Download as PDF, PPTX
















































![References
References I
[BV02] Michael H. Bowling and Manuela M. Veloso. “Multiagent
learning using a variable learning rate”. In: Artif. Intell. 136.2
(2002), pp. 215–250. doi:
10.1016/S0004-3702(02)00121-2. url:
https://doi.org/10.1016/S0004-3702(02)00121-2.
[DAn+19] Mirko D’Angelo et al. “On learning in collective self-adaptive
systems: state of practice and a 3D framework”. In: ACM,
2019, pp. 13–24. url:
https://doi.org/10.1109/SEAMS.2019.00012.
[Foe+18] Jakob N. Foerster et al. “Counterfactual Multi-Agent Policy
Gradients”. In: AAAI Press, 2018, pp. 2974–2982. url:
https://www.aaai.org/ocs/index.php/AAAI/AAAI18/
paper/view/17193.
Aguzzi (DISI, Univ. Bologna) On Collective Reinforcement Learning 13/12/2021](https://image.slidesharecdn.com/collective-learning-211220092449/85/On-Collective-Reinforcement-Learning-54-320.jpg)
![References
References II
[GD21] Sven Gronauer and Klaus Diepold. “Multi-agent deep
reinforcement learning: a survey”. In: Artificial Intelligence
Review (2021), pp. 1–49.
[Jad+18] Max Jaderberg et al. “Human-level performance in first-person
multiplayer games with population-based deep reinforcement
learning”. In: CoRR abs/1807.01281 (2018). arXiv:
1807.01281. url: http://arxiv.org/abs/1807.01281.
[KMP13] Soummya Kar, José M. F. Moura, and H. Vincent Poor.
“QD-Learning: A Collaborative Distributed Strategy for
Multi-Agent Reinforcement Learning Through Consensus +
Innovations”. In: IEEE Trans. Signal Process. 61.7 (2013),
pp. 1848–1862. url:
https://doi.org/10.1109/TSP.2013.2241057.
Aguzzi (DISI, Univ. Bologna) On Collective Reinforcement Learning 13/12/2021](https://image.slidesharecdn.com/collective-learning-211220092449/85/On-Collective-Reinforcement-Learning-55-320.jpg)
![References
References III
[Lon+18] Pinxin Long et al. “Towards Optimally Decentralized
Multi-Robot Collision Avoidance via Deep Reinforcement
Learning”. In: IEEE, 2018, pp. 6252–6259. url:
https://doi.org/10.1109/ICRA.2018.8461113.
[LR00] Martin Lauer and Martin A. Riedmiller. “An Algorithm for
Distributed Reinforcement Learning in Cooperative
Multi-Agent Systems”. In: Morgan Kaufmann, 2000,
pp. 535–542.
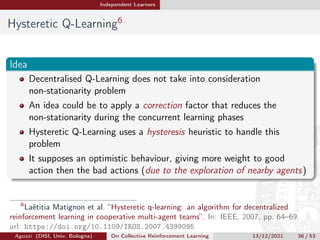
[MLL07] Laëtitia Matignon, Guillaume J Laurent, and
Nadine Le Fort-Piat. “Hysteretic q-learning: an algorithm for
decentralized reinforcement learning in cooperative multi-agent
teams”. In: IEEE, 2007, pp. 64–69. url:
https://doi.org/10.1109/IROS.2007.4399095.
Aguzzi (DISI, Univ. Bologna) On Collective Reinforcement Learning 13/12/2021](https://image.slidesharecdn.com/collective-learning-211220092449/85/On-Collective-Reinforcement-Learning-56-320.jpg)
![References
References IV
[NNN18] Thanh Thi Nguyen, Ngoc Duy Nguyen, and Saeid Nahavandi.
“Deep Reinforcement Learning for Multi-Agent Systems: A
Review of Challenges, Solutions and Applications”. In: CoRR
abs/1812.11794 (2018). arXiv: 1812.11794. url:
http://arxiv.org/abs/1812.11794.
[OH19] Afshin Oroojlooyjadid and Davood Hajinezhad. “A Review of
Cooperative Multi-Agent Deep Reinforcement Learning”. In:
CoRR abs/1908.03963 (2019). arXiv: 1908.03963. url:
http://arxiv.org/abs/1908.03963.
[Omi+17] Shayegan Omidshafiei et al. “Deep Decentralized Multi-task
Multi-Agent Reinforcement Learning under Partial
Observability”. In: vol. 70. Proceedings of Machine Learning
Research. PMLR, 2017, pp. 2681–2690. url: http:
//proceedings.mlr.press/v70/omidshafiei17a.html.
Aguzzi (DISI, Univ. Bologna) On Collective Reinforcement Learning 13/12/2021](https://image.slidesharecdn.com/collective-learning-211220092449/85/On-Collective-Reinforcement-Learning-57-320.jpg)
![References
References V
[PSL06] Liviu Panait, Keith Sullivan, and Sean Luke. “Lenient learners
in cooperative multiagent systems”. In: 5th International Joint
Conference on Autonomous Agents and Multiagent Systems
(AAMAS 2006), Hakodate, Japan, May 8-12, 2006. Ed. by
Hideyuki Nakashima et al. ACM, 2006, pp. 801–803. doi:
10.1145/1160633.1160776. url:
https://doi.org/10.1145/1160633.1160776.
[Sos+16] Adrian Sosic et al. “Inverse Reinforcement Learning in Swarm
Systems”. In: CoRR abs/1602.05450 (2016). arXiv:
1602.05450. url: http://arxiv.org/abs/1602.05450.
[TA07] Kagan Tumer and Adrian K. Agogino. “Distributed
agent-based air traffic flow management”. In: IFAAMAS, 2007,
p. 255. url: https://doi.org/10.1145/1329125.1329434.
Aguzzi (DISI, Univ. Bologna) On Collective Reinforcement Learning 13/12/2021](https://image.slidesharecdn.com/collective-learning-211220092449/85/On-Collective-Reinforcement-Learning-58-320.jpg)
![References
References VI
[Tan93] Ming Tan. “Multi-Agent Reinforcement Learning: Independent
versus Cooperative Agents”. In: ed. by Paul E. Utgoff. Morgan
Kaufmann, 1993, pp. 330–337. doi:
10.1016/b978-1-55860-307-3.50049-6. url: https:
//doi.org/10.1016/b978-1-55860-307-3.50049-6.
[TAW02] Kagan Tumer, Adrian K. Agogino, and David H. Wolpert.
“Learning sequences of actions in collectives of autonomous
agents”. In: ACM, 2002, pp. 378–385. url:
https://doi.org/10.1145/544741.544832.
[WS06] Ying Wang and Clarence W. de Silva. “Multi-robot
Box-pushing: Single-Agent Q-Learning vs. Team Q-Learning”.
In: IEEE, 2006, pp. 3694–3699. url:
https://doi.org/10.1109/IROS.2006.281729.
Aguzzi (DISI, Univ. Bologna) On Collective Reinforcement Learning 13/12/2021](https://image.slidesharecdn.com/collective-learning-211220092449/85/On-Collective-Reinforcement-Learning-59-320.jpg)
![References
References VII
[WT99] David H Wolpert and Kagan Tumer. “An introduction to
collective intelligence”. In: arXiv preprint cs/9908014 (1999).
[Yan+18] Yaodong Yang et al. “Mean Field Multi-Agent Reinforcement
Learning”. In: vol. 80. Proceedings of Machine Learning
Research. PMLR, 2018, pp. 5567–5576. url:
http://proceedings.mlr.press/v80/yang18d.html.
[ZB20] Alexander Zai and Brandon Brown. Deep reinforcement
learning in action. Manning Publications, 2020.
[Zhe+18] Lianmin Zheng et al. “MAgent: A many-agent reinforcement
learning platform for artificial collective intelligence”. In: 2018.
Aguzzi (DISI, Univ. Bologna) On Collective Reinforcement Learning 13/12/2021](https://image.slidesharecdn.com/collective-learning-211220092449/85/On-Collective-Reinforcement-Learning-60-320.jpg)

The document focuses on collective reinforcement learning (CRL) techniques, outlining the transition from single-agent to multi-agent systems, and discusses the associated challenges and opportunities. It covers concepts such as independent learners, joint action learners, and cooperative versus competitive tasks within multi-agent reinforcement learning (MARL). Additionally, it highlights issues such as non-stationary environments, the curse of dimensionality, and the multi-agent credit assignment problem that arise in collective adaptive systems (CAS).





















































