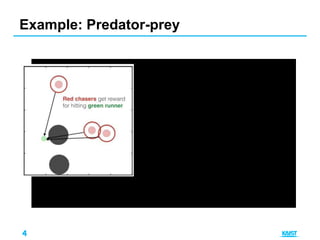
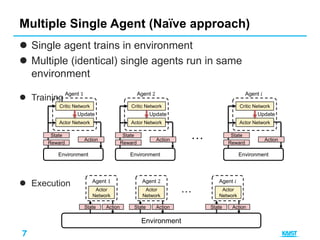
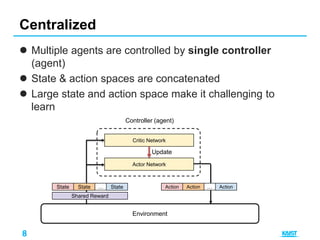
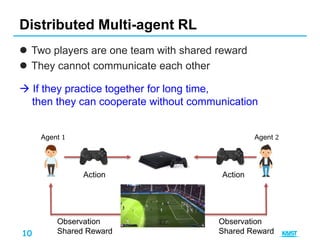
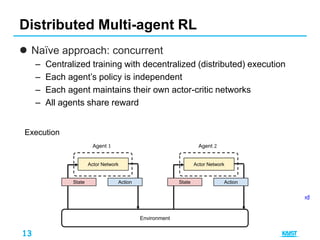
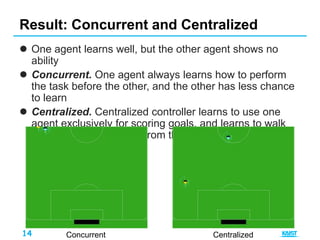
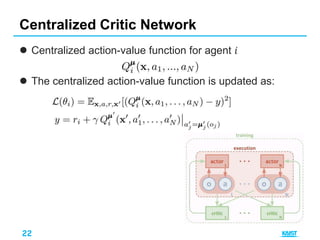
This document summarizes different approaches for multi-agent deep reinforcement learning. It discusses training multiple independent agents concurrently, centralized training with decentralized execution, and approaches that involve agent communication like parameter sharing and multi-agent deep deterministic policy gradient (MADDPG). MADDPG allows each agent to have its own reward function and trains agents centrally while executing decisions in a decentralized manner. The document provides examples of applying these methods to problems like predator-prey and uses the prisoners dilemma to illustrate how agents can learn communication protocols.







![15
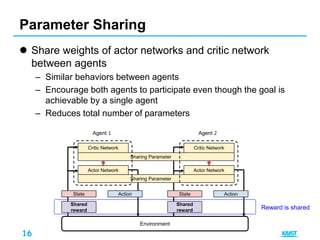
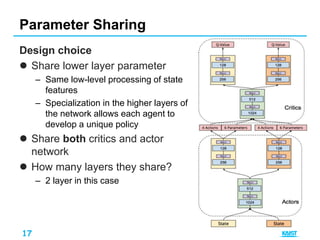
1. Parameter sharing [2]
– Agents share the weight of actor and critic network
– Update the network of agent who has less chance to learn
together
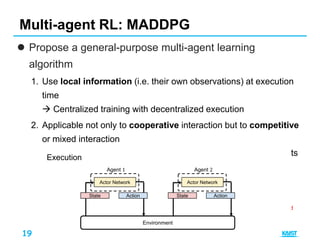
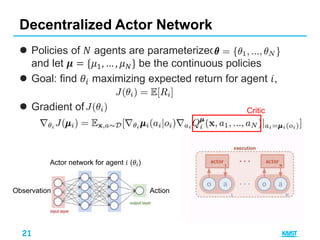
2. Multi-agent DDPG [3]
– Why agents share reward?
– Agents can have arbitrary reward structures, including
conflicting rewards in a competitive setting
– Observation is shared during training
Two Approaches
[2] Gupta, J. K., Egorov, M., Kochenderfer, M. “Cooperative Multi-Agent Control Using Deep
Reinforcement Learning”. Adaptive Learning Agents (ALA) 2017.
[3] Lowe, R., Wu, Y., Tamar, A., Harb, J., Abbeel, P., Mordatch, I. “Multi-Agent Actor-Critic for
Mixed Cooperative-Competitive Environments.” NIPS 2017](https://image.slidesharecdn.com/madrl-171214010649/85/Deep-Multi-agent-Reinforcement-Learning-15-320.jpg)



![24
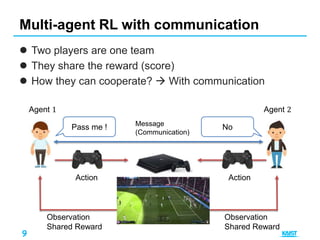
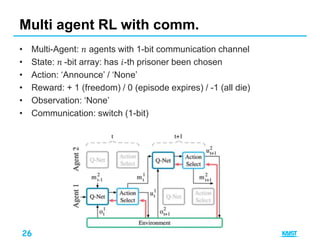
Multiple agents run in environment
Goal: Maximizing their shared utility
Improve performance with communication?
– What kind of information they should exchange?
– What if there is limited channel capacity among agents?
Multi-agent RL with communication[1]
Environment
Observation
Shared Reward
Agent 1
Message select
Action Observation
Shared Reward
Agent 2
Action
Action select
Message select
Action select
Message
Message
Reward is
shared
Limited capacity
[1] Foerster, J. N., Assael, Y. M., de Freitas, N., Whiteson, S. “Learning to Communicate with Deep Multi-Agent
Reinforcement Learning,” NIPS 2016](https://image.slidesharecdn.com/madrl-171214010649/85/Deep-Multi-agent-Reinforcement-Learning-24-320.jpg)















![[부스트캠프 Tech Talk] 신원지_Wandb Visualization](https://cdn.slidesharecdn.com/ss_thumbnails/boostcampaitechtechtalkshinwonji-211210113635-thumbnail.jpg?width=640&height=640&fit=bounds)





















































