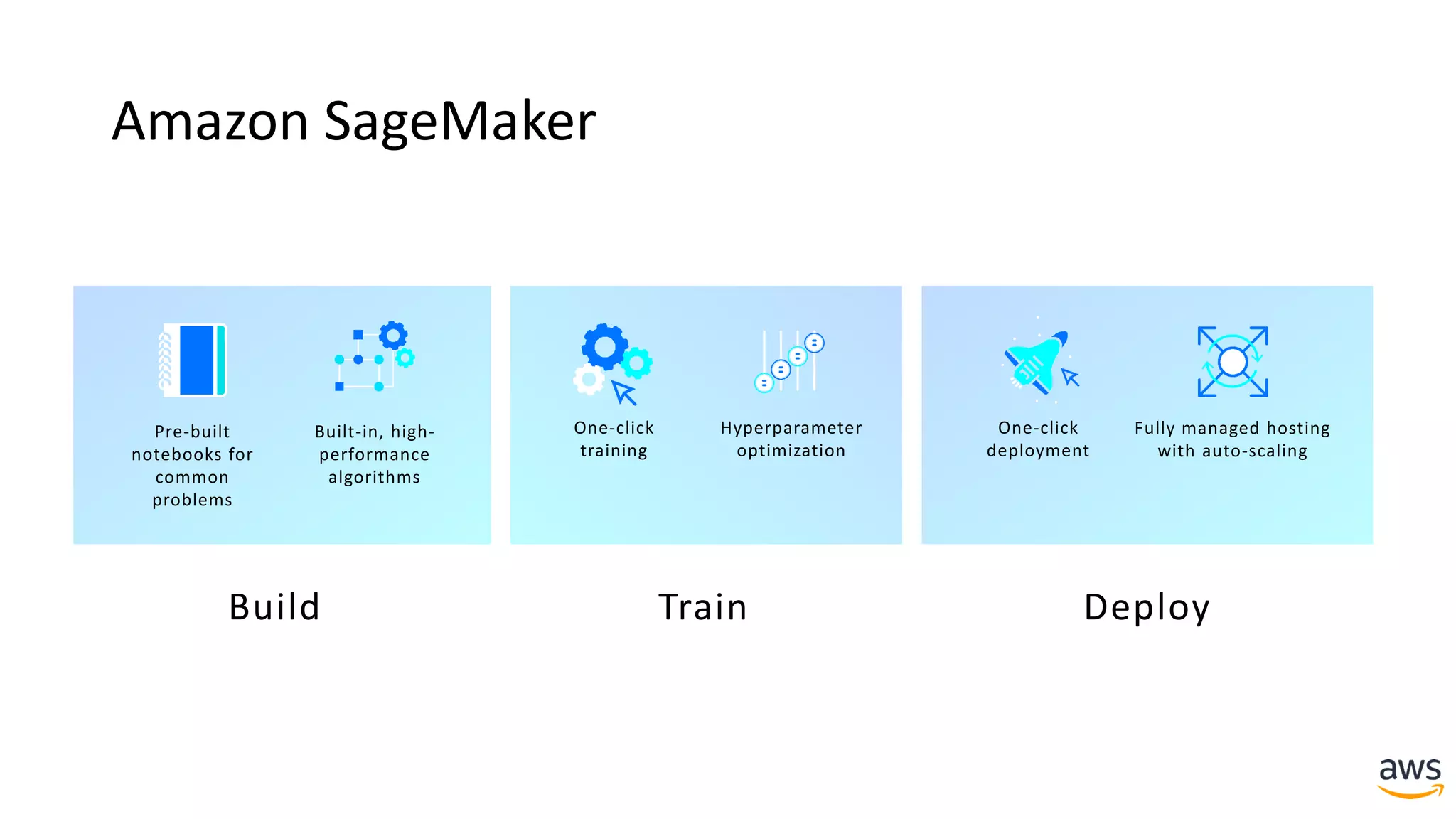
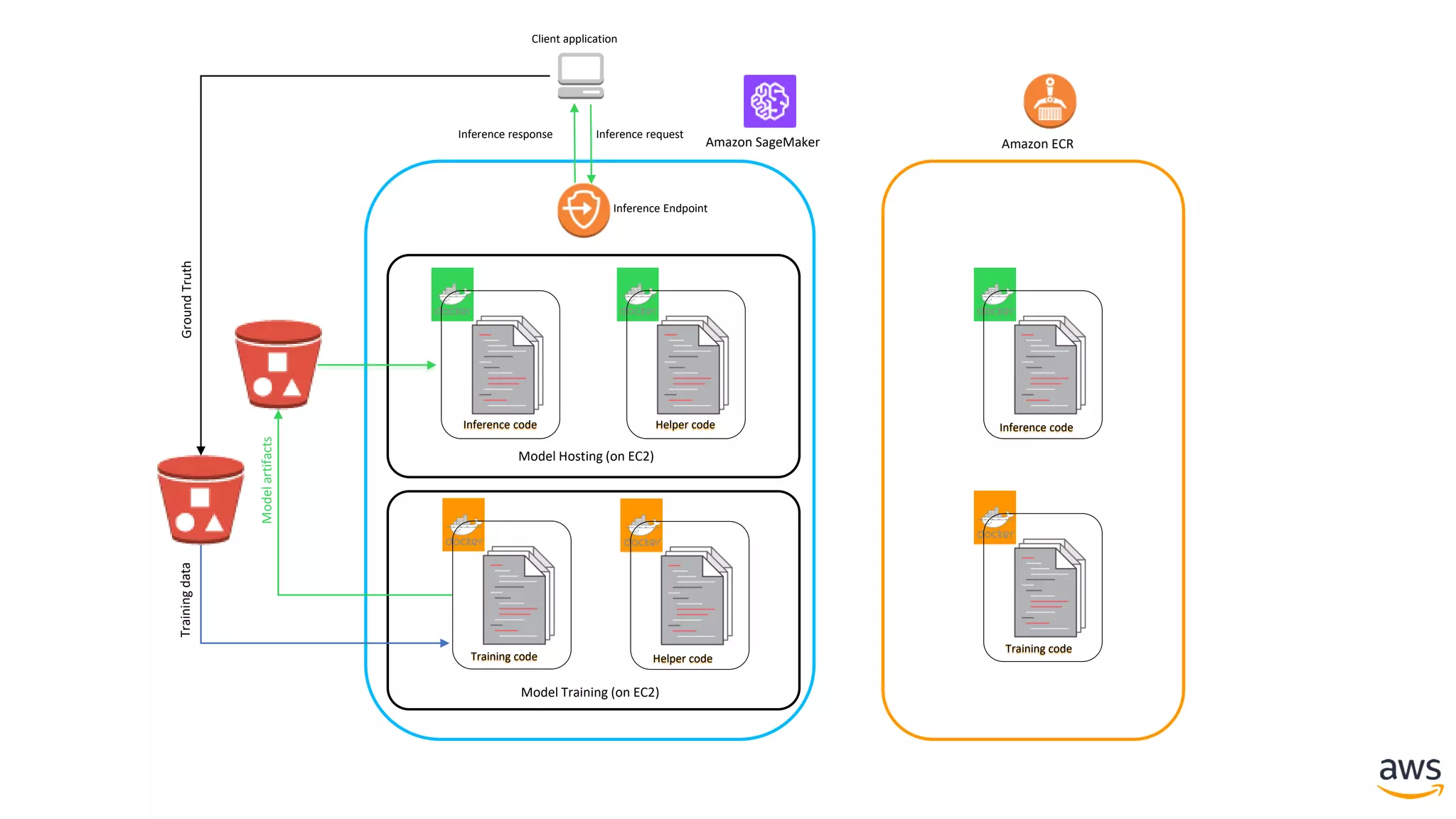




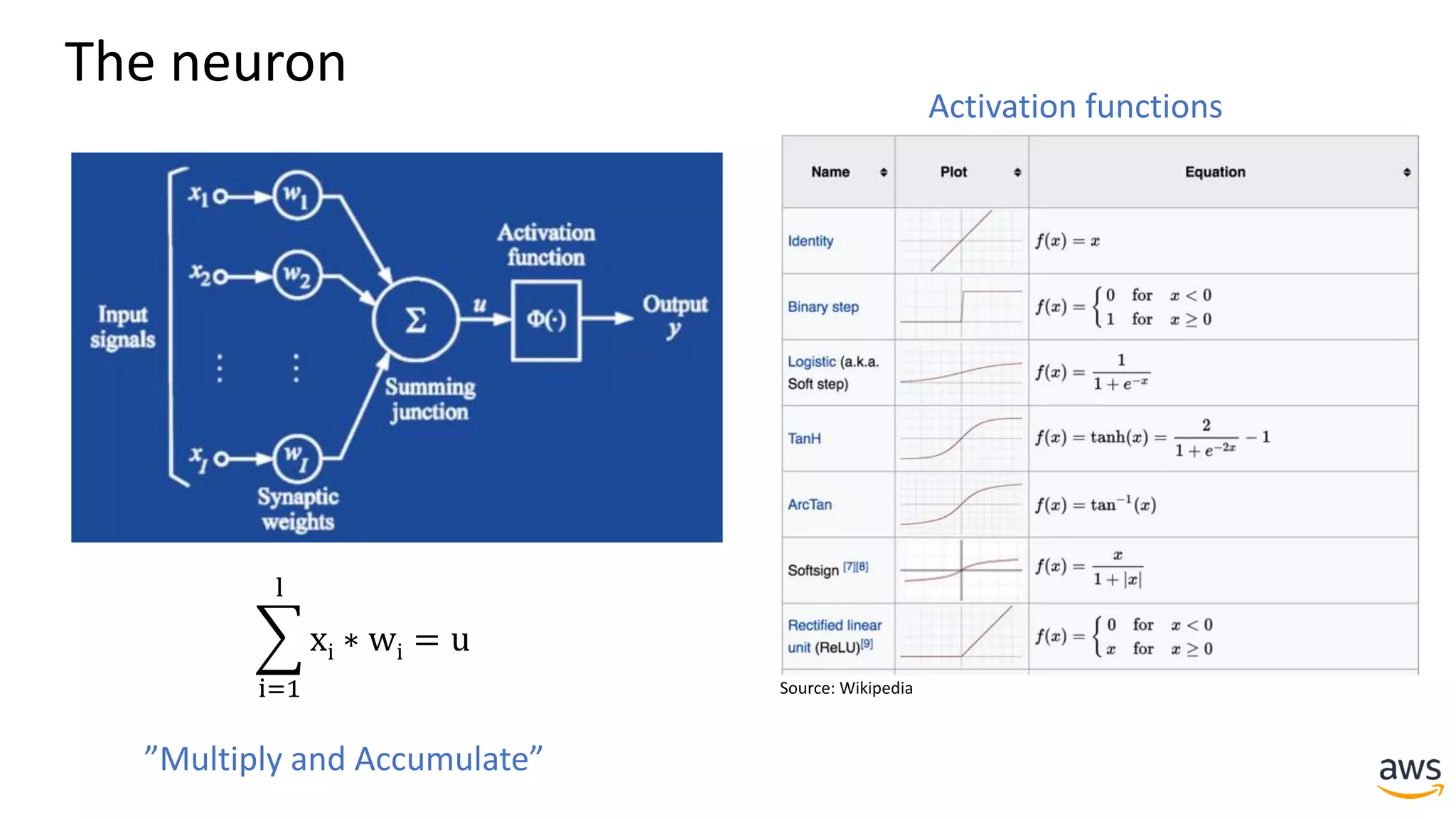
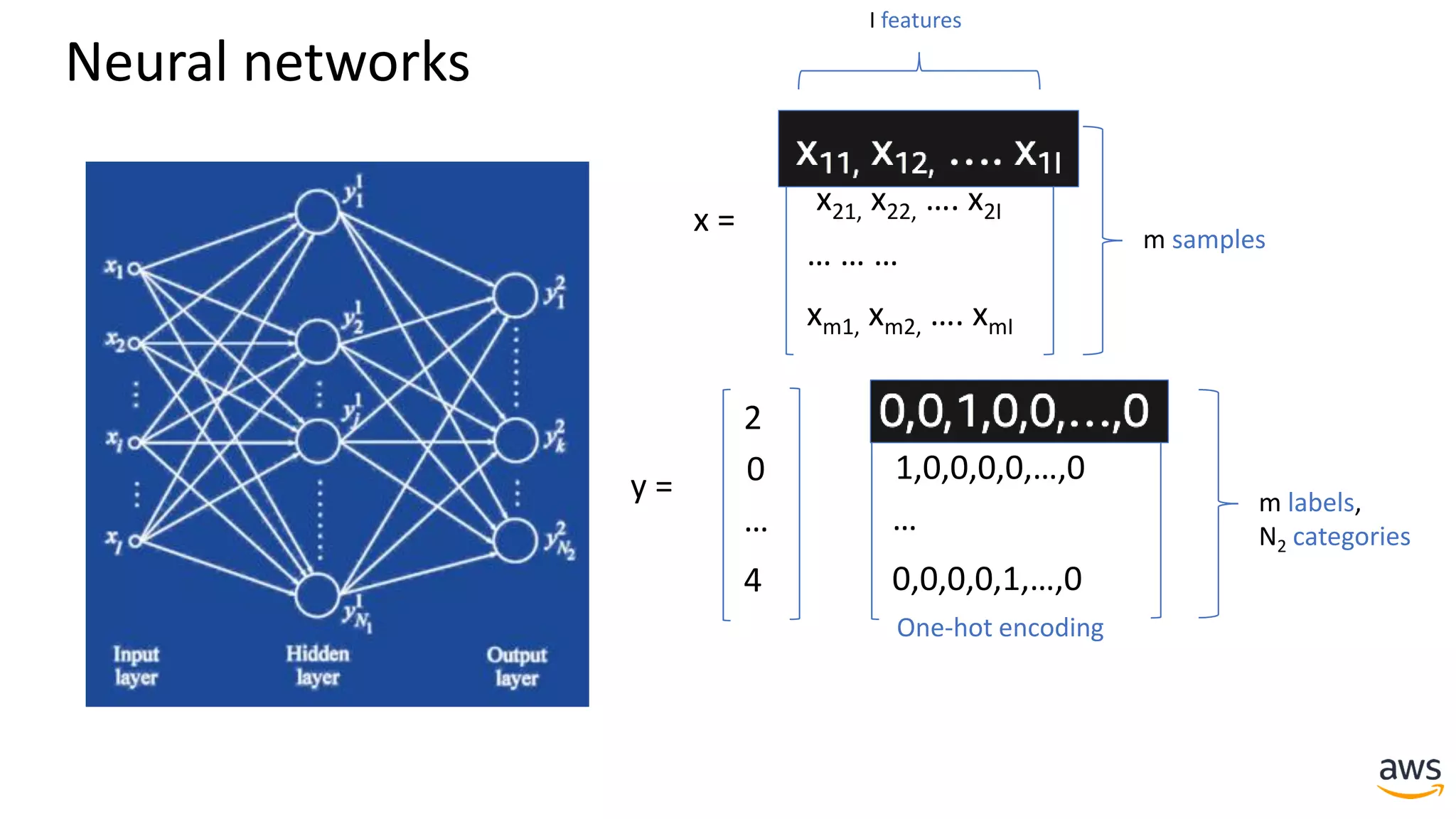
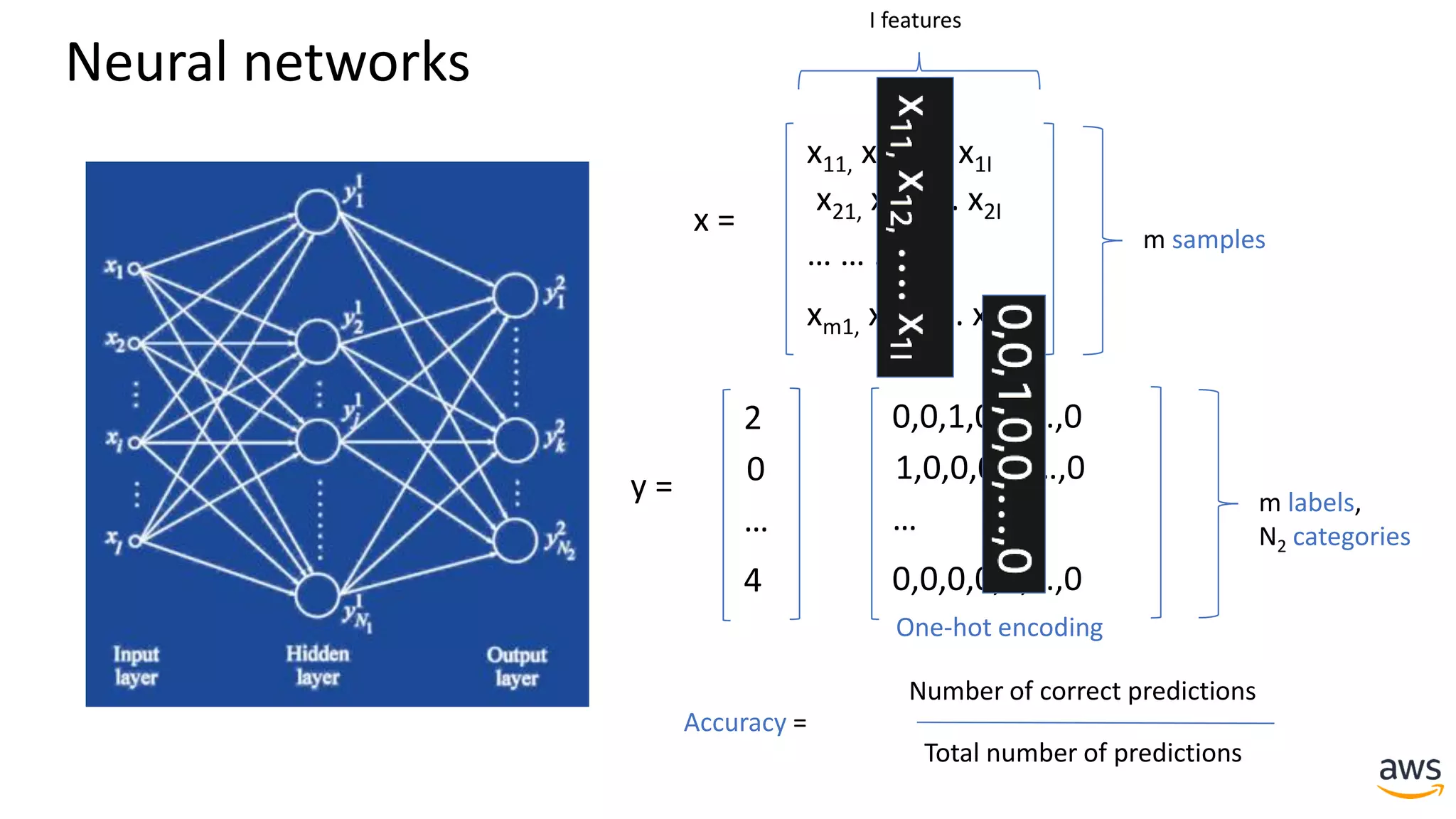
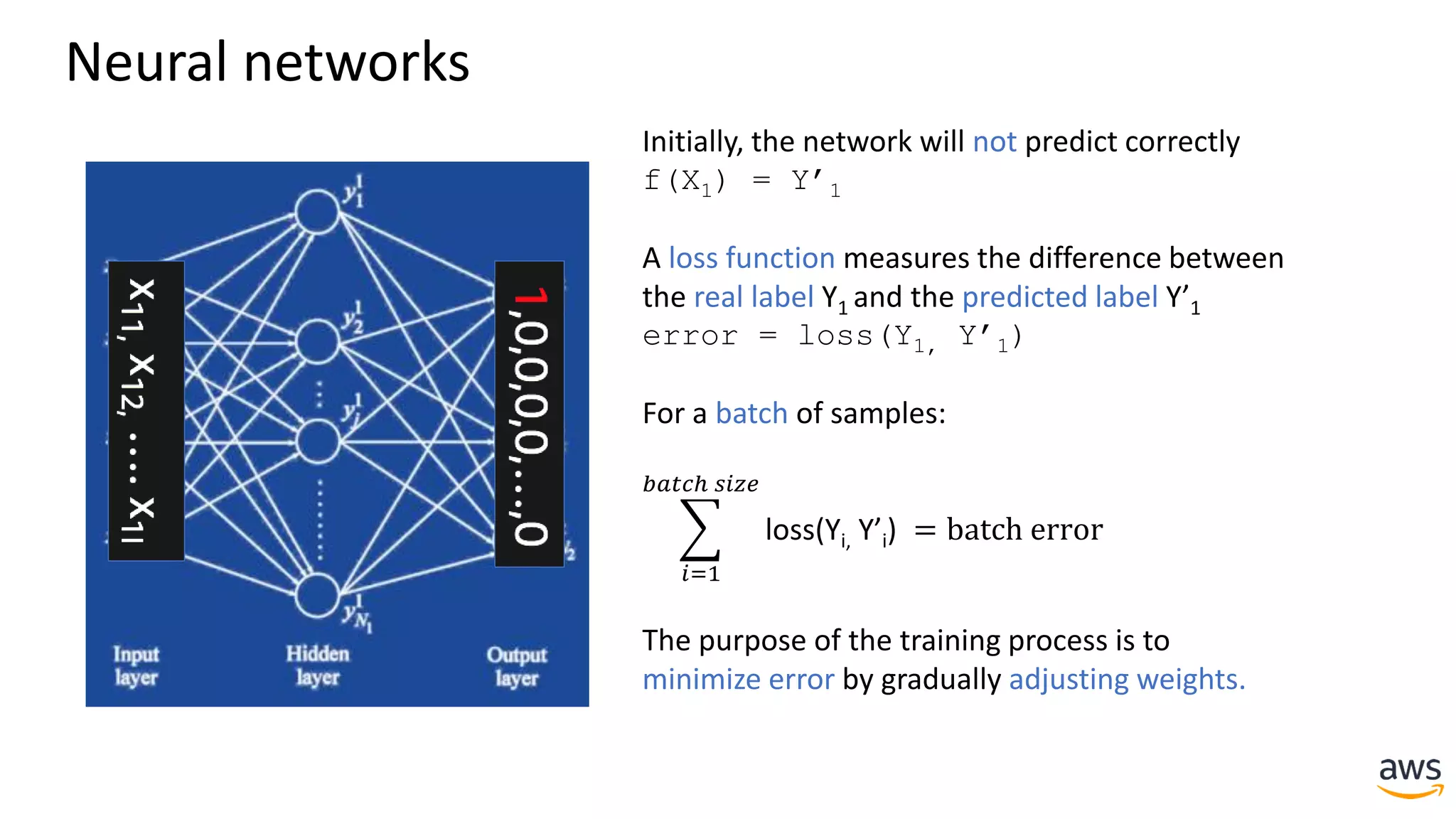
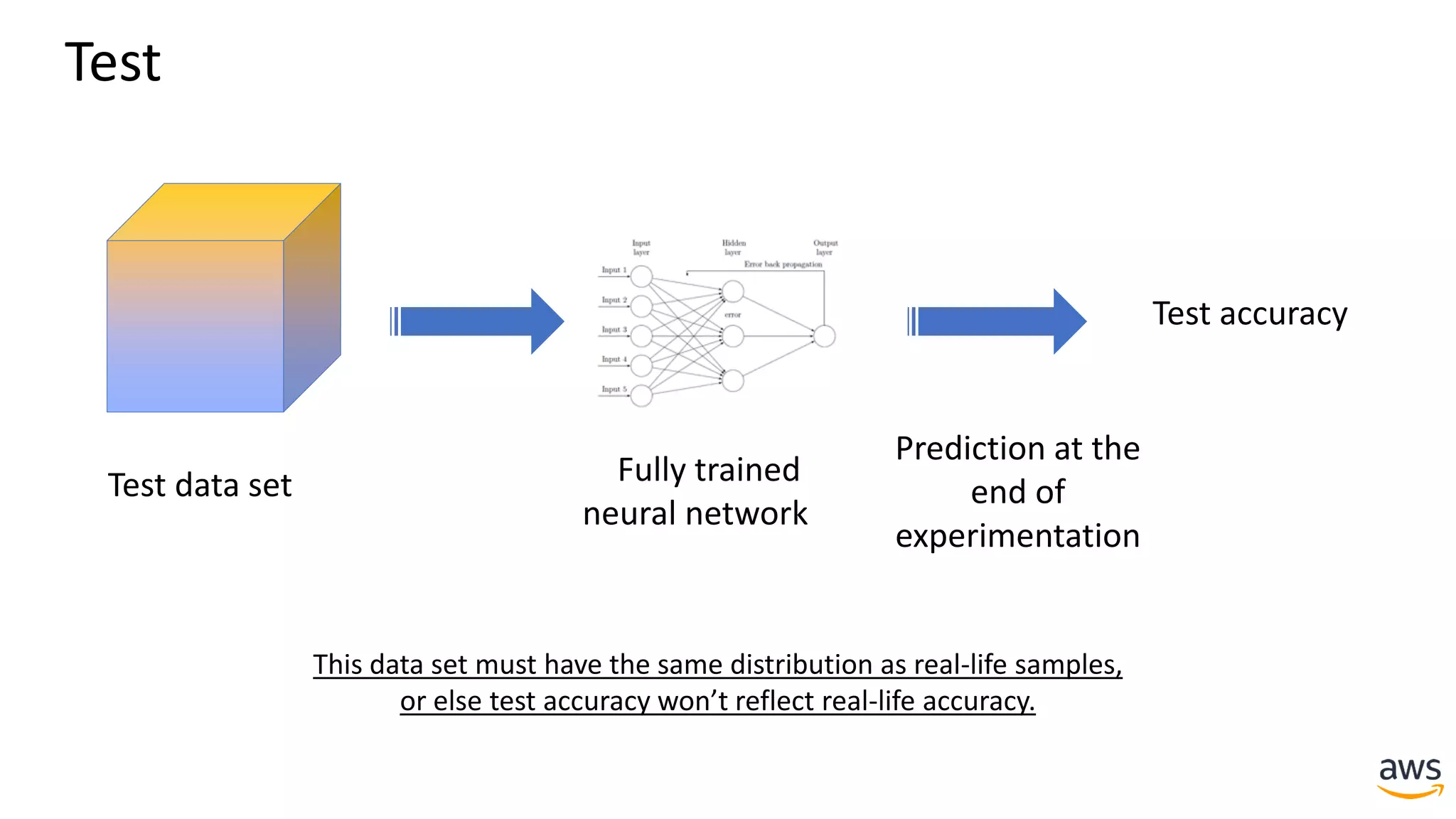
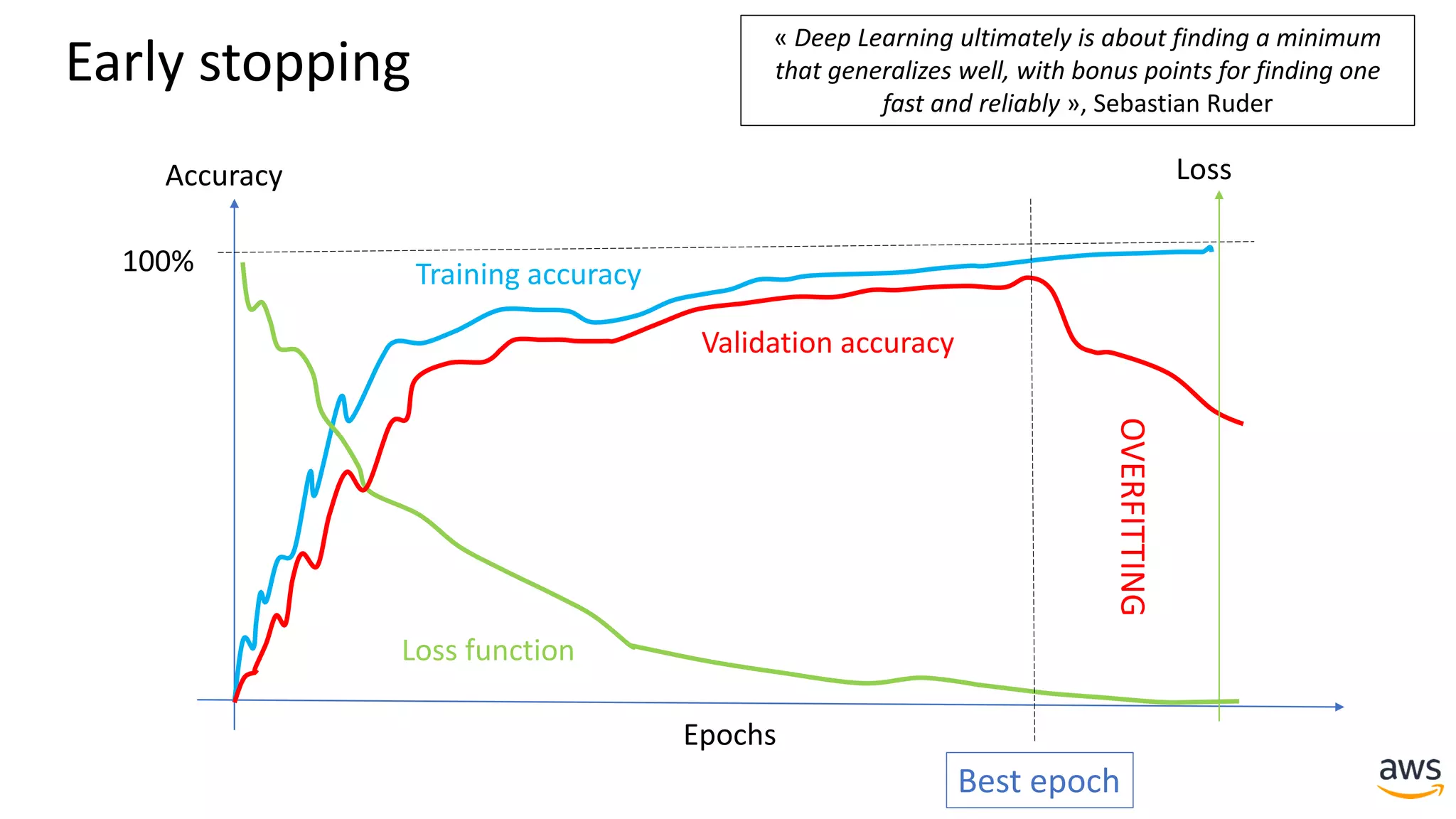
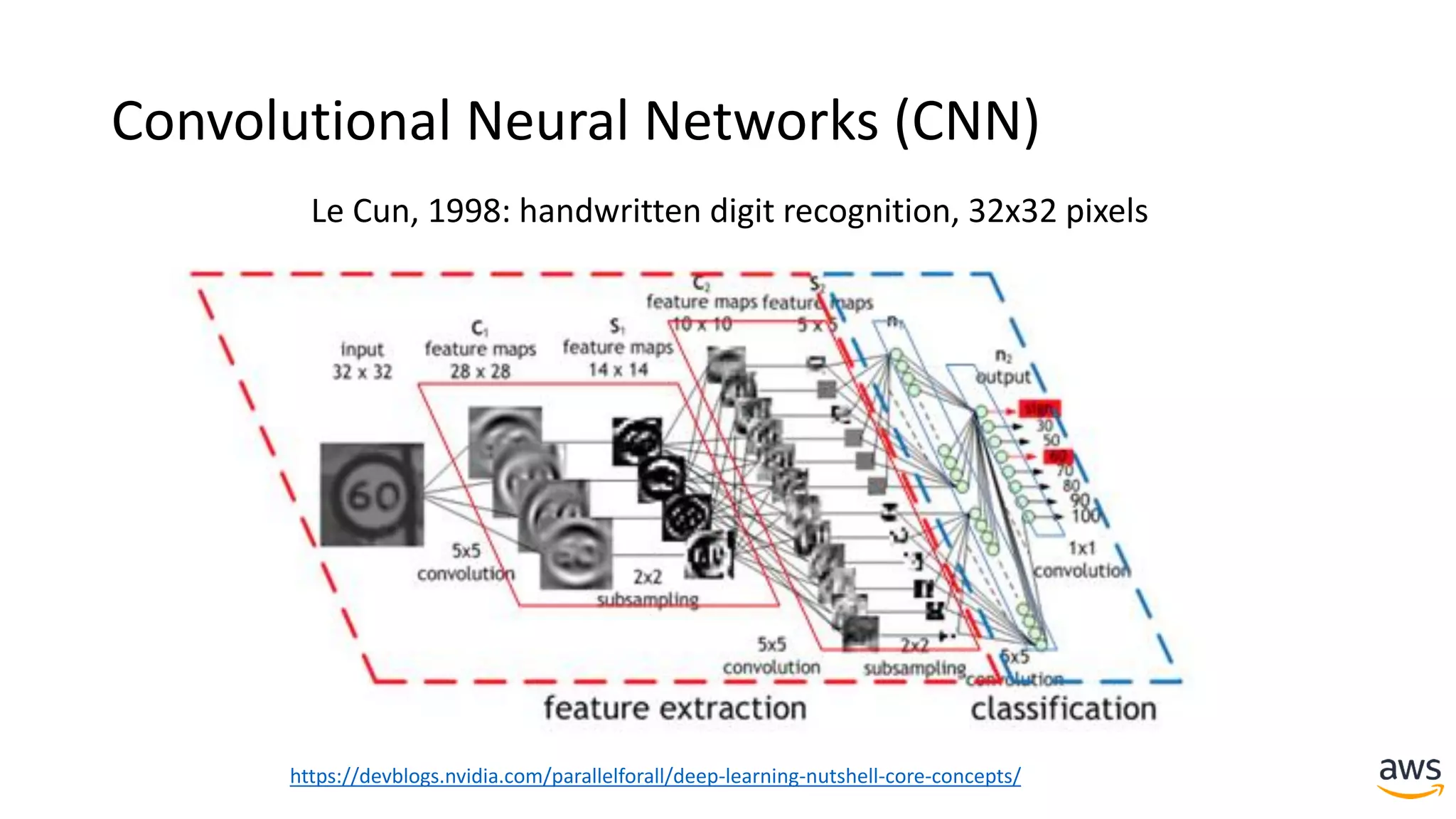
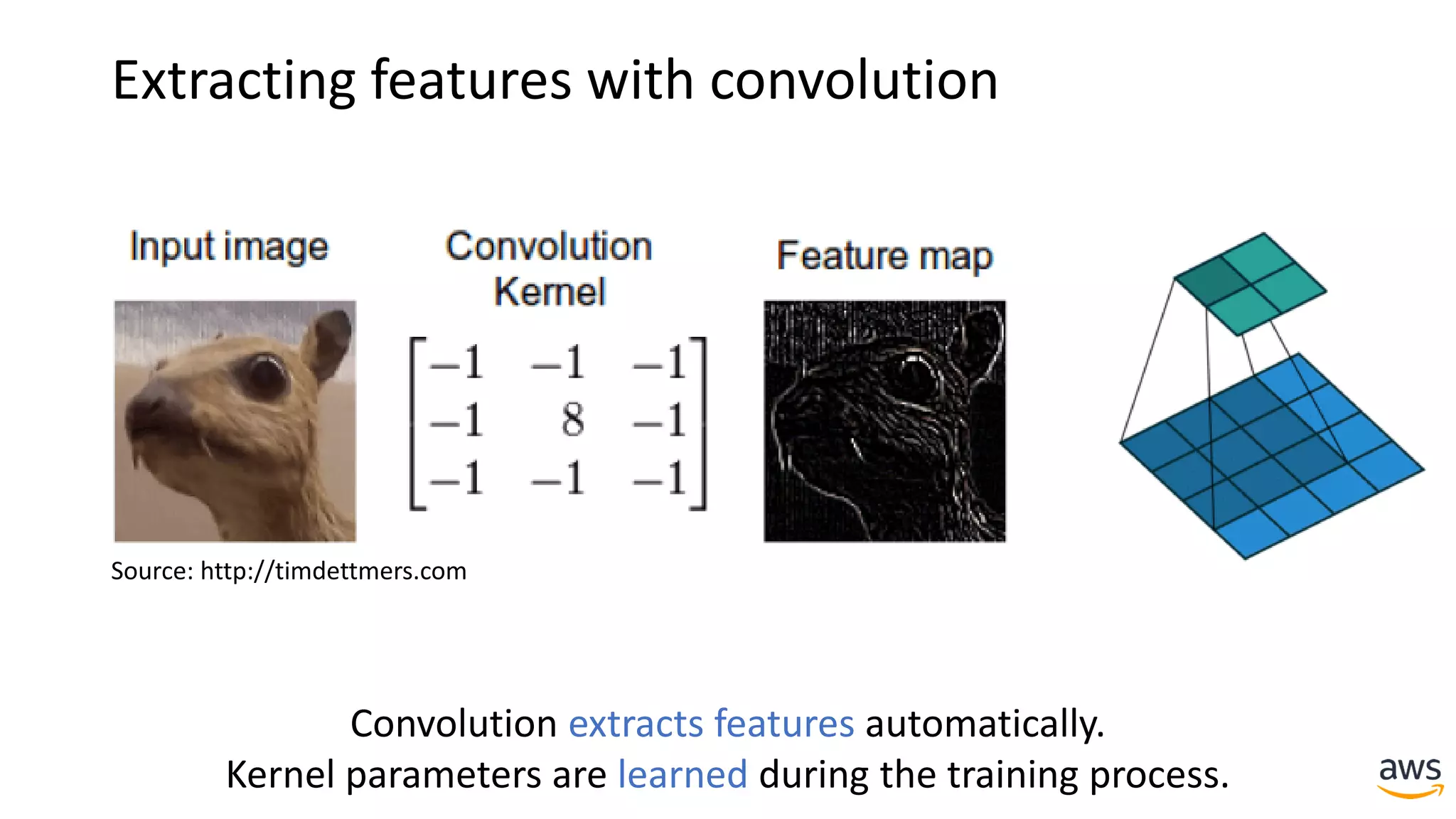
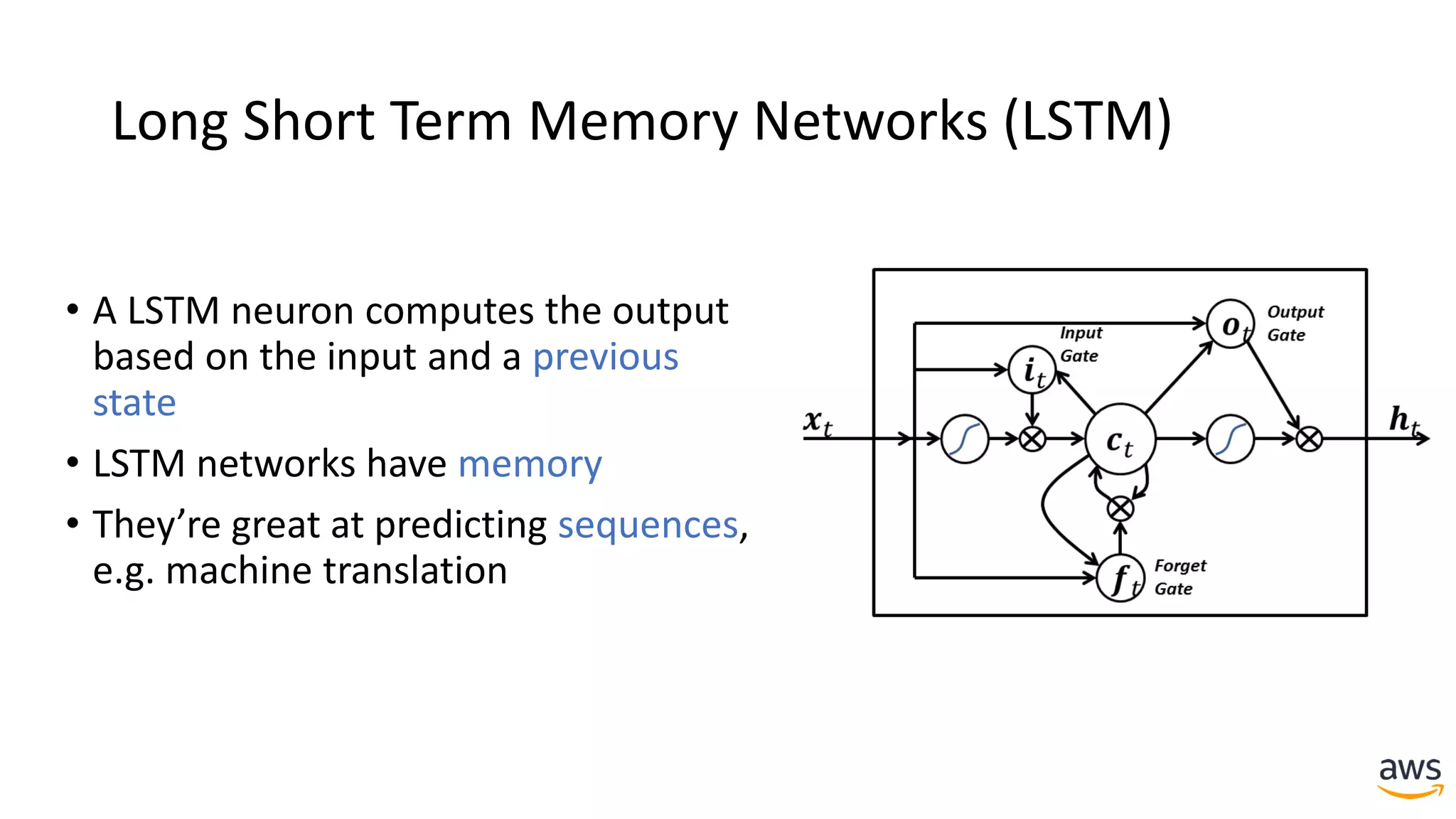
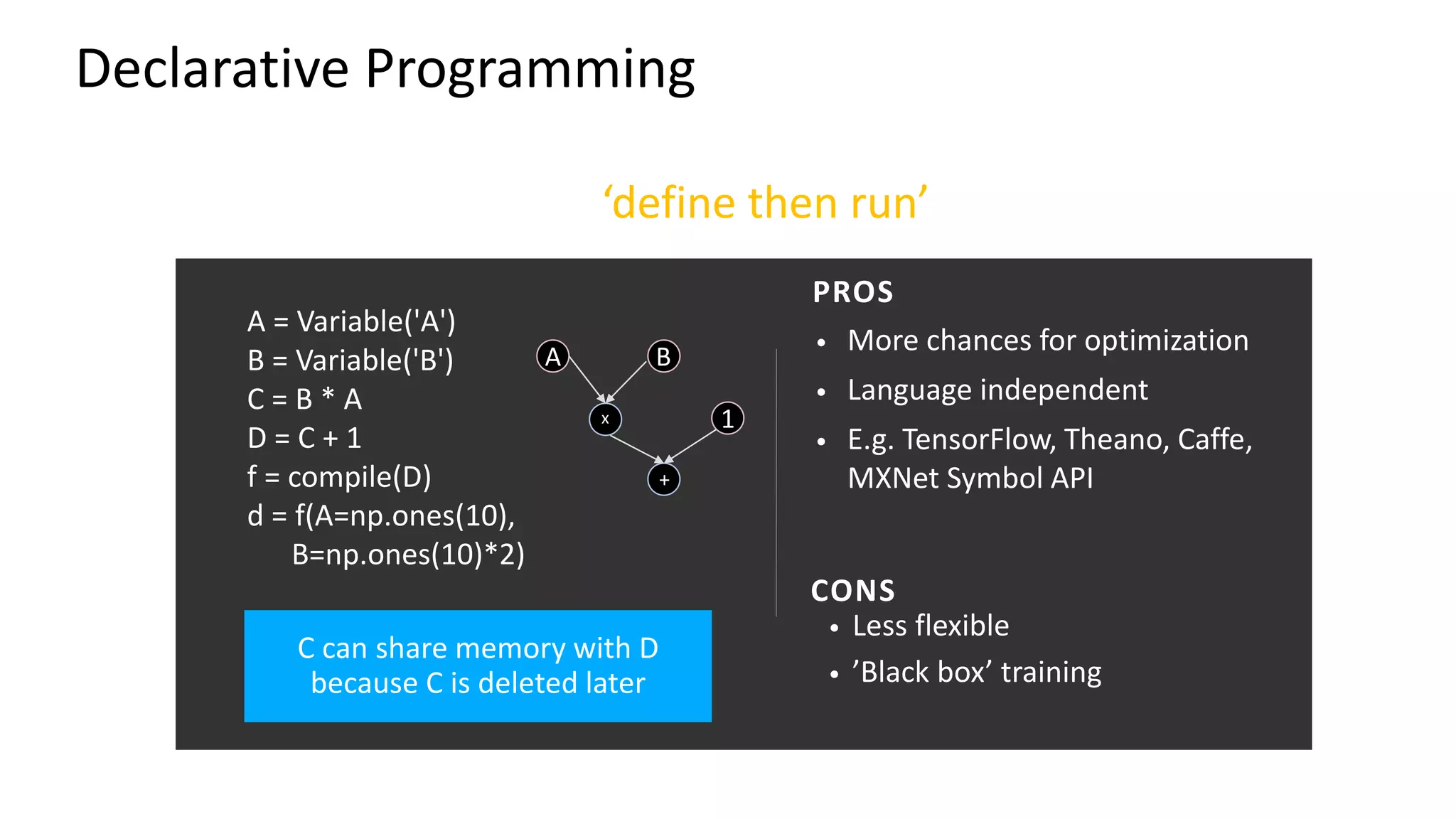
This document provides a summary of a presentation on deep learning concepts, common architectures, Apache MXNet, and infrastructure for deep learning. The agenda includes an overview of deep learning concepts like neural networks and training, common architectures like convolutional neural networks and LSTMs, a demonstration of Apache MXNet's symbolic and imperative APIs, and a discussion of infrastructure for deep learning on AWS like optimized EC2 instances and Amazon SageMaker.







































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)




![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)








