Download as PDF, PPTX



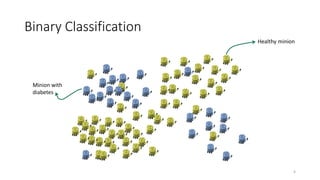

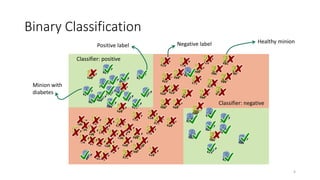



















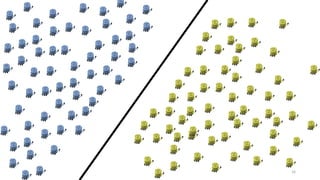




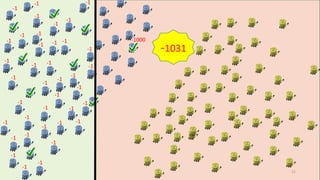


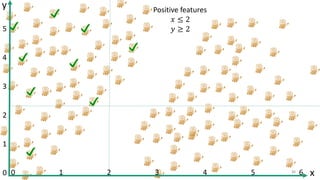


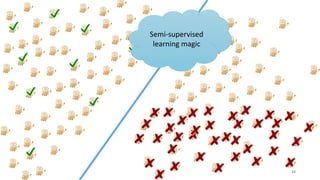


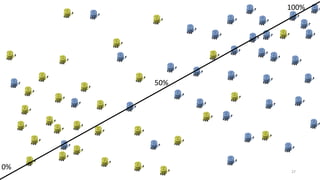
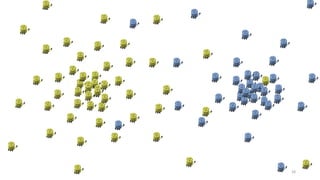
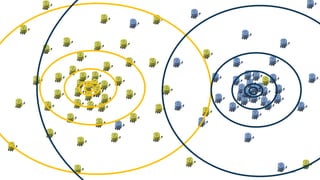




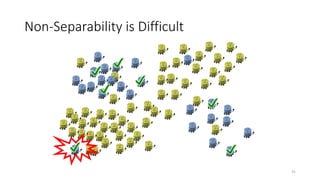



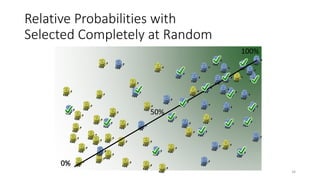






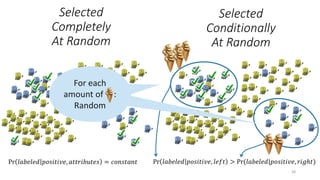






This document discusses learning from positive and unlabeled data. It presents three cases of increasing difficulty: linearly separable data where the unlabeled data can be considered negative, non-separable data where the labels are selected completely at random, and non-separable data where the labels are selected conditionally at random. For the linearly separable case, biased learning or two-step techniques can be used. For the random case, relative probabilities must be considered. For the conditionally random case, the propensity score function must be estimated or used. The goal is to make probabilistic predictions from positive and unlabeled data under different assumptions.






















![[DL輪読会]Estimating Predictive Uncertainty via Prior Networks](https://cdn.slidesharecdn.com/ss_thumbnails/estimatingpredictiveuncertaintyviapriornetworks-190628002736-thumbnail.jpg?width=640&height=640&fit=bounds)






















































![[DSC Europe 25] Slobodan Dolinic - Smart and Intelligent Green Region.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/0bribinjsp6ghwtvsvor-2-sigre-slobodan-dolinic-260115093812-c9c10e90-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Elena Menshikova - AI-Powered Operational Excellence: Revolut...](https://cdn.slidesharecdn.com/ss_thumbnails/es6nholbqy3zaao2c2yd-2-elena-menshikova-data-ai-in-decision-making-260115093812-4fba8b38-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Mijat Kustudic - Building Financial Intelligence with AI Agen...](https://cdn.slidesharecdn.com/ss_thumbnails/38y2lb5lse6wstegtvas-3-mijat-kustudic-building-financial-intelligence-with-ai-agents-260114111931-1a4783ce-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Ivan Lukovic & Marija Djukic - From Data to Value: Why Maturi...](https://cdn.slidesharecdn.com/ss_thumbnails/ahrfps8xr6knowwhacxh-1-ivan-marija-dsc-2025-ld-v1-presentation-260115093812-be21adfc-thumbnail.jpg?width=640&height=640&fit=bounds)



