Download as PDF, PPTX









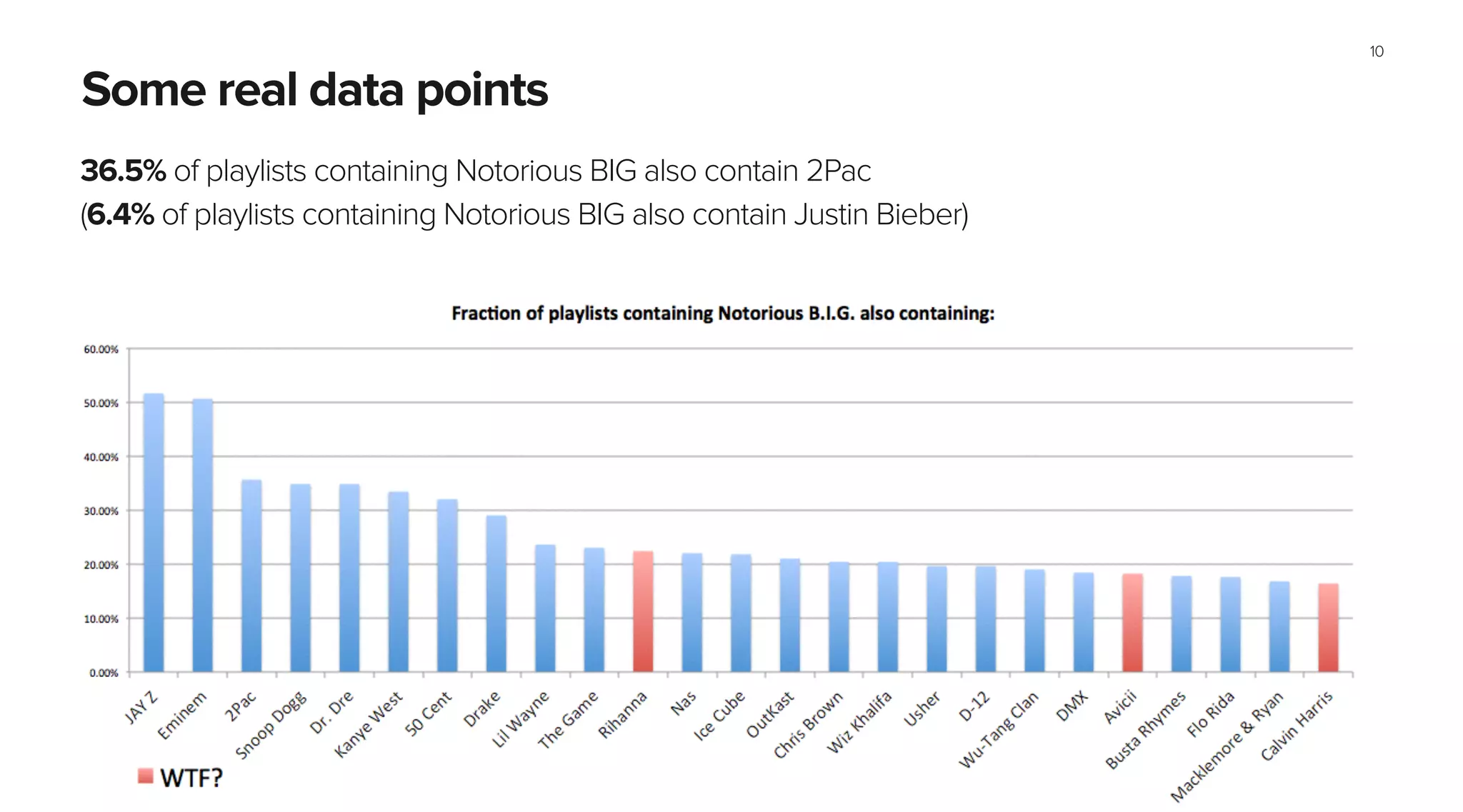




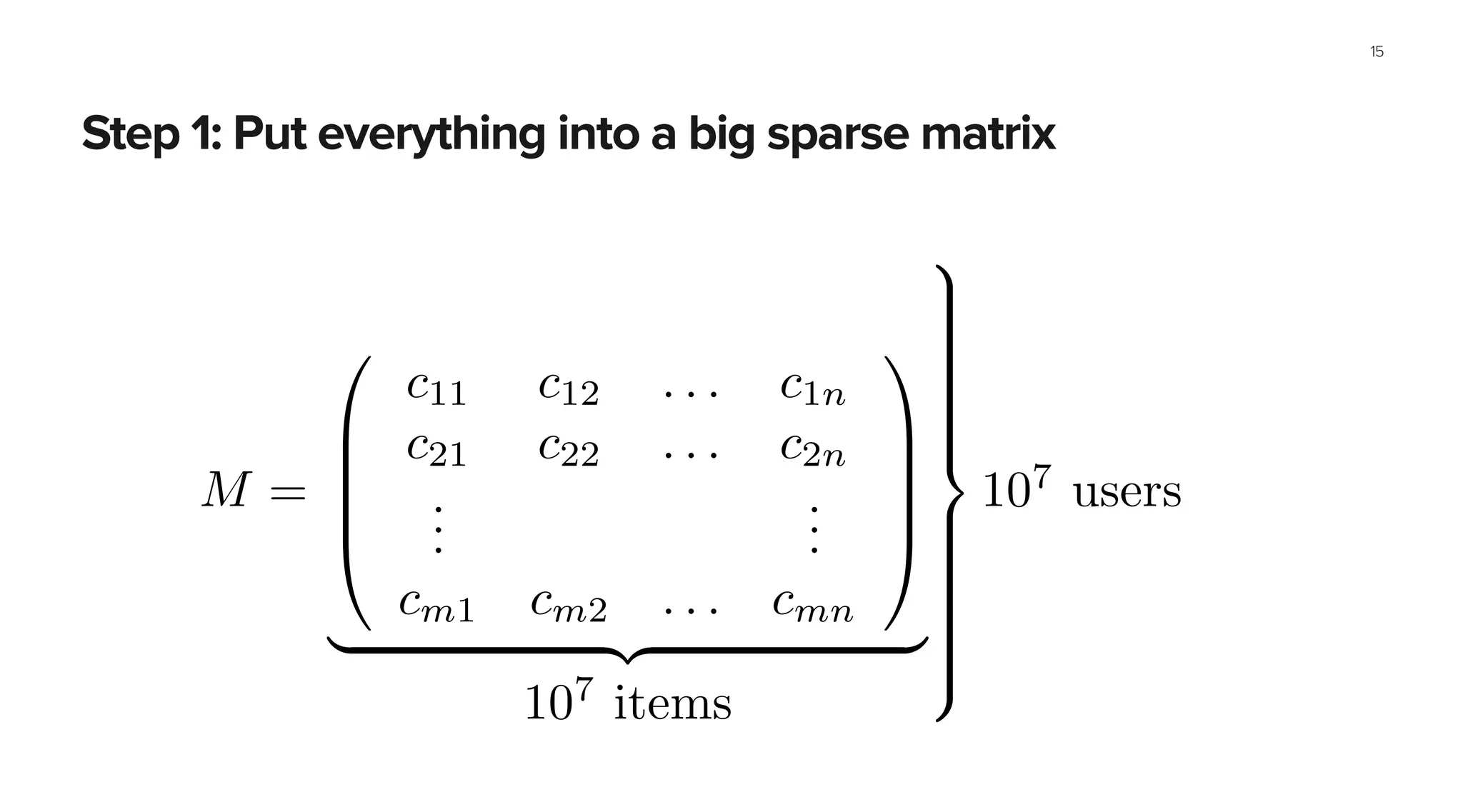



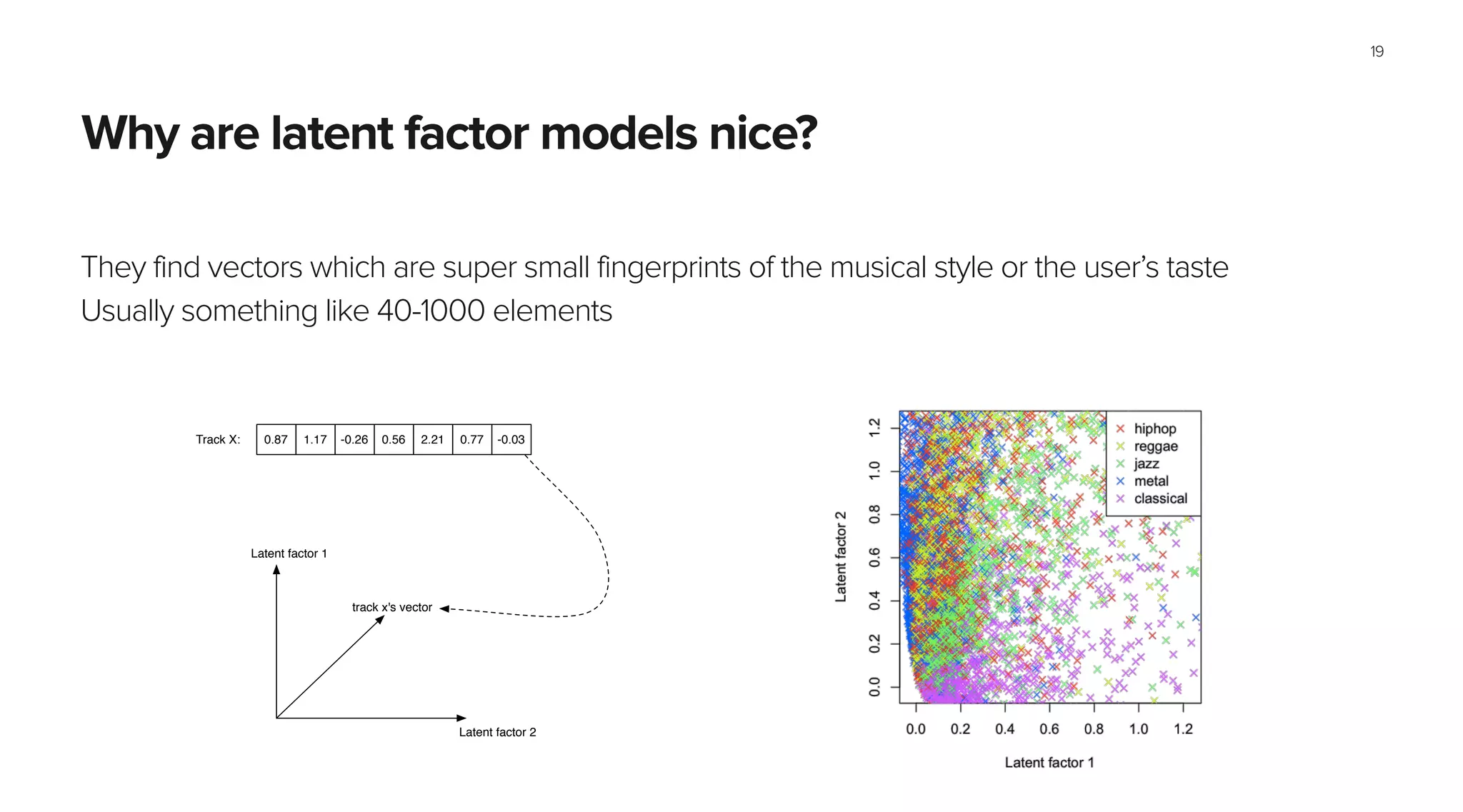

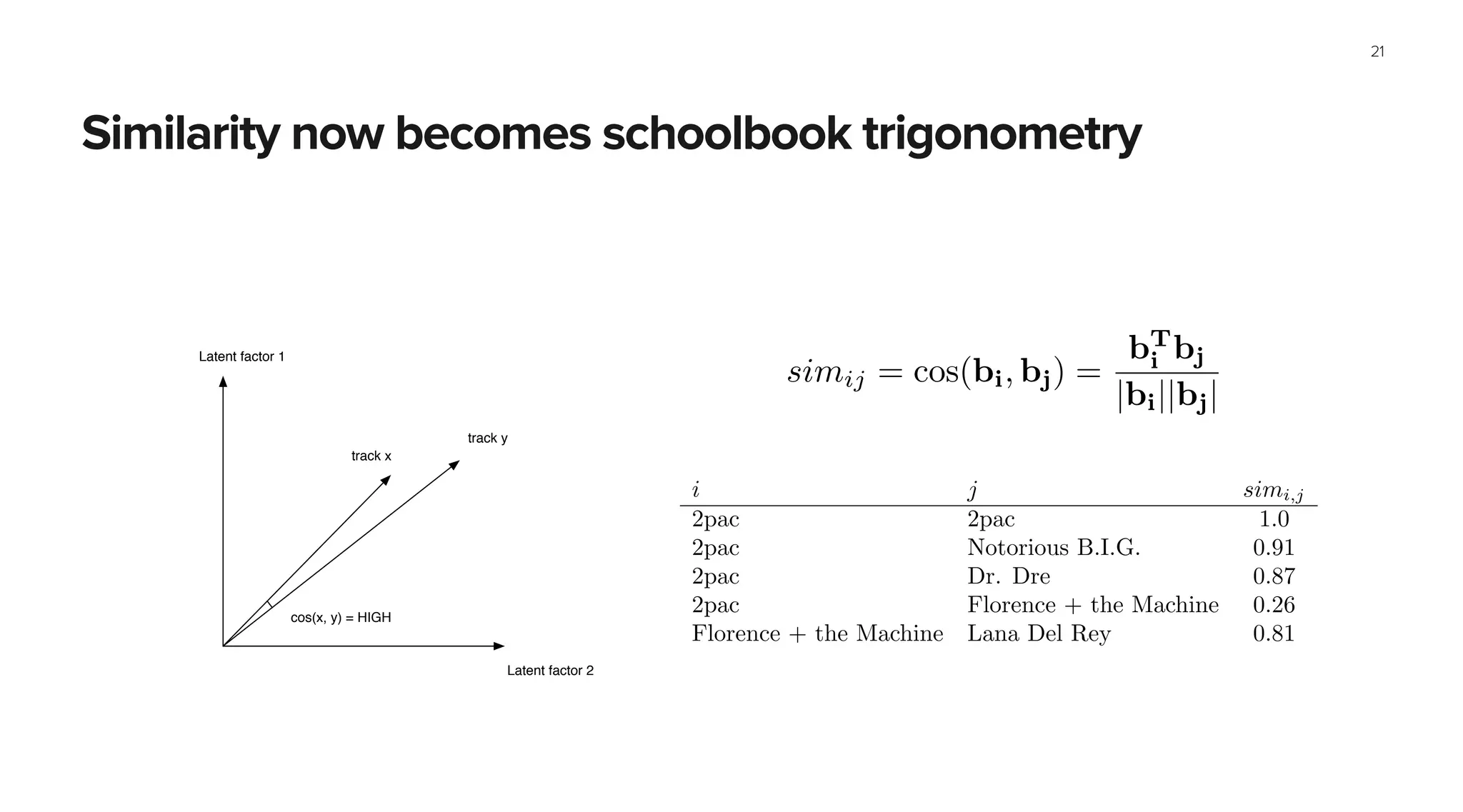





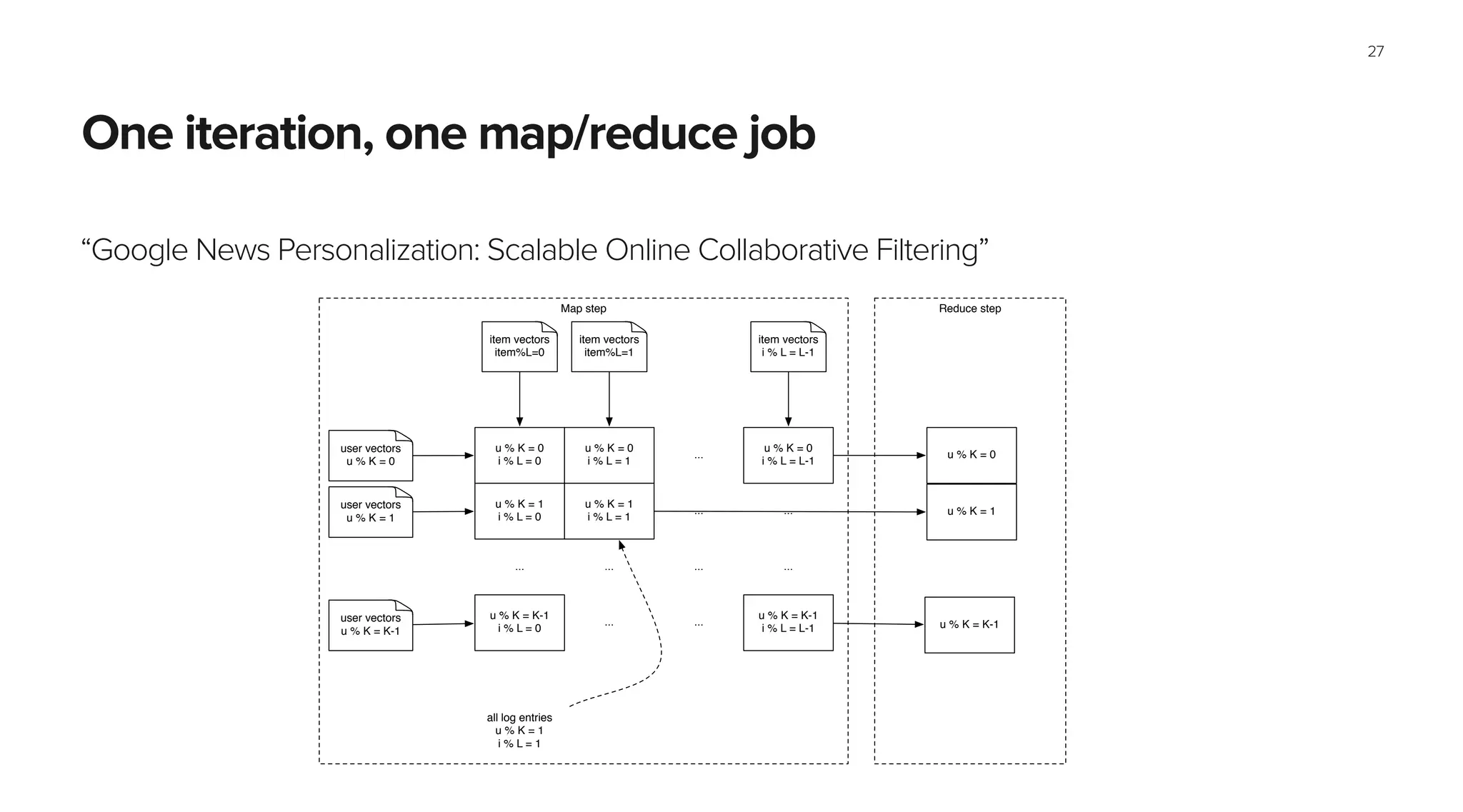


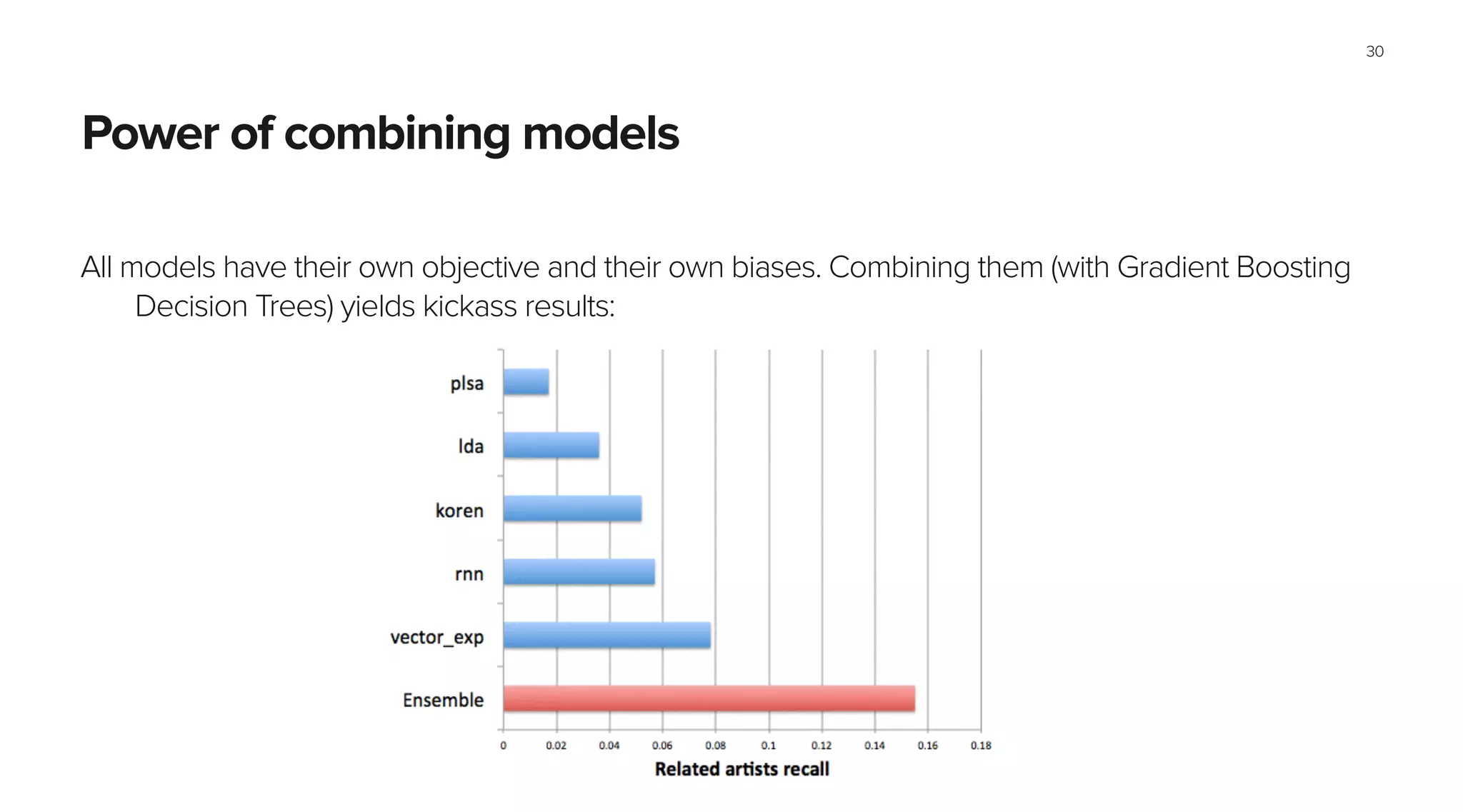











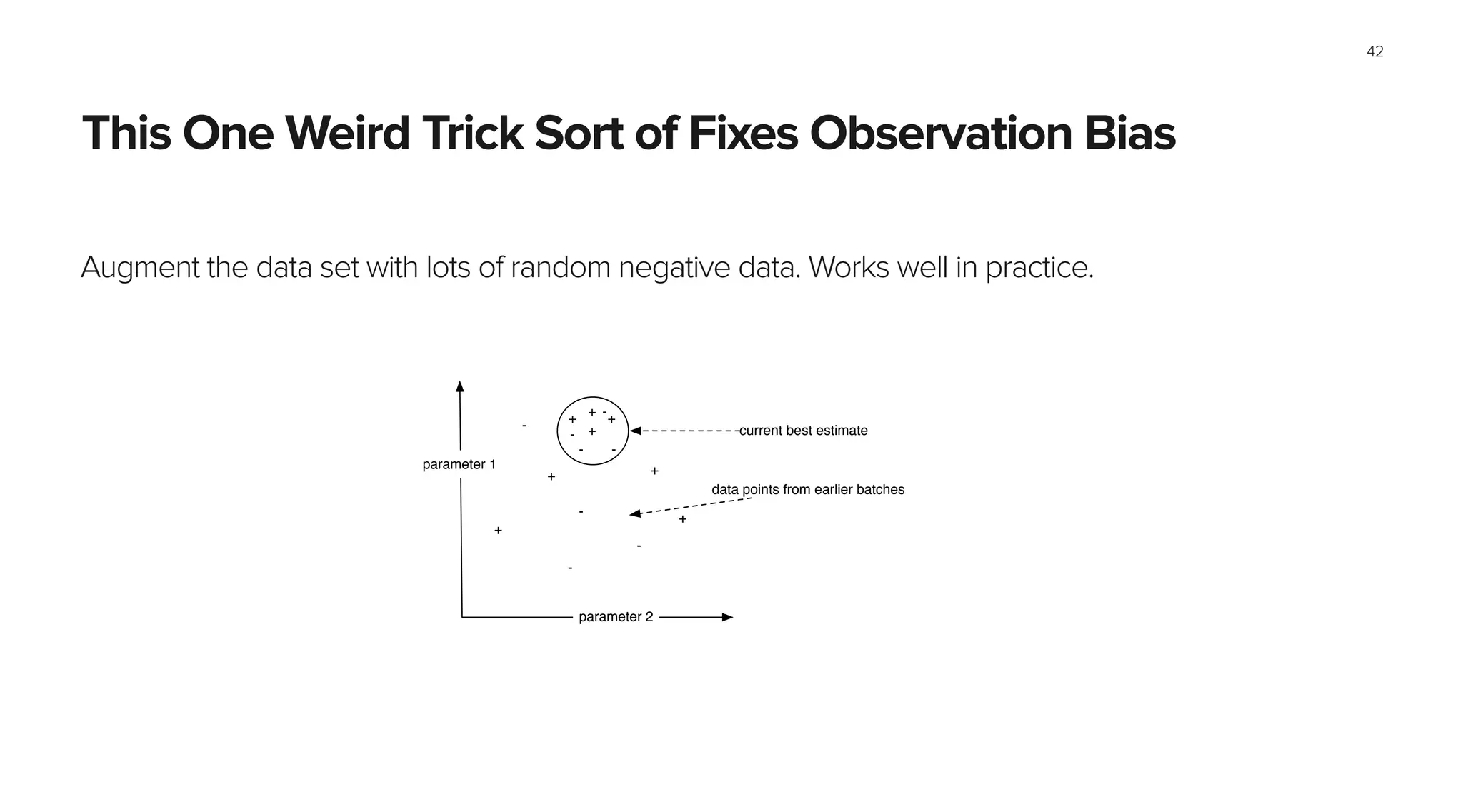



This document summarizes Spotify's approach to music discovery and recommendations using machine learning techniques. It discusses how Spotify analyzes billions of user streams to find patterns and make recommendations using collaborative filtering and latent factor models. It also explores combining multiple models like recurrent neural networks, word2vec, and gradient boosted decision trees to improve recommendations. The challenges of evaluating recommendations and optimizing for the right metrics are also summarized.


































































