Downloaded 28 times



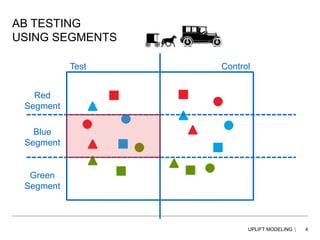
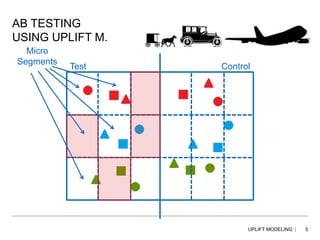
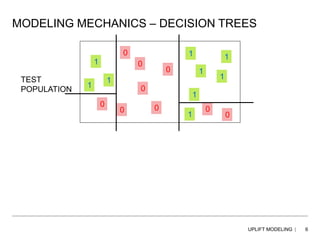




This document discusses uplift modeling using concurrent decision trees to identify customers who are most likely to improve a given metric, such as traffic, sales, or revenue, when targeted with a specific treatment. Traditional approaches target high propensity customers, but uplift modeling directly models the incremental impact of a treatment. The document explains how uplift trees work by identifying splits in a tree that show the greatest difference between test and control groups, and then recursively splitting subgroups, with the goal of finding statistically significant micro-segments. Key differences between uplift and traditional segmentation models are also outlined.



























