Download as PDF, PPTX






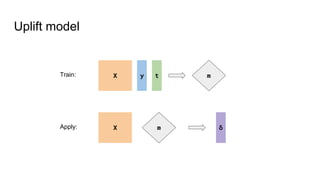
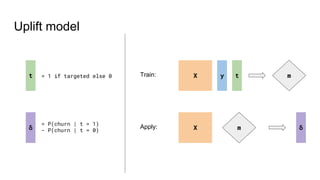
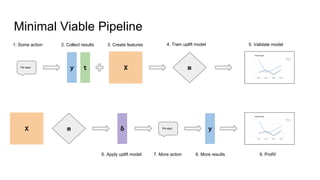


![Poor man’s uplift model
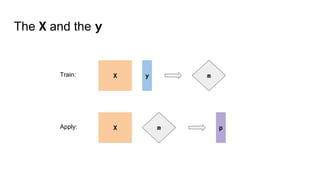
Split the dataset in two:
X_t = X[t=1], X_c = X[t=0]
y_t = y[t=1], y_c = y[t=0]
Train two models:
clf_t.fit(X_t, y_t), clf_c.fit(X_c, y_c)
Subtract:
δ = clf_t.predict_proba(X) - clf_c.predict_proba(X)](https://image.slidesharecdn.com/uplift-180223160451/85/Uplift-models-21-320.jpg)
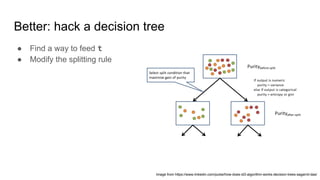




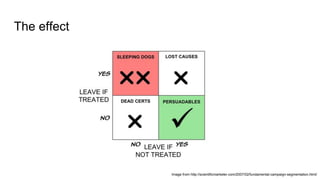
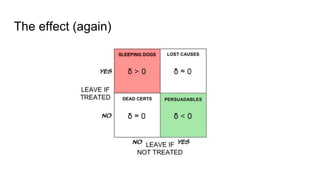
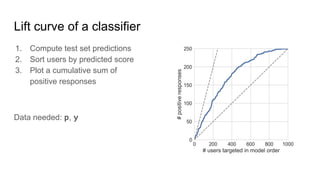
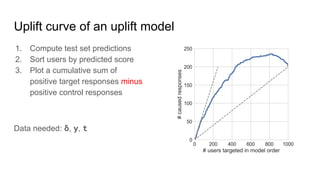
Uplift models directly model the impact of a treatment or intervention by predicting the difference in outcomes between treated and untreated groups, rather than just the overall outcome probabilities. They are trained on data that includes treatment assignment and outcomes. Validation is done using uplift curves rather than standard classification metrics, by plotting a cumulative sum of positive responses minus controls. Basic approaches include training separate models on treated and control groups then subtracting predictions, or modifying decision tree splitting to favor treatments with higher uplift. Ensemble methods like random forests can also be adapted for uplift modeling.























































































