Download to read offline


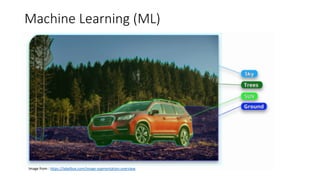
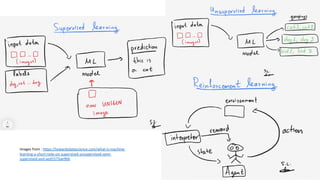

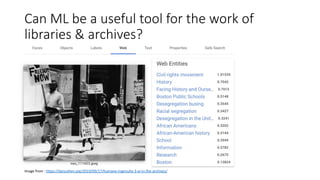




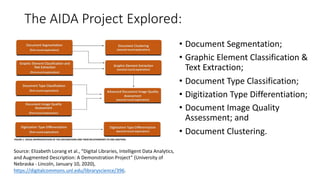



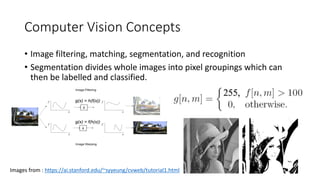








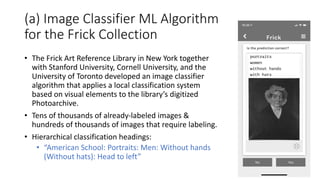

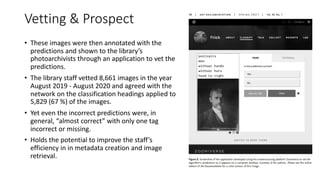





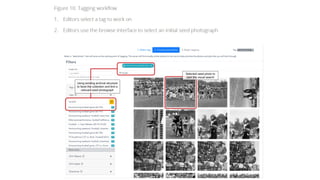













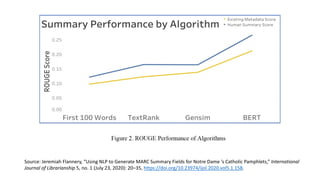







The document discusses several ways machine learning (ML) could be used to enhance the work of libraries and archives. It describes projects that used ML for expediting archival processing through tasks like document segmentation and classification. It also discusses using ML to expand descriptive metadata by generating image classifiers and facilitating tagging of photograph collections. Further, it outlines a project aiming to generate and manage rich metadata for audiovisual materials at scale using ML techniques like speech recognition.










































































