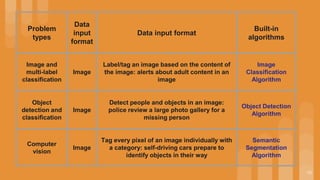
This document provides an overview of Amazon SageMaker's built-in algorithms for machine learning including supervised, unsupervised, and self-supervised algorithms. It describes algorithms for problems like classification, regression, forecasting, anomaly detection, clustering, dimensionality reduction, text analysis, and computer vision. Example use cases are provided for each type of algorithm and data input format.






























































![Lect 1 Number systems and base conversions. [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/lect1numbersystemsandbaseconversions-260111134109-67c2d865-thumbnail.jpg?width=640&height=640&fit=bounds)