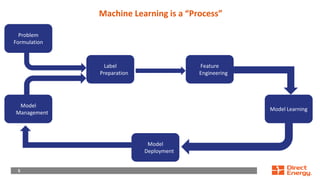
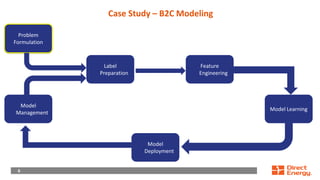
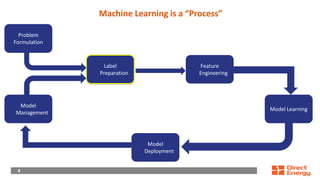
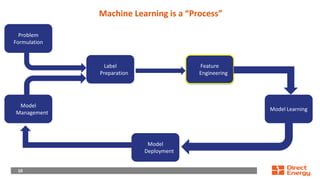
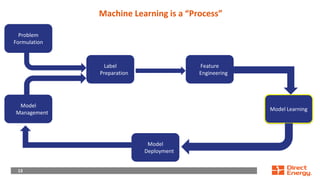
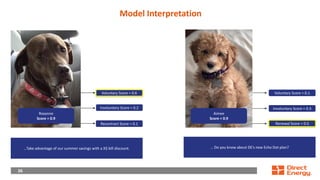
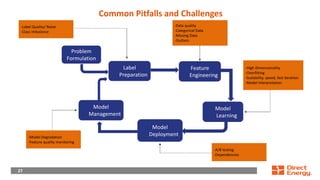
This document provides a walkthrough of using machine learning to build a model for predicting customer choice and churn. It discusses the key steps in the machine learning process including problem formulation, feature engineering, model learning, label preparation, and model deployment. For the case study of building a B2C prediction model, it describes collecting demographic and behavioral features from customer data and using gradient boosting machines for model learning. The goal is to build a model that can accurately predict individual customer choices like renewals over 30 and 120-day windows.