11
Python 機械学習プログラミング
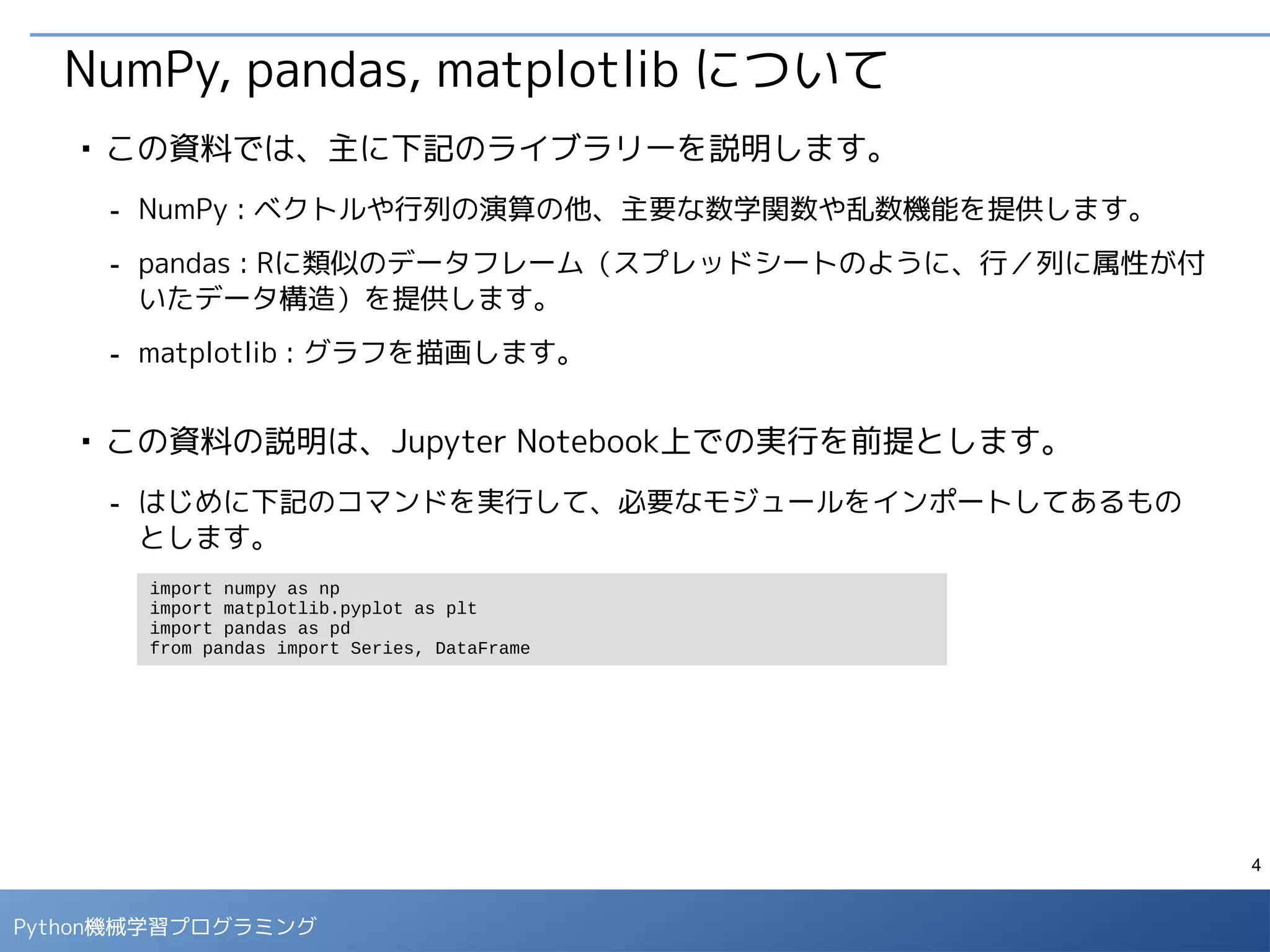
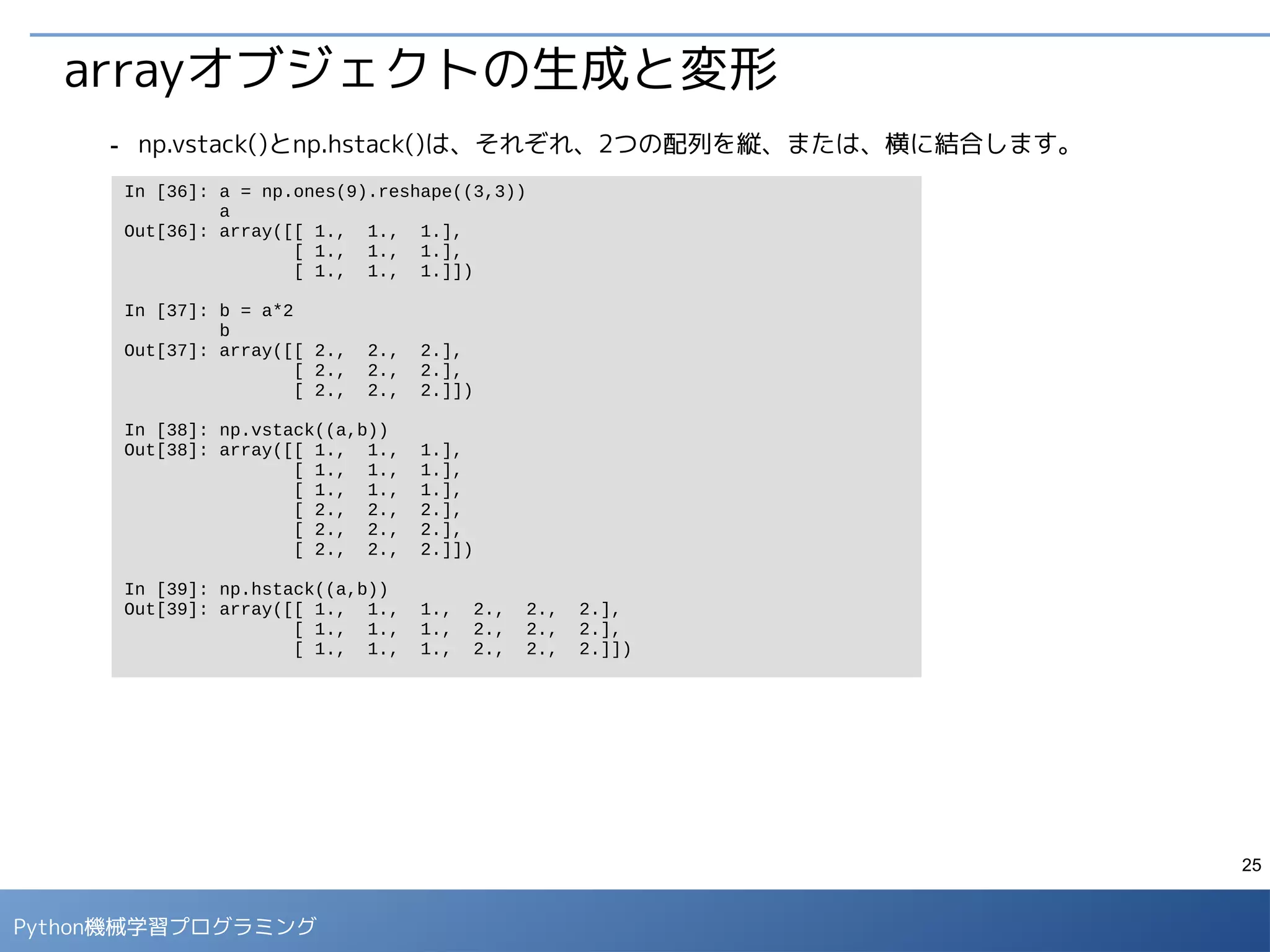
データの取り込み
■
Webで公開されているcsvデータをpandasのデータフレームに取り込みます。
- 取り込んだデータの説明は下記に記載されています。
●
http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic3info.txt
-数値自体に意味のないデータが数値で表現されている場合、誤った(意味のない)統計量を計算
しないように、データ型を文字列型に変換しておきます。いまの場合、「pclass(社会的地
位)」は数値で表現されていますが、この値の「平均値」を取っても特に意味はありません。
In [1]: import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from pandas import Series, DataFrame
In [2]: data = pd.read_csv('http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic3.csv')
data['pclass'] = data['pclass'].map(str) # pclassの型を文字列型に変換
VARIABLE DESCRIPTIONS:
pclass Passenger Class
(1 = 1st; 2 = 2nd; 3 = 3rd)
survived Survival
(0 = No; 1 = Yes)
name Name
sex Sex
age Age
sibsp Number of Siblings/Spouses Aboard
parch Number of Parents/Children Aboard
ticket Ticket Number
fare Passenger Fare
cabin Cabin
embarked Port of Embarkation
(C = Cherbourg; Q = Queenstown; S = Southampton)
boat Lifeboat
body Body Identification Number
home.dest Home/Destination
タイタニック号の乗船名簿の情報に、
沈没による死亡情報を加えたものです。


![7
Python 機械学習プログラミング
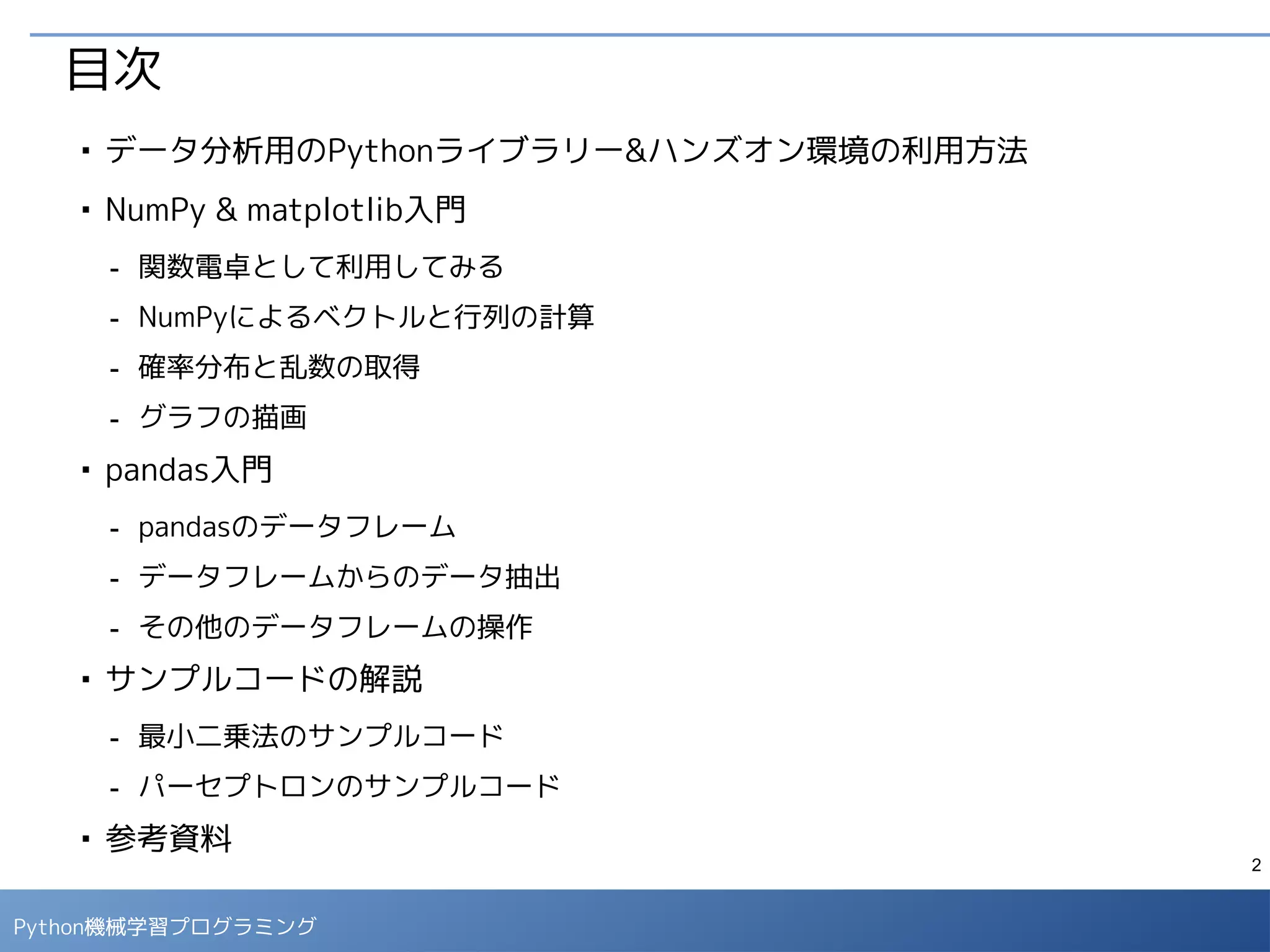
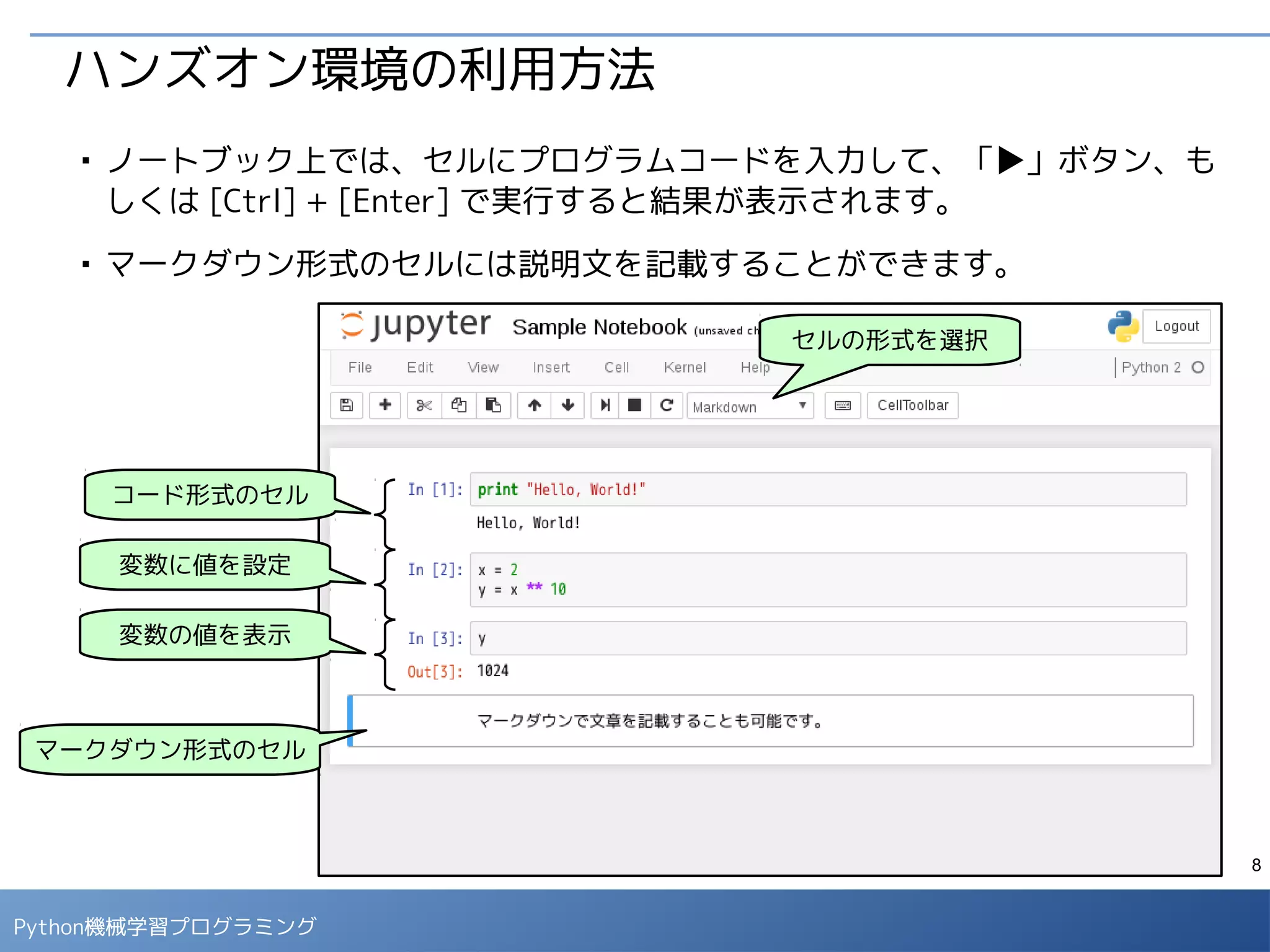
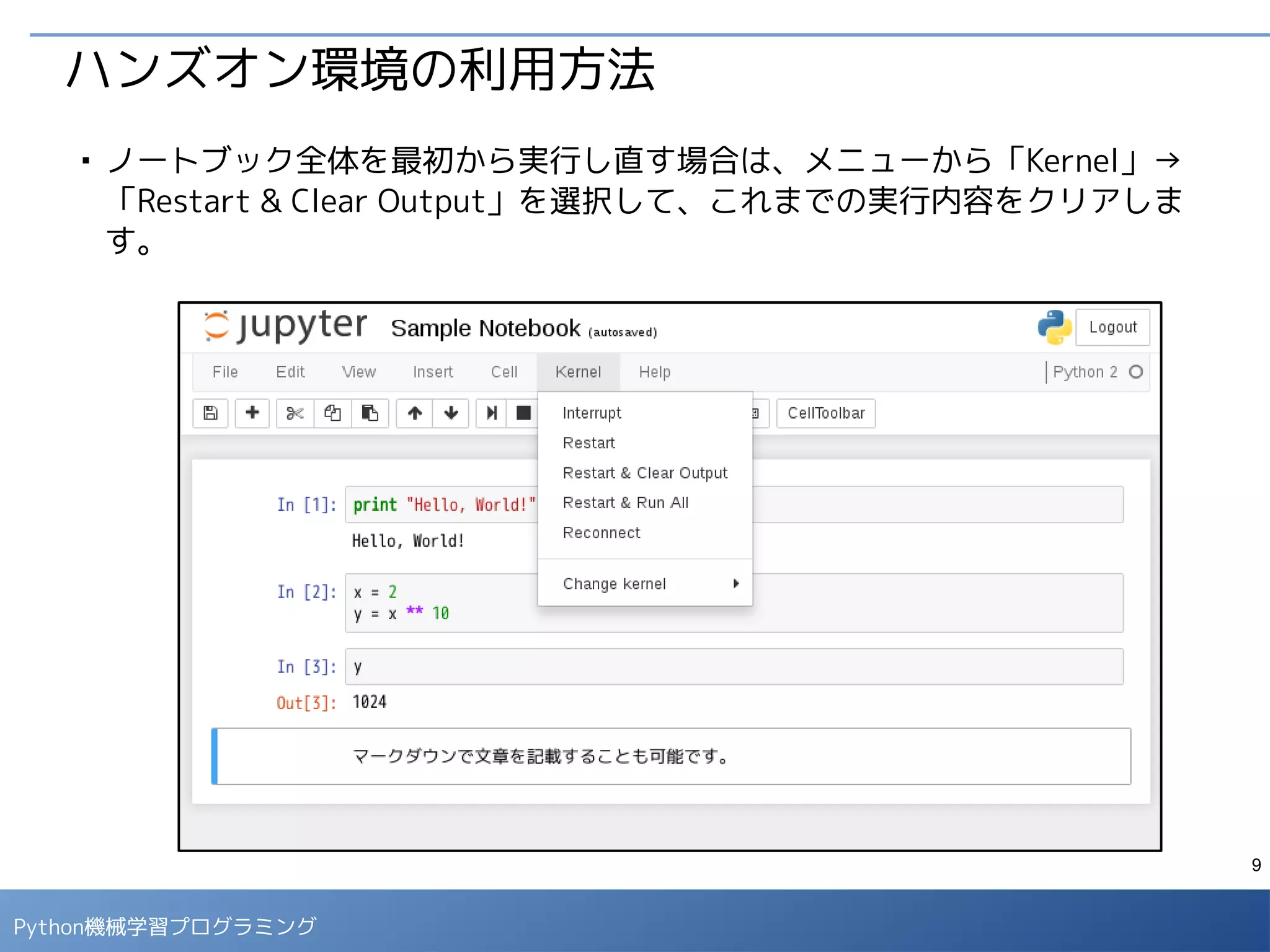
ハンズオン環境の利用方法
■
ノートブック上では、セルにプログラムコードを入力して、「▶」ボタン、も
しくは [Ctrl] + [Enter] で実行すると結果が表示されます。
■
マークダウン形式のセルには説明文を記載することができます。
セルの形式を選択
マークダウン形式のセル
コード形式のセル
変数に値を設定
変数の値を表示](https://image.slidesharecdn.com/pythontoolsexcersizev10-151125073528-lva1-app6892/75/Python-7-2048.jpg)
![11
Python 機械学習プログラミング
データの取り込み
■
Webで公開されているcsvデータをpandasのデータフレームに取り込みます。
- 取り込んだデータの説明は下記に記載されています。
●
http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic3info.txt
- 数値自体に意味のないデータが数値で表現されている場合、誤った(意味のない)統計量を計算
しないように、データ型を文字列型に変換しておきます。いまの場合、「pclass(社会的地
位)」は数値で表現されていますが、この値の「平均値」を取っても特に意味はありません。
In [1]: import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from pandas import Series, DataFrame
In [2]: data = pd.read_csv('http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic3.csv')
data['pclass'] = data['pclass'].map(str) # pclassの型を文字列型に変換
VARIABLE DESCRIPTIONS:
pclass Passenger Class
(1 = 1st; 2 = 2nd; 3 = 3rd)
survived Survival
(0 = No; 1 = Yes)
name Name
sex Sex
age Age
sibsp Number of Siblings/Spouses Aboard
parch Number of Parents/Children Aboard
ticket Ticket Number
fare Passenger Fare
cabin Cabin
embarked Port of Embarkation
(C = Cherbourg; Q = Queenstown; S = Southampton)
boat Lifeboat
body Body Identification Number
home.dest Home/Destination
タイタニック号の乗船名簿の情報に、
沈没による死亡情報を加えたものです。](https://image.slidesharecdn.com/pythontoolsexcersizev10-151125073528-lva1-app6892/75/Python-11-2048.jpg)

![13
Python 機械学習プログラミング
データのサマリー情報の確認
■
項目ごとのデータ数や平均値など、標準的な統計量を確認しておきます。
- 項目によってデータ数(count)が異なるのは、欠損値が存在するためです。
- 欠損値の影響で、パーセンタイルがうまく計算できていない部分があります。これらの項目は、
次ページのように、欠損値を削除して計算します。
In [3]: data.columns
Out[3]: Index([u'pclass', u'survived', u'name', u'sex', u'age', u'sibsp', u'parch',
u'ticket', u'fare', u'cabin', u'embarked', u'boat', u'body',
u'home.dest'], dtype='object')
In [4]: data.describe()
Out[4]:](https://image.slidesharecdn.com/pythontoolsexcersizev10-151125073528-lva1-app6892/75/Python-13-2048.jpg)
![14
Python 機械学習プログラミング
データのサマリー情報の確認
■
dropna()メソッドで欠損値を含む行を削除した上で、統計情報を確認します。
- 平均値(mean)と中央値(50%)が乖離している場合、値の分布に歪み(skew)があると考え
られます。
In [5]: data[['age']].dropna().describe()
In [6]: data[['fare']].dropna().describe()
In [7]: data[['body']].dropna().describe()
平均値と中央値が
乖離した例](https://image.slidesharecdn.com/pythontoolsexcersizev10-151125073528-lva1-app6892/75/Python-14-2048.jpg)
![16
Python 機械学習プログラミング
■
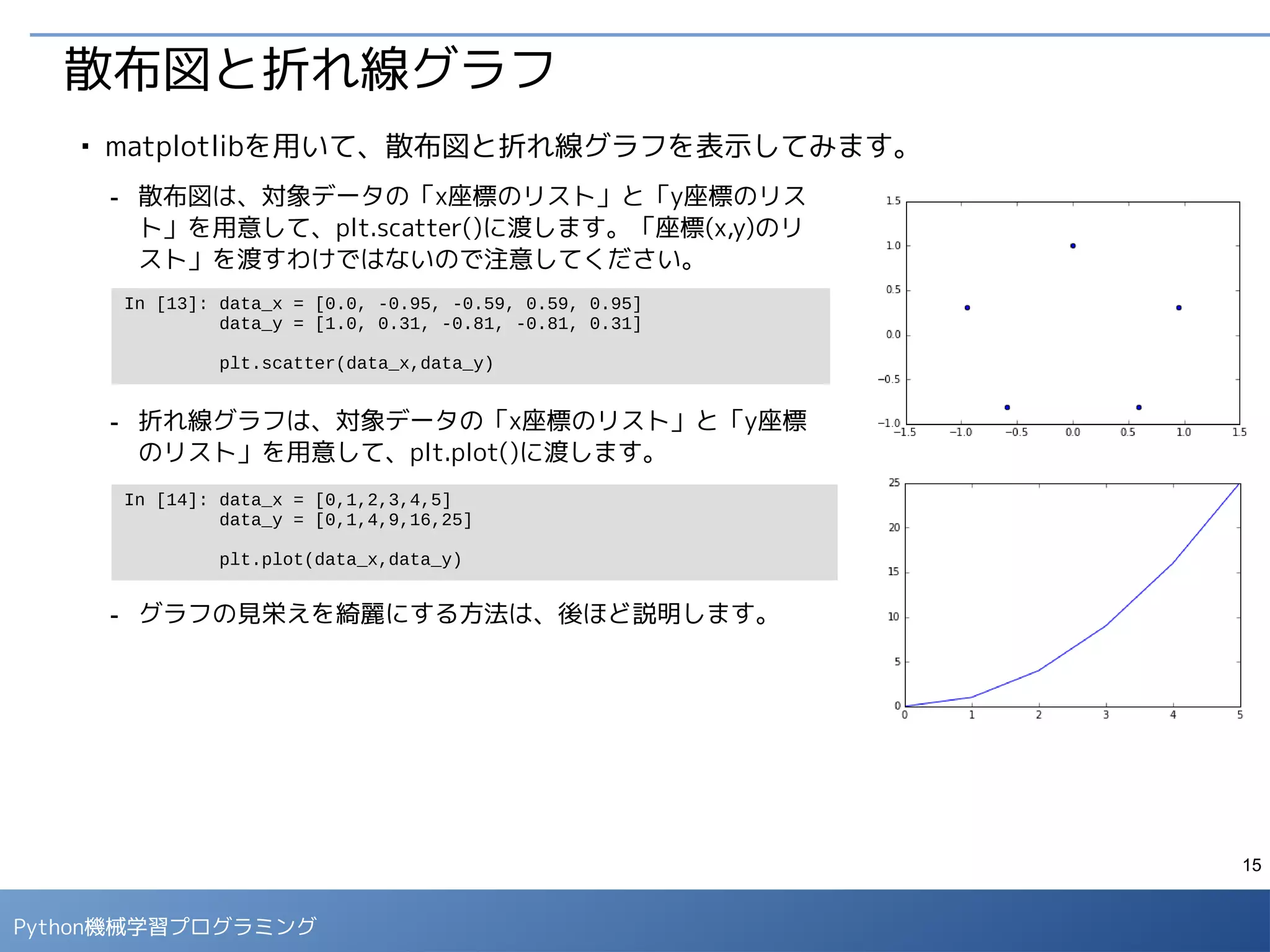
数値データはヒストグラムによって可視化します。
- 例として、年齢(age)と料金(fare)の分布をヒストグラムで確認します。
●
binsオプションには、区間の個数、もしくは、区間の区切りを並べたリストを与えます。
- 5歳未満の子供の分布、もしくは、200ポンド以上の高額料金の乗客などに分布の特徴が見られ
ます。
数値データの可視化
In [8]: data[['age']].dropna().plot(kind='hist', bins=np.linspace(0,100,20+1))
In [9]: data[['fare']].dropna().plot(kind='hist', bins=20) グラフ化する際は、dropna()で
欠損値を削除しておきます。](https://image.slidesharecdn.com/pythontoolsexcersizev10-151125073528-lva1-app6892/75/Python-16-2048.jpg)
![17
Python 機械学習プログラミング
数値データの相関の可視化
■
2つの数値データの関係性を見るときは、散布図で可視化します。
- 例として、年齢(age)と料金(fare)の関係を散布図で表示します。
In [10]: df = data[['age','fare']].dropna()
df.plot(kind='scatter', x='age', y='fare')
- 特に目立った関係はありませんが、200
ポンド以上の料金で乗船しているのは15
歳以上に限られるなどが確認できます。](https://image.slidesharecdn.com/pythontoolsexcersizev10-151125073528-lva1-app6892/75/Python-17-2048.jpg)
![18
Python 機械学習プログラミング
カテゴリーデータと数値データの相関の可視化
■
カテゴリーデータと数値データの関係性を見るときは、箱ひげ図で可視化します。
- 例として、社会的地位(pclass)と料金(fare)の関係を箱ひげ図で表示します。
In [11]: df = data[['fare','pclass']].dropna()
df.boxplot(column='fare', by='pclass')
- 社会的地位が高い人(pclass:1)は
高額料金で乗船していることがわか
ります。
外れ値
75パーセンタイル
50パーセンタイル
(中央値)
25パーセンタイル](https://image.slidesharecdn.com/pythontoolsexcersizev10-151125073528-lva1-app6892/75/Python-18-2048.jpg)
![19
Python 機械学習プログラミング
3つ以上のデータの相関の可視化
■
3つ以上のデータの関係を表示する場合は、データの種類に応じて適切な可視化方法を
選択する必要があります。
- たとえば、年齢(age)と料金(fare)の散布図を社会的地位(pclass)で色分けしてみます。
In [12]: df1 = data[data.pclass=='1'][['age','fare']].dropna()
df2 = data[data.pclass=='2'][['age','fare']].dropna()
df3 = data[data.pclass=='3'][['age','fare']].dropna()
plt.scatter(df1.age, df1.fare, facecolor='blue')
plt.scatter(df2.age, df2.fare, facecolor='green')
plt.scatter(df3.age, df3.fare, facecolor='red')](https://image.slidesharecdn.com/pythontoolsexcersizev10-151125073528-lva1-app6892/75/Python-19-2048.jpg)
![20
Python 機械学習プログラミング
カテゴリーデータの相関
■
カテゴリーデータの例として、性別(sex)と生存(survival)の相関を確認します。
- 2種類のカテゴリーデータの相関は、クロス集計表で確認します。
- この結果を見ると、性別によって生存率が大きく変わることが分かります。
- 同様の分析を社会的地位(pclass)と生存(survival)について行ってみてください。
- また、その他のデータについても自分なりの可視化を行って、特徴を発見してみてください。
In [13]: df = data[['sex','survived']].dropna()
pd.crosstab(df.sex, df.survived)
Out[13]:
In [14]: pd.crosstab(data.sex ,data.survived).plot(kind='bar')
In [15]: df.mean()
Out[15]:
Survived 0.381971 # 平均生存率
dtype: float64
In [16]: 339.0/(127+339)
Out[16]: 0.7274678111587983 # 女性の生存率](https://image.slidesharecdn.com/pythontoolsexcersizev10-151125073528-lva1-app6892/75/Python-20-2048.jpg)

![22
Python 機械学習プログラミング
ロジスティック回帰
■
「性別」「年齢」の2つの特徴を用いたロジスティック回帰で、生存確率を予測するモ
デルを構築します。
- この後の分析で使用するモジュールをインポートします。
- 欠損値を含む行を削除して、分析に使用する列のみを含むDataFrameを用意します。ここでは、
特徴変数 X_ とラベル y を個別にDataFrameとして作成しています。
- 性別はカテゴリーデータなので、One Hot Encodingに変換します。
In [20]: from PIL import Image
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.metrics import accuracy_score
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier, export_graphviz
In [22]: X = pd.get_dummies(X_)
X.head()
In [21]: tmp = data[['age', 'sex', 'survived']].dropna()
X_ = tmp[['age', 'sex']]
y = tmp['survived']
X_.head()](https://image.slidesharecdn.com/pythontoolsexcersizev10-151125073528-lva1-app6892/75/Python-22-2048.jpg)
![23
Python 機械学習プログラミング
ロジスティック回帰
- データセットをトレーニングセットとテストセットに分割した後、トレーニングセットを用いて
学習処理を実行します。さらに、トレーニングセットとテストセットに対する正解率を計算しま
す。
- クロスバリデーションを実施して、結果を表示します。
In [23]: X_train, X_val, y_train, y_val = train_test_split(X, y, train_size=0.8, random_state=1)
clf = LogisticRegression()
clf.fit(X_train, y_train)
y_train_pred = clf.predict(X_train)
y_val_pred = clf.predict(X_val)
print 'Accuracy on Training Set: {:.3f}'.format(accuracy_score(y_train, y_train_pred))
print 'Accuracy on Validation Set: {:.3f}'.format(accuracy_score(y_val, y_val_pred))
Out[23]:
Accuracy on Training Set: 0.775
Accuracy on Validation Set: 0.795
In [24]: clf = LogisticRegression()
scores = cross_val_score(clf, X, y, cv=5)
print 'Scores:', scores
print 'Mean Score: {:f} ± {:.3}'.format(scores.mean(), scores.std())
Out[24]:
Scores: [ 0.84761905 0.83333333 0.78947368 0.74641148 0.67788462]
Mean Score: 0.778944 ± 0.0617](https://image.slidesharecdn.com/pythontoolsexcersizev10-151125073528-lva1-app6892/75/Python-23-2048.jpg)
![24
Python 機械学習プログラミング
決定木(Decision Tree)
■
決定木を用いて、先ほどと同じ分析を実施します。
- クロスバリデーションを実施して、結果を表示します。
- 決定木を画像化して表示します。
In [26]: clf = DecisionTreeClassifier(criterion='entropy', max_depth=2, min_samples_leaf=2)
scores = cross_val_score(clf, X, y, cv=5)
print 'Scores:', scores
print 'Mean Score: {:f} ± {:.3}'.format(scores.mean(), scores.std())
Out [26]:
Scores: [ 0.85714286 0.83809524 0.79425837 0.74641148 0.64423077]
Mean Score: 0.776028 ± 0.0762
In [27]: clf.fit(X, y)
export_graphviz(clf, out_file='tree.dot',
feature_names=X.columns,
class_names=['not survived', 'survived'],
impurity=False, filled=True)
!dot -Tpng tree.dot -o tree.png
Image.open("tree.png")
- 性別・年齢・社会的地位(pclass)を特徴量
として、同様の分析を行ってみてください
※ 特徴量を増やした場合は、決定木の階層をより深
くするとよい場合があります。](https://image.slidesharecdn.com/pythontoolsexcersizev10-151125073528-lva1-app6892/75/Python-24-2048.jpg)





![[DL Hacks]Simple Online Realtime Tracking with a Deep Association Metric](https://cdn.slidesharecdn.com/ss_thumbnails/2019-04-01dlhacksdeepsortsugisaki-190412022858-thumbnail.jpg?width=640&height=640&fit=bounds)











































![[機械学習]文章のクラス分類](https://cdn.slidesharecdn.com/ss_thumbnails/ss-160218112331-thumbnail.jpg?width=640&height=640&fit=bounds)














![[輪講] 第1章](https://cdn.slidesharecdn.com/ss_thumbnails/random-171231020415-thumbnail.jpg?width=640&height=640&fit=bounds)



![[第2版] Python機械学習プログラミング 第1章](https://cdn.slidesharecdn.com/ss_thumbnails/python-machine-learning-2nd-edition-01-180905090109-thumbnail.jpg?width=640&height=640&fit=bounds)



















