Downloaded 29 times








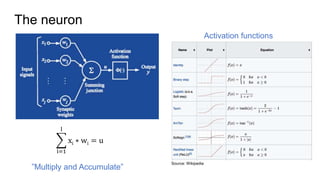
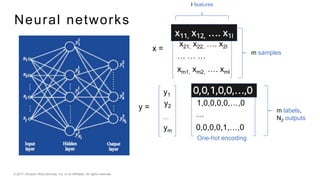
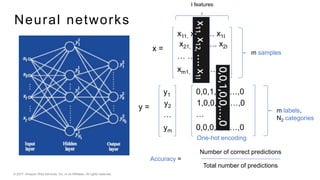

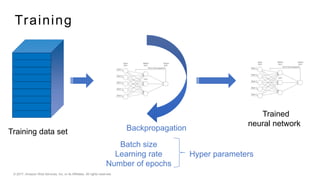

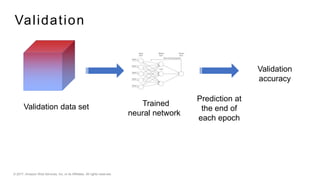
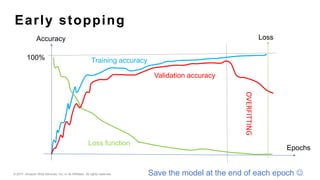

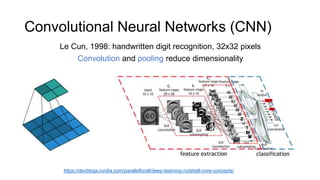
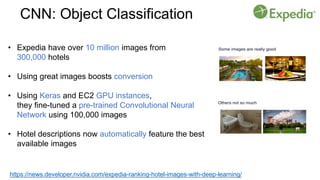




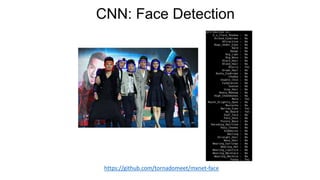
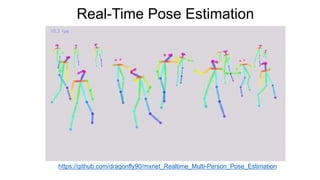
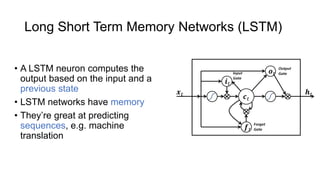





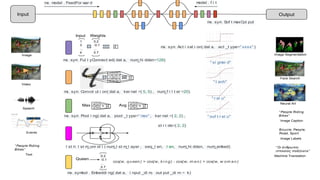



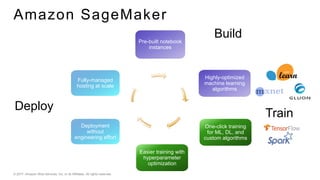



This document provides an introduction to deep learning and neural networks. It discusses key concepts like artificial intelligence, machine learning, deep learning and common network architectures. It also introduces Apache MXNet and demos using Jupyter notebooks on Amazon SageMaker. Deep learning uses neural networks to teach machines from complex data without explicit programming. Common network types discussed are convolutional neural networks, long short-term memory networks and generative adversarial networks. MXNet is an open source deep learning library that programs and scales models across GPUs. Demos show classifying images and generating digits with neural networks.

















![[AWS Dev Day] 인공지능 / 기계 학습 | 개발자를 위한 수백만 사용자 대상 기계 학습 서비스 확장 하기 - 윤석찬 AWS 수석테...](https://cdn.slidesharecdn.com/ss_thumbnails/scalableawsmlservicefromzerotomillions-190927015651-thumbnail.jpg?width=640&height=640&fit=bounds)
































































