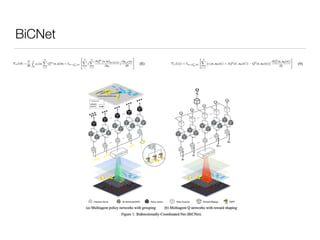
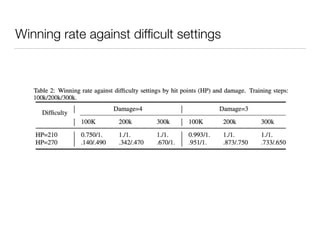
The document summarizes a presentation on a paper about using multiagent bidirectional-coordinated networks (BiCNet) to develop AI agents that can learn to play combat games in StarCraft. The paper introduces BiCNet, which uses bidirectional RNNs to allow agents to communicate and coordinate their actions. Experiments show BiCNet agents outperform independent and other cooperative agents in different combat scenarios in StarCraft, developing strategies like focus firing and coordinated attacks. Visualizations of agent coordination and additional areas for investigation are also discussed.







![Stochastic Game of N agents and M opponents
• S agent state space
• Ai Controller agent i action space, i ∈ [1, N]
• Bj enemy j action space, j ∈ [1, M]
• T : S x A
N
x B
M
-> S environment deterministic transition
function
• Ri : S x A
N
x B
M
-> R agent/enemy i reward function, i ∈ [1, N+M]
* agent( , ) action space .](https://image.slidesharecdn.com/multiagentbidirectional-coordinatednetsforlearningtoplaystarcraftcombatgames-170623022918/85/Multiagent-Bidirectional-Coordinated-Nets-for-Learning-to-Play-StarCraft-Combat-Games-13-320.jpg)





























![[한국어] Safe Multi-Agent Reinforcement Learning for Autonomous Driving](https://cdn.slidesharecdn.com/ss_thumbnails/safemultiagentrlforautonomousedriving4-170508165059-thumbnail.jpg?width=640&height=640&fit=bounds)
















![[한국어] Neural Architecture Search with Reinforcement Learning](https://cdn.slidesharecdn.com/ss_thumbnails/nas-170612232020-thumbnail.jpg?width=640&height=640&fit=bounds)







![[BIZ+005 스타트업 투자/법률 기초편] 첫 투자를 위한 스타트업 기초상식 | 비즈업 조가연님](https://cdn.slidesharecdn.com/ss_thumbnails/5ckl-170317080235-thumbnail.jpg?width=640&height=640&fit=bounds)

































![[DSC Europe 25] Josip Saban - Career building for data professionals.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/zroflcttkm1vmli0txea-josip-saban-career-building-for-data-professionals-260123083019-587cdb8c-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Andrzej Kowalczyk - AI - how to start small and grow in the f...](https://cdn.slidesharecdn.com/ss_thumbnails/oy1zmo94qv6vpcqjvno2-andrzej-kowalczyk-ai-how-to-start-small-and-grow-in-the-future-1-260119121559-cf093b23-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Marcos Heidemann - Beyond the Hype: Making AI Coding Assistan...](https://cdn.slidesharecdn.com/ss_thumbnails/eexkhvldrjsopspdjbur-marcos-heidemann-beyond-the-hype-getting-real-value-out-of-ai-assisted-coding-260121115910-7e9d41ec-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DSC Europe 25] Laila Kakar - Leveraging AI for Strategic Excellence: Enhanci...](https://cdn.slidesharecdn.com/ss_thumbnails/eykmhrtsqmaaftwkexh7-dsc-lailakakar-1-260119101520-5f3b5616-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Bojan Banjac - AI is always right when it comes to the matter...](https://cdn.slidesharecdn.com/ss_thumbnails/syoxtqierpydwxm5srcb-4-bojan-banjac-ai-is-always-right-when-it-comes-to-the-matters-of-taste-260119101519-694ee7d7-thumbnail.jpg?width=640&height=640&fit=bounds)




