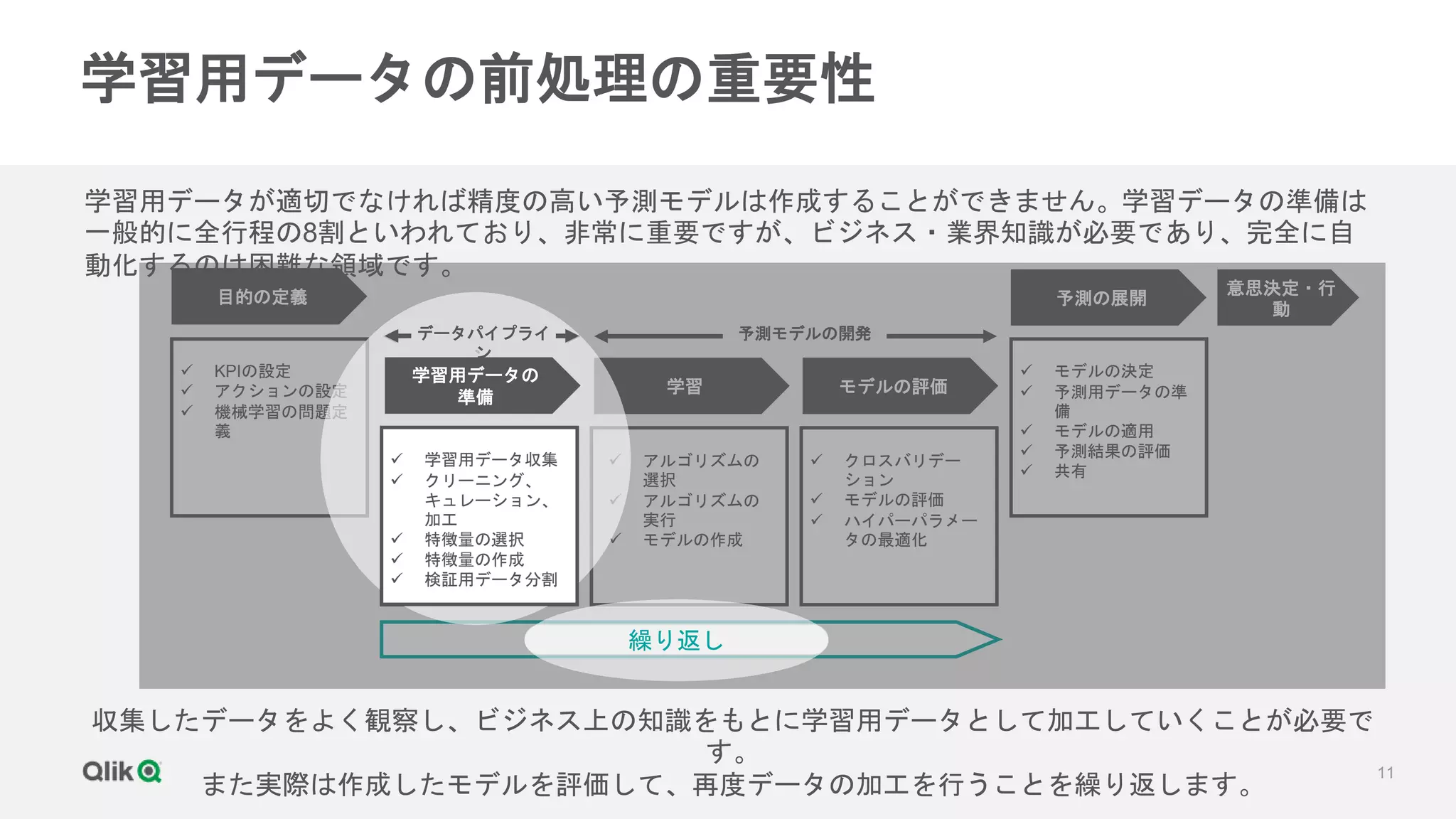
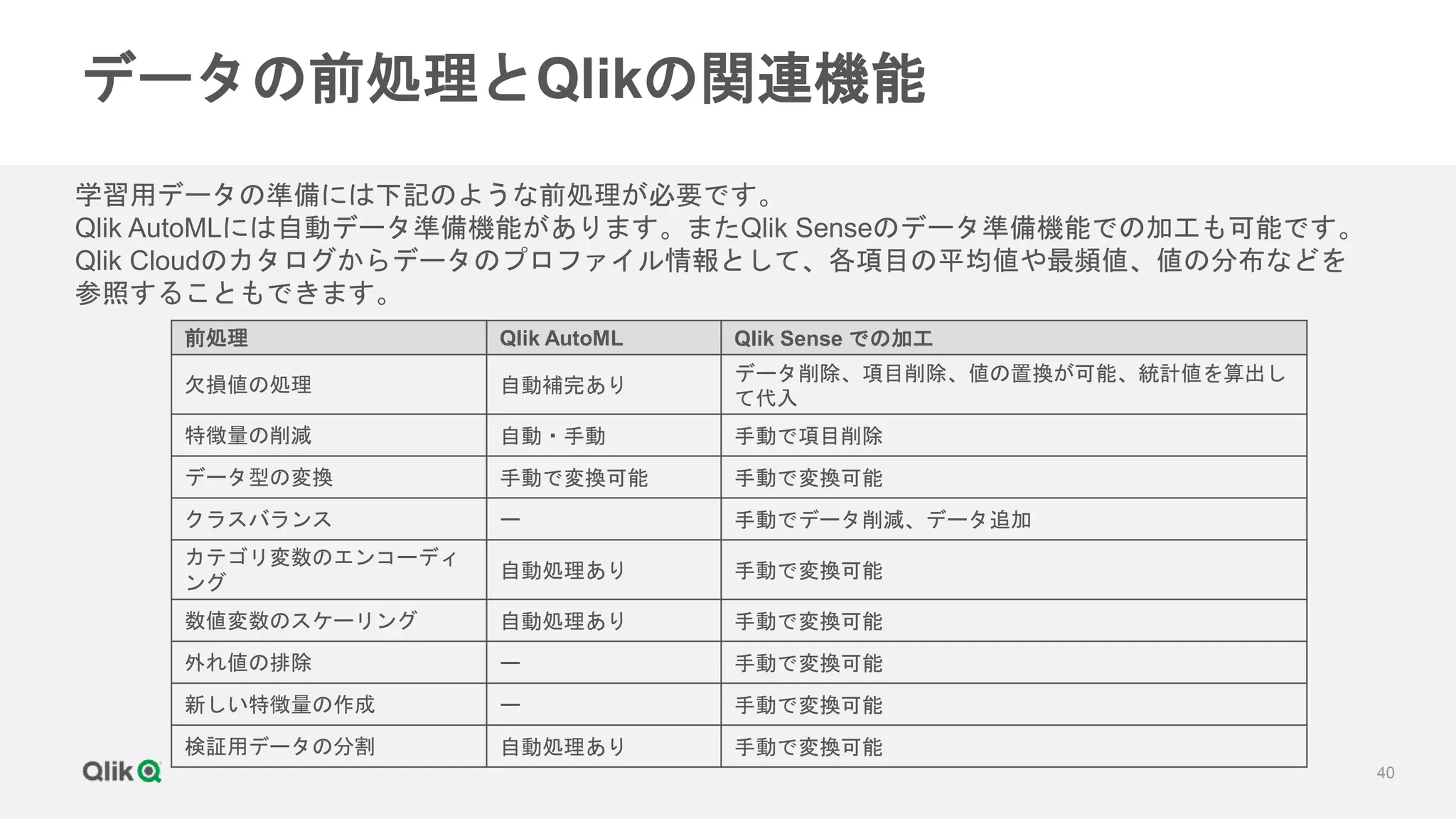
第2回は機械学習のための学習データの前処理についてご説明します。前回、機械学習の問題定義と、それに合わせてどのようなデータを収集するべきかについてお話ししましたが、データは集めただけでは学習用として使用することはできません。機械学習により精度の高い予測モデルを取得するためには、適切な学習データを準備する必要があります。
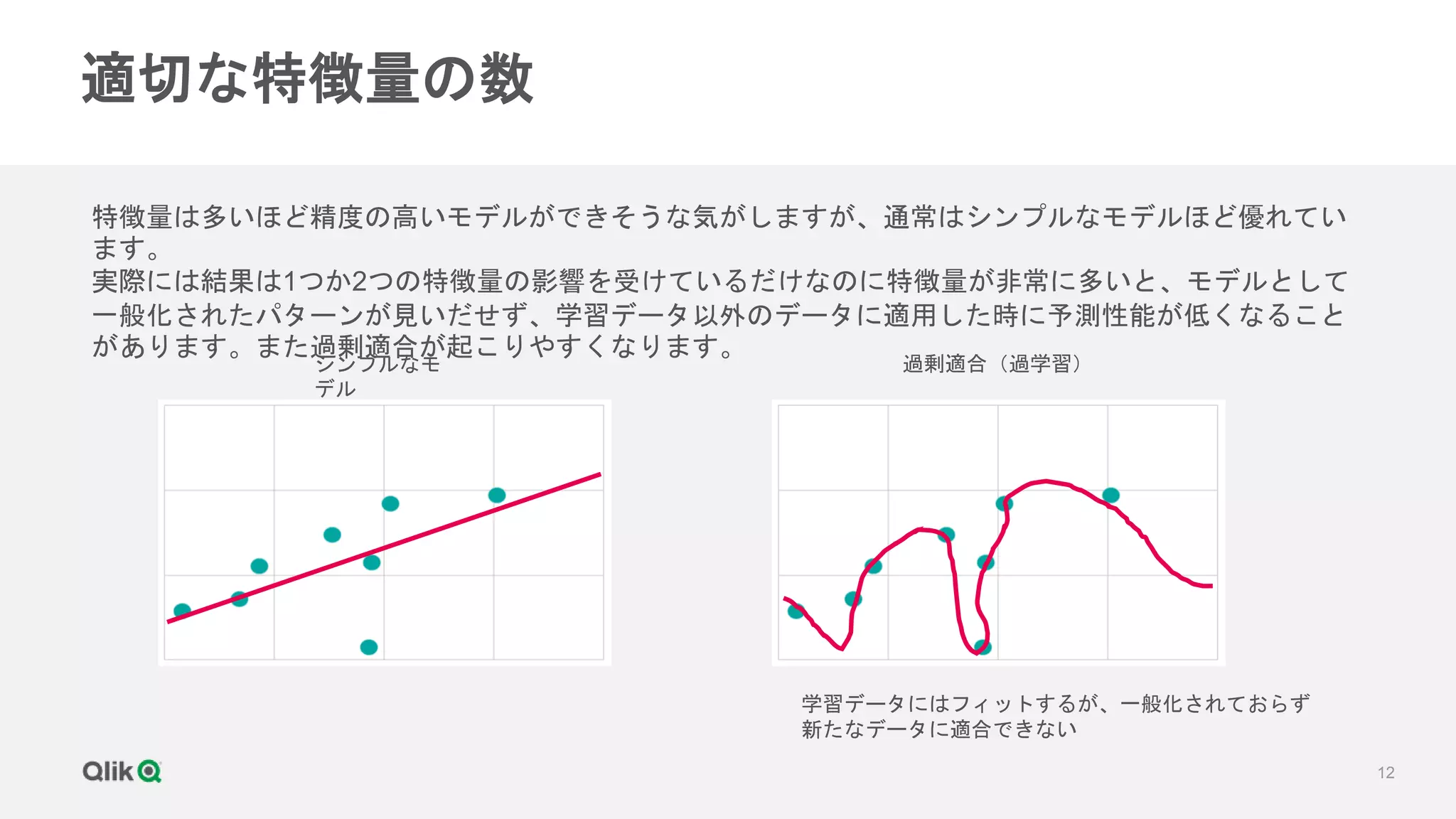
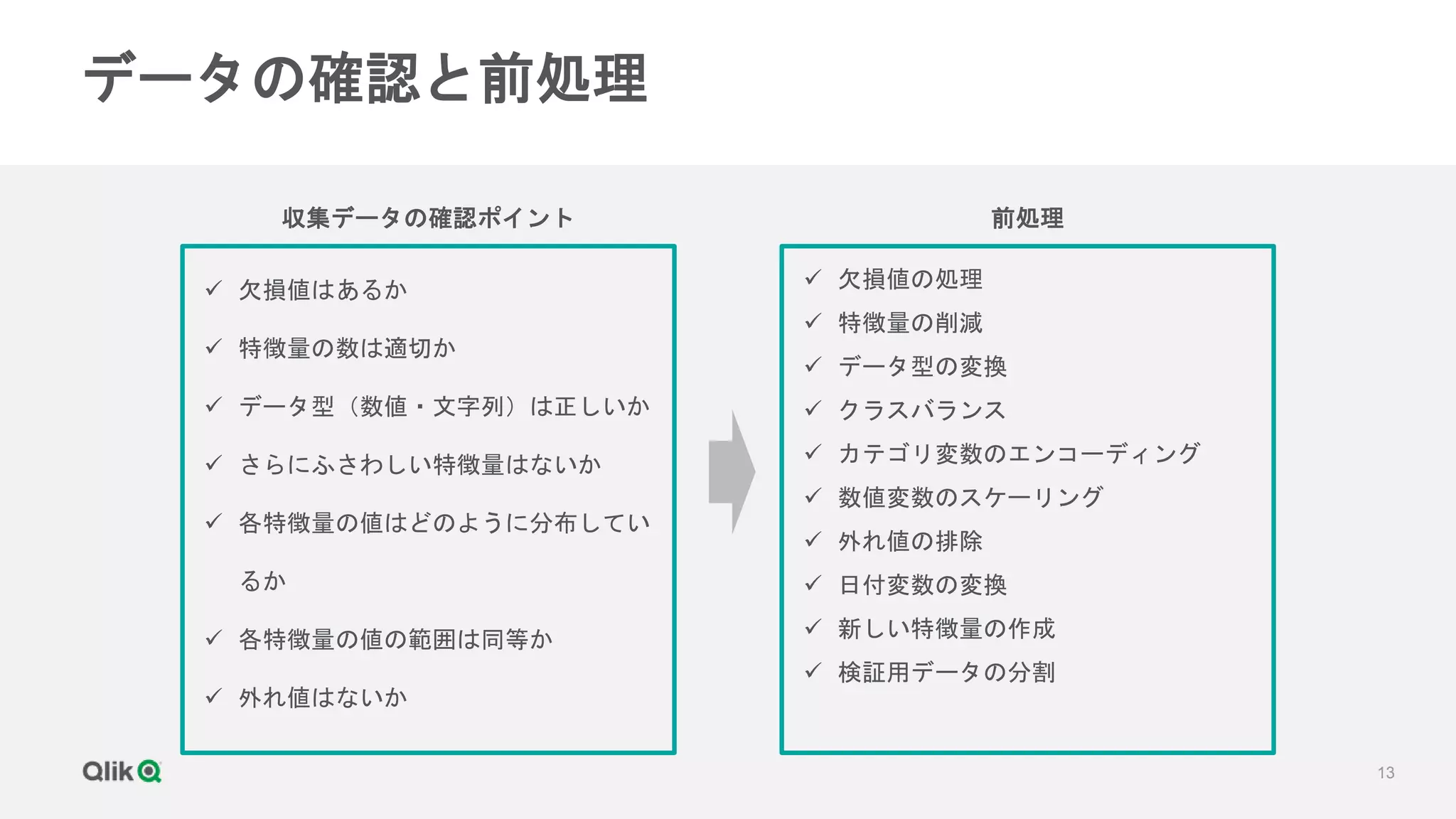
当セミナーでは、全行程の8割を占めると言われる学習データの前処理として、特徴列の削減や生成、データ型の変換、クラスのバランス、ホールドアウトとクロスバリデーションなどについて解説します。











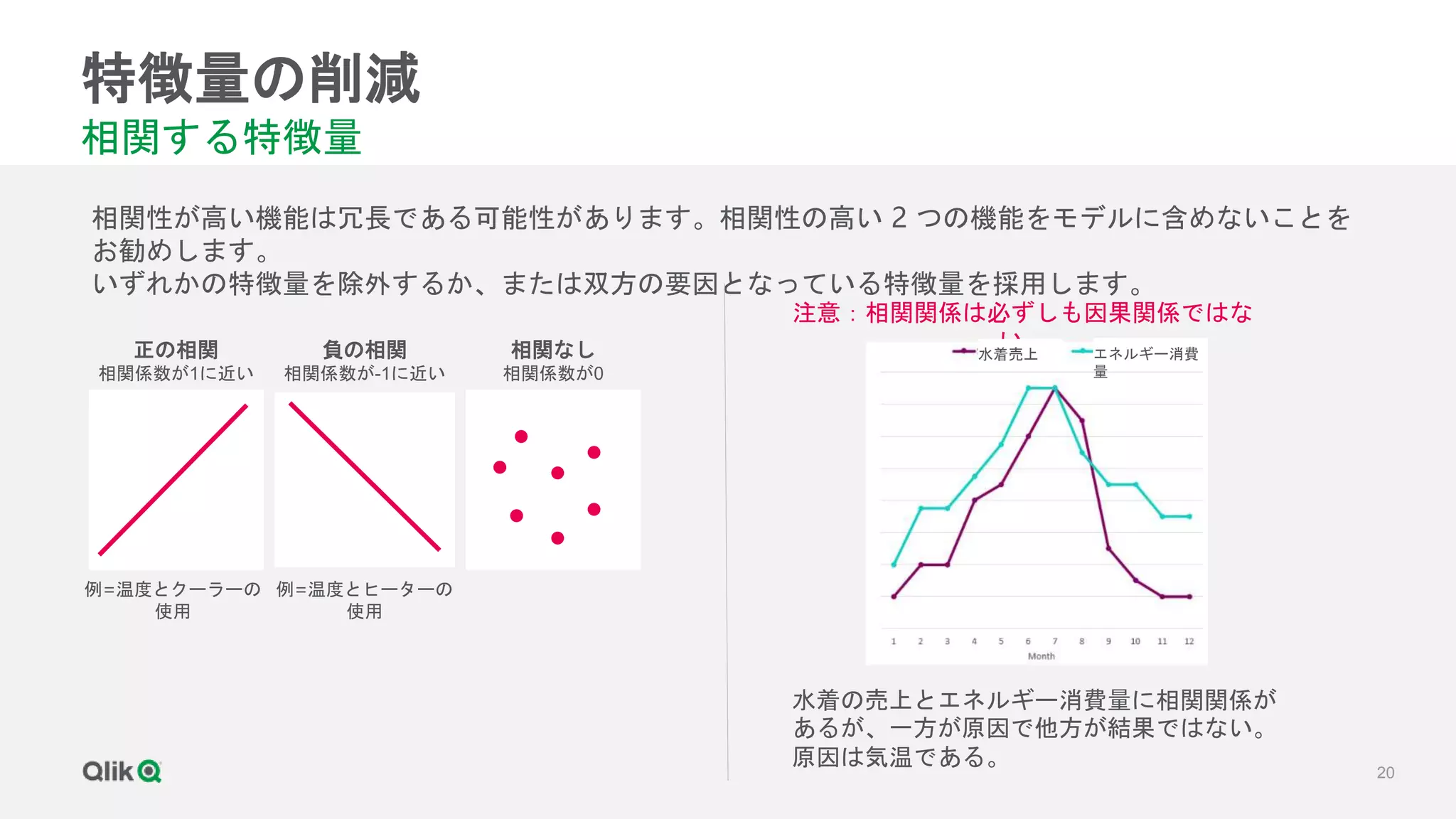

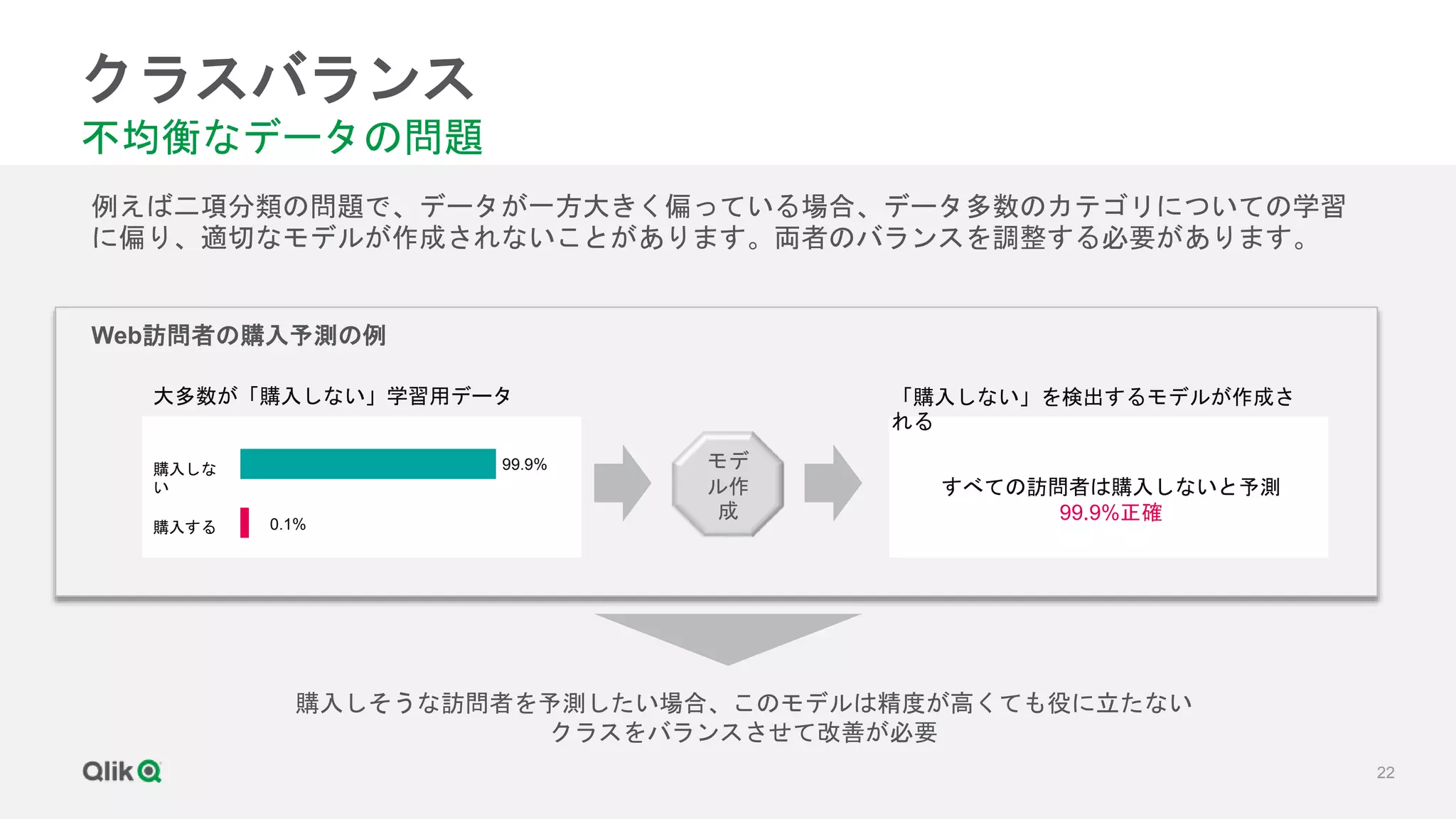


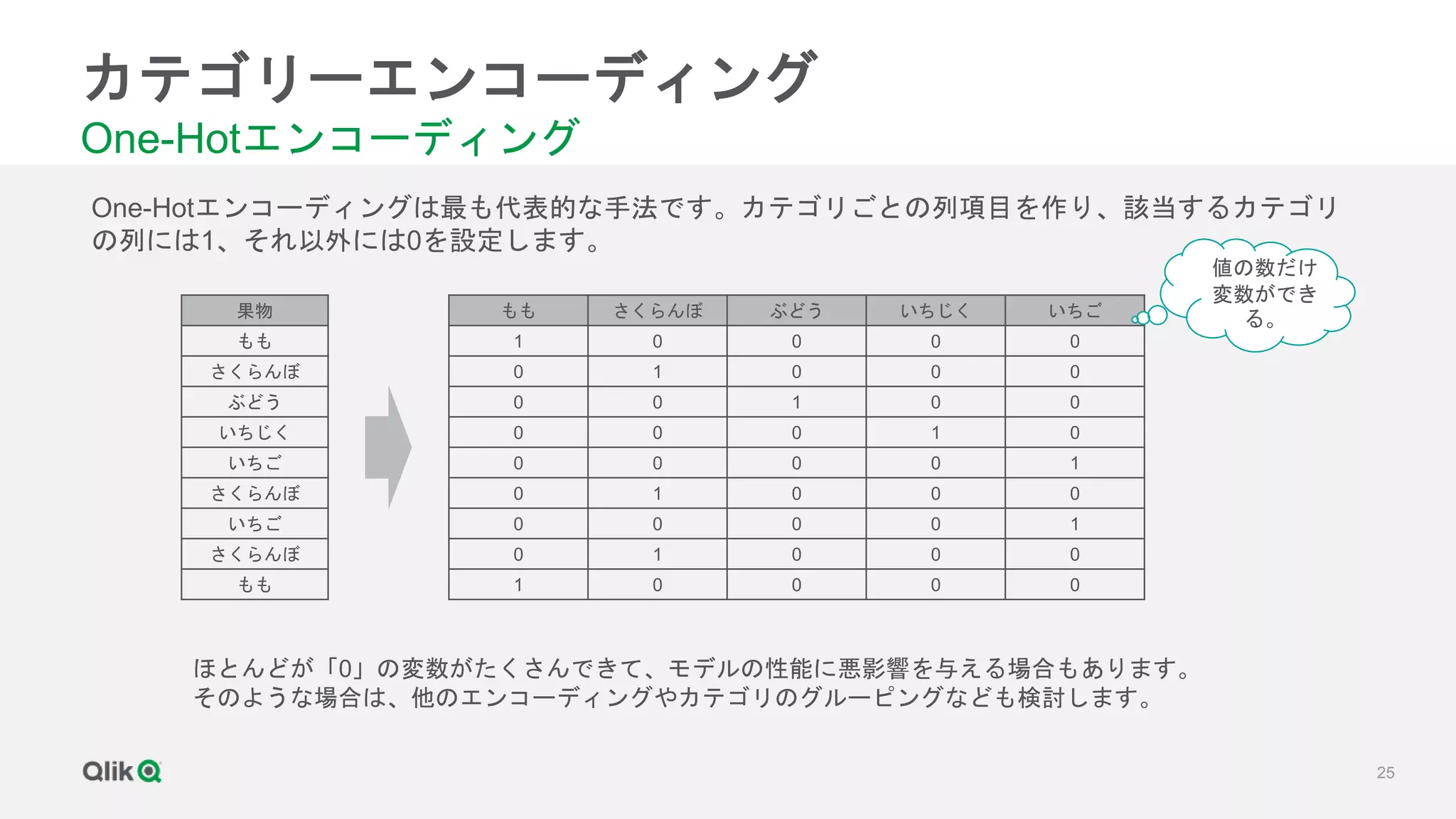
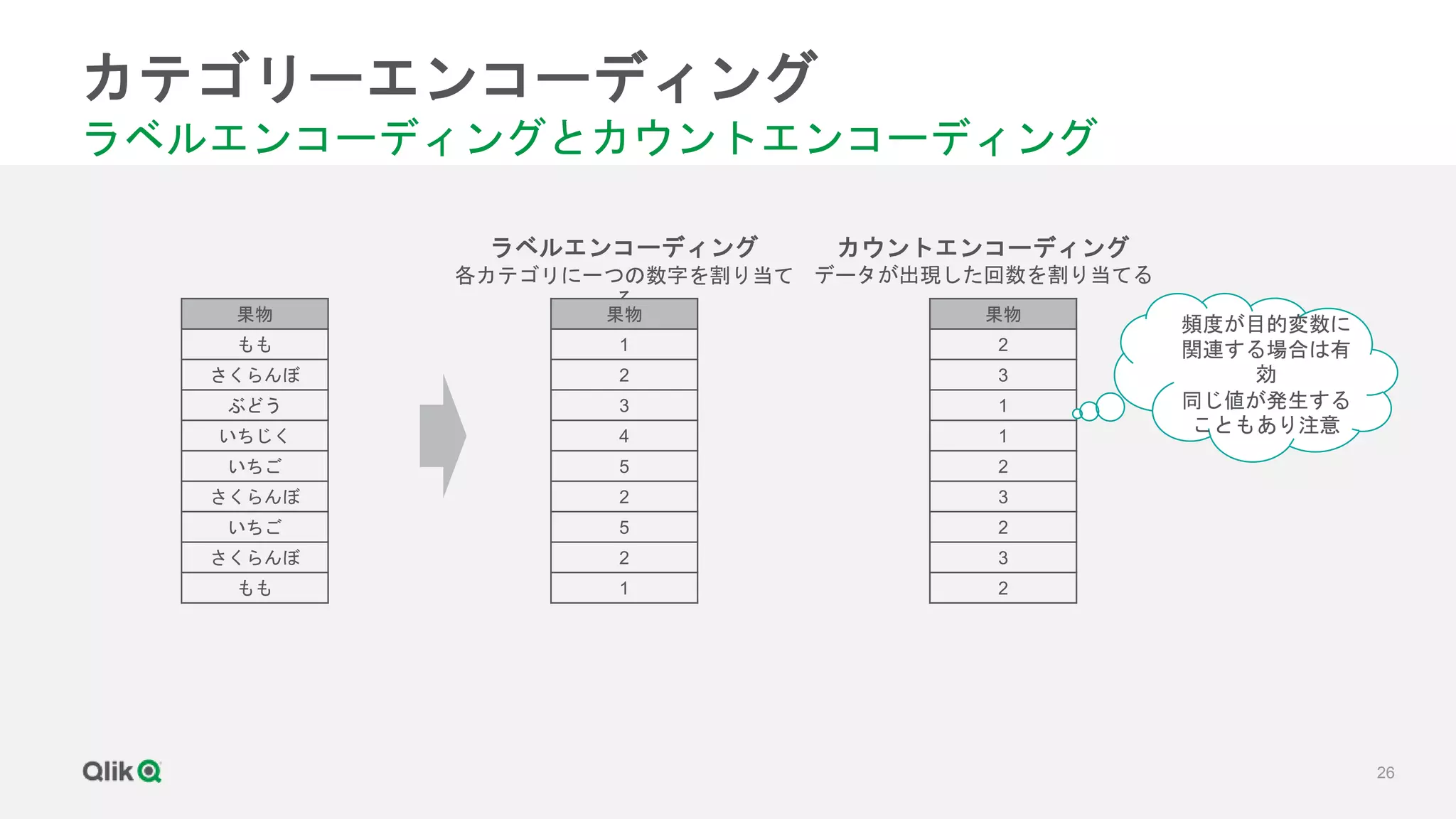




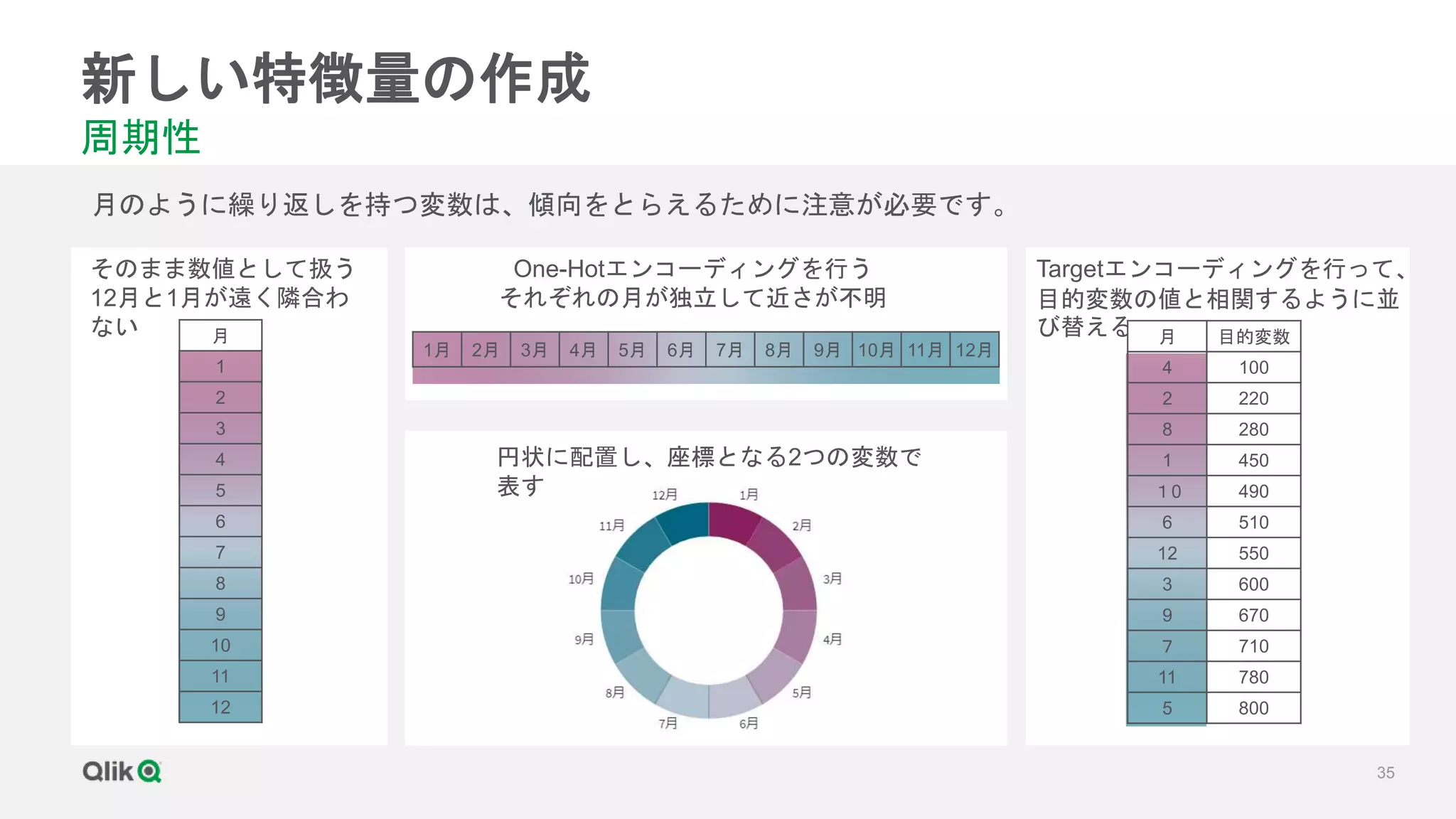
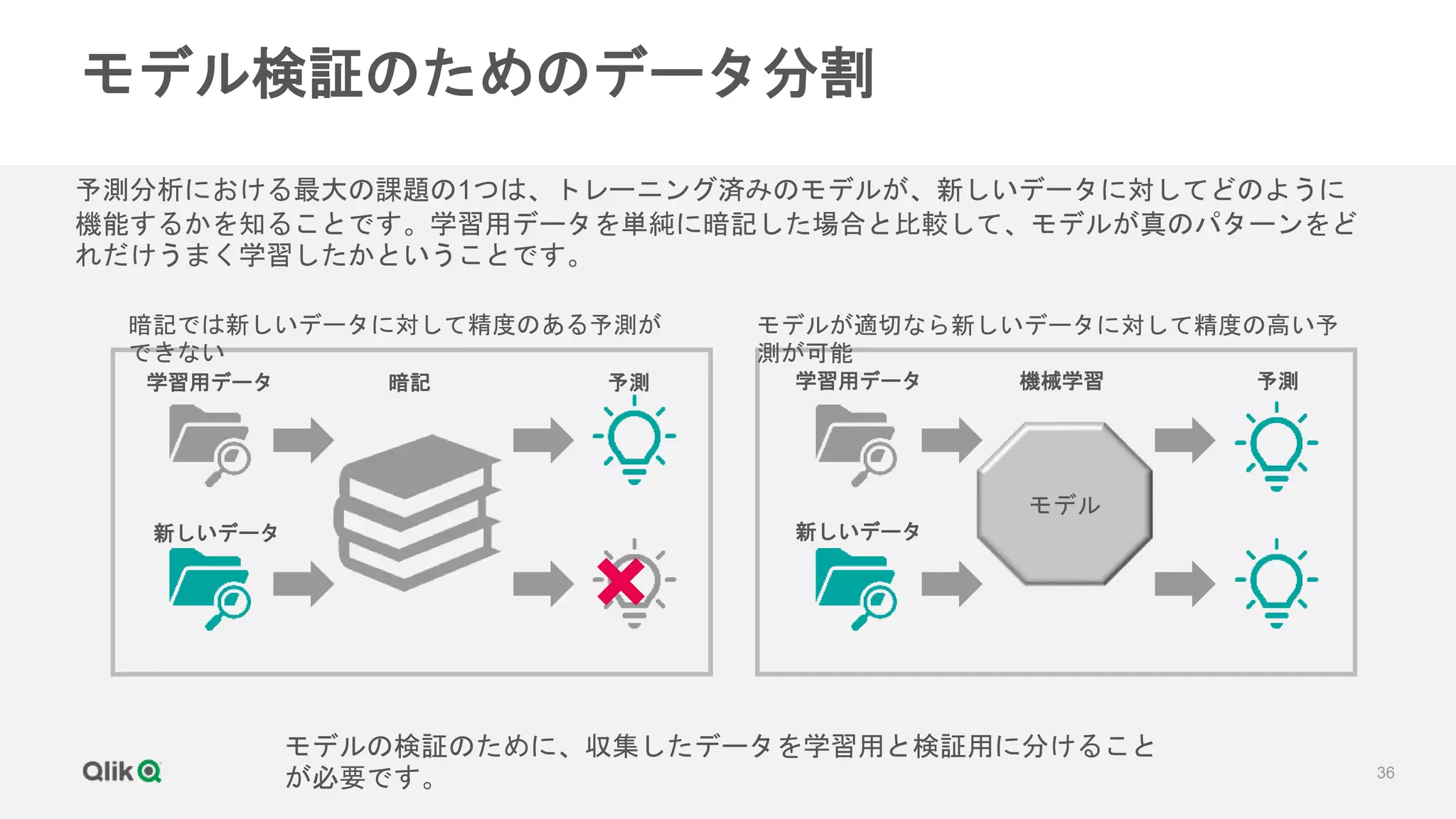
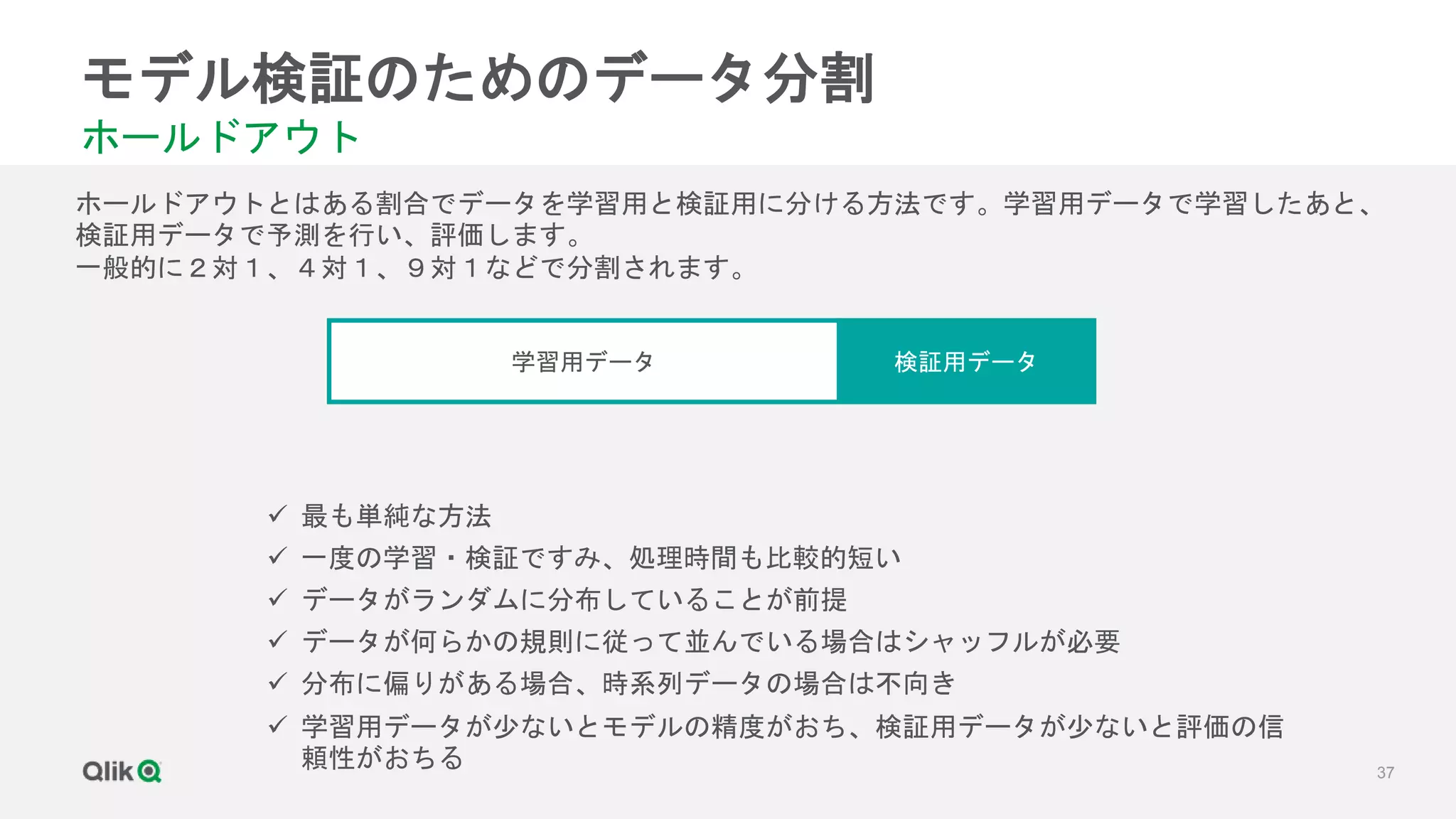
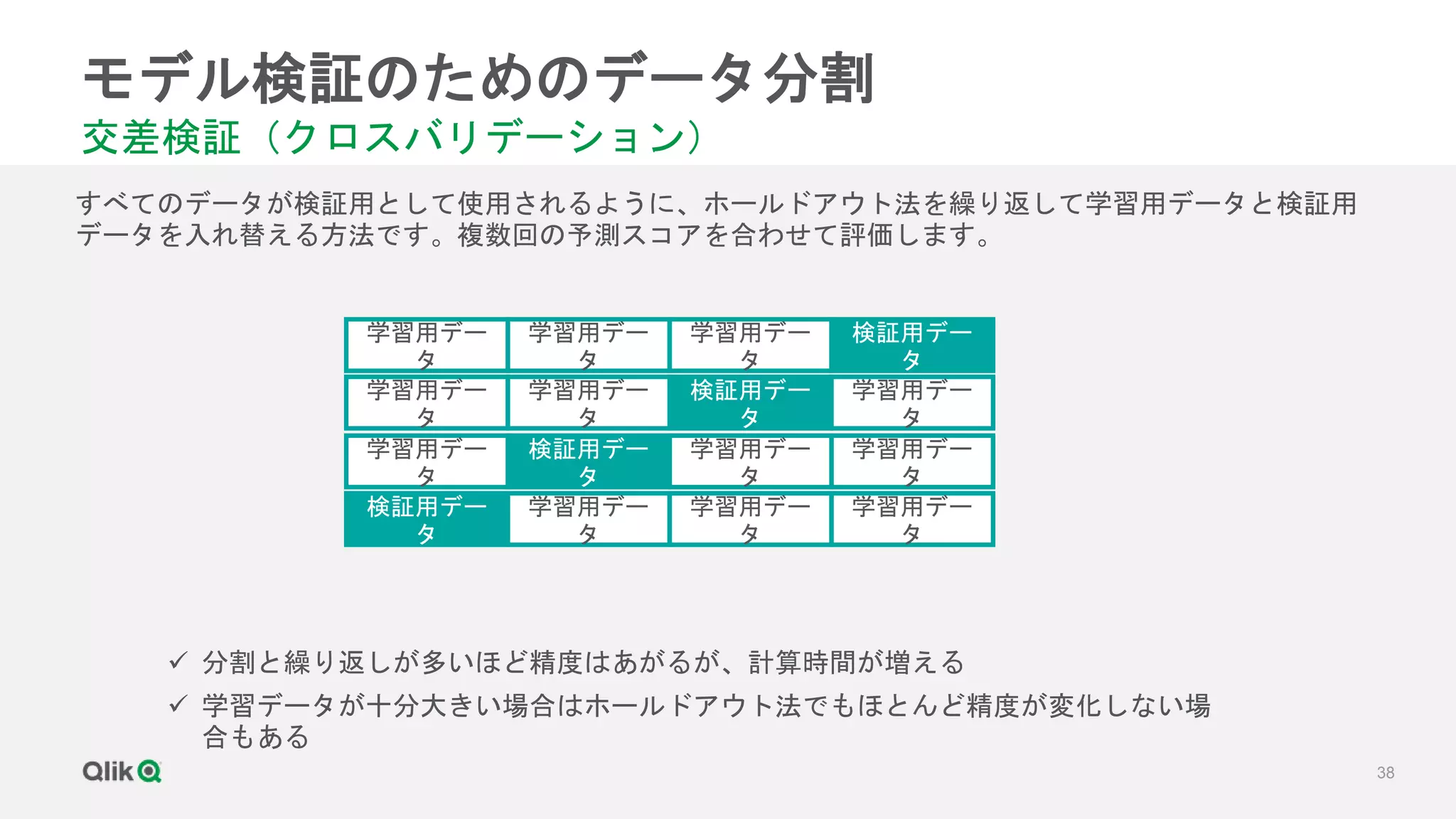









































![[輪講] 第1章](https://cdn.slidesharecdn.com/ss_thumbnails/random-171231020415-thumbnail.jpg?width=640&height=640&fit=bounds)




































