More Related Content

PDF
scikit-learnを用いた機械学習チュートリアル 
PPTX
PythonとRによるデータ分析環境の構築と機械学習によるデータ認識 
PDF

PDF

PDF

PDF
Python東海Vol.5 IPythonをマスターしよう 
PPTX
Jupyter Notebookでscikit-learnを使った機械学習・画像処理の基本 
PPTX
PythonとRによるデータ分析環境の構築と機械学習によるデータ認識 第3版 What's hot

PPTX

PPTX
Webクローリング&スクレイピングの最前線 公開用 
PPTX

PDF

PDF
High performance python computing for data science 
PDF

PDF
(Pythonで作って学ぶ) Youtube の動画リストを作るアプリの開発
第4回 
PDF
「Python言語」はじめの一歩 / First step of Python 
PDF
PyAutoGUI等Pythonライブラリによる自動化支援 
PDF

PDF
Python 2/3コード共存戦略 #osakapy 
PPTX

PPT

PPTX

PDF

PDF

PDF

PPTX
Pythonで機械学習を自動化 auto sklearn 
PDF

PPTX
Python による 「スクレイピング & 自然言語処理」入門 Viewers also liked

PDF
python-twitterを用いたTwitterデータ収集 
PDF
Python 機械学習プログラミング データ分析ライブラリー解説編 
PDF

PDF
野球Hack!~Pythonを用いたデータ分析と可視化 #pyconjp 
PDF

PDF

PDF
Python入門 : 4日間コース社内トレーニング 
PDF

PDF
JupyterNotebookとMySQLでゼロからはじめるデータサイエンス 
PDF
ソフトシンセを作りながら学ぶPythonプログラミング 
PDF

PPTX
Pythonスタートアップ勉強会201109 python入門 
PDF
Pythonによるwebアプリケーション入門 - Django編- 
PDF

PDF

PDF

PDF

PDF

PDF
最新業界事情から見るデータサイエンティストの「実像」 
PDF
Similar to PythonによるWebスクレイピング入門

PDF

PPTX

PDF
ScrapyとPhantomJSを用いたスクレイピングDSL 
PDF

PDF

PPTX

PDF

PPTX

PDF

PDF
Rubyで作るクローラー Ruby crawler 
PDF

PDF

PPTX

PDF
Lispmeetup #56 Common lispによるwebスクレイピング技法 
PPTX
第3回Webスクレイピング勉強会@東京 happyou.info 
PDF

PDF

PDF
不純な動機で「puppeteer」 でスクレイピングを始めてみた 
PDF

PDF
PythonによるWebスクレイピング入門
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
サンプル
import re, urllib2
res= urllib2.urlopen( http://ll.jus.or.jp/2014/program")
pattern_title = re.compile( <title>(.*?)</title>')
m = pattern_title.search(res.read())
title = m.group(1)
print title
>>> プログラム ¦ LL Diver
- 16.
- 17.
サンプル
import urllib2
from bs4import BeautifulSoup
res = urllib2.urlopen( http://ll.jus.or.jp/2014/program )
soup = BeautifulSoup(res.read())
soup.title
>>> <title>プログラム ¦ LL Diver</title>
for link in soup.find_all( a'):
print(link.get( href'))
>>> http://ll.jus.or.jp/2014/
>>> http://ll.jus.or.jp/2014/
- 18.
- 19.
サンプル
from pyquery importPyQuery as pq
d = pq("http://ll.jus.or.jp/2014/program")
print d( title").text()
>>> プログラム ¦ LL Diver
print d( .entry-title").text()
>>> プログラム
print d( #day ).text()
>>> 昼の部
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
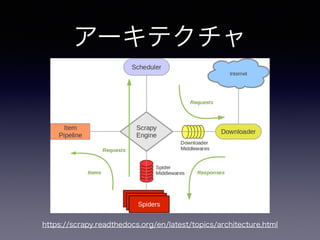
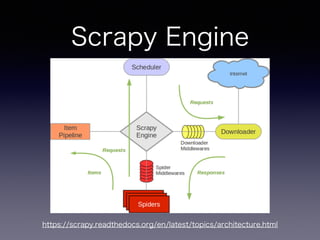
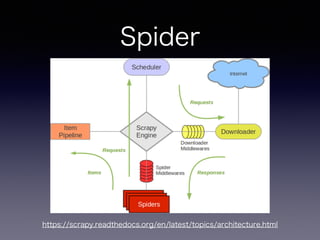
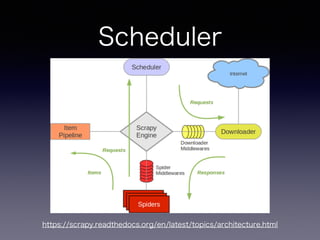
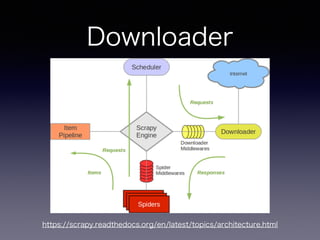
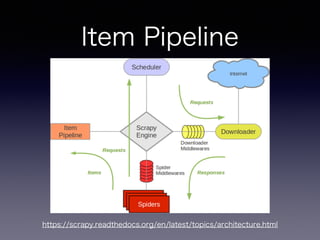
手順
• Scrapy プロジェクトの作成
•抽出するアイテムの定義
• アイテムの抽出とクローリングのためのSpider
を作成
• 抽出したアイテムのパイプライン部分作成
• 基本はSpiderとItem部分を書いていけばOK
- 35.
プロジェクト作成
$ scrapy startprojectscrapy_sample
$ tree scrapy_sample
scrapy_sample/
├── scrapy.cfg
└── scrapy_sample
├── __init__.py
├── items.py
├── pipelines.py
├── settings.py
└── spiders
└── __init__.py
- 36.
- 37.
Spider作成
class MininovaSpider(CrawlSpider):
name ='mininova'
allowed_domains = ['mininova.org']
start_urls = ['http://www.mininova.org/yesterday/']
rules = [Rule(LinkExtractor(allow=['/tor/d+']), parse_torrent')]
!
def parse_torrent(self, response):
torrent = TorrentItem()
torrent['url'] = response.url
torrent['name'] = response.xpath("//h1/text()").extract()
return torrent
- 38.
実行
$ scrapy crawlmininova -o scraped_data.json
$ cat scraped_data.json
{
"url": "http://www.mininova.org/tor/13277197",
"name": ["lady anna voice free plugin VSTI free download new by Softrave ]
},
{
"url": "http://www.mininova.org/tor/13277195",
"name": ["mandala VSTI free download new by Softrave ]
},
- 39.
- 40.
参考URL
• http://scrapy.org (Scrapy )
• http://www.slideshare.net/MasayukiIsobe/web-scraping-20140622isobe
• https://github.com/gawel/pyquery/ ( pyquery )
• http://www.crummy.com/software/BeautifulSoup/ ( BeautfulSoup )
• http://orangain.hatenablog.com/entry/scrapy
• http://akiniwa.hatenablog.jp/entry/2013/04/15/001411
• http://tokyoscrapper.connpass.com/ ( Webスクレイピング勉強会 )
• http://www.slideshare.net/nezuQ/web-36143026?ref=http://www.slideshare.net/slideshow/
embed_code/36143026
• http://qiita.com/nezuq/items/c5e827e1827e7cb29011( 注意事項 )
- 41.
- 42.
- 43.








![クローリング
• 英語の意味は、[ はう、ゆっくり進む]
• Webページのリンクの内容をたどる
• Webページの内容をダウンロードして収集
• クローラー、スパイダーと呼ばれる](https://image.slidesharecdn.com/pythonweb-140823055727-phpapp01/85/Python-Web-7-320.jpg)
![スクレイピング
• 英語の意味は、[ 削ること ]
• ページの内容から、必要な情報を抽出すること](https://image.slidesharecdn.com/pythonweb-140823055727-phpapp01/85/Python-Web-8-320.jpg)






















![Spider作成
class MininovaSpider(CrawlSpider):
name = 'mininova'
allowed_domains = ['mininova.org']
start_urls = ['http://www.mininova.org/yesterday/']
rules = [Rule(LinkExtractor(allow=['/tor/d+']), parse_torrent')]
!
def parse_torrent(self, response):
torrent = TorrentItem()
torrent['url'] = response.url
torrent['name'] = response.xpath("//h1/text()").extract()
return torrent](https://image.slidesharecdn.com/pythonweb-140823055727-phpapp01/85/Python-Web-37-320.jpg)
![実行
$ scrapy crawl mininova -o scraped_data.json
$ cat scraped_data.json
{
"url": "http://www.mininova.org/tor/13277197",
"name": ["lady anna voice free plugin VSTI free download new by Softrave ]
},
{
"url": "http://www.mininova.org/tor/13277195",
"name": ["mandala VSTI free download new by Softrave ]
},](https://image.slidesharecdn.com/pythonweb-140823055727-phpapp01/85/Python-Web-38-320.jpg)




