Download as PDF, PPTX





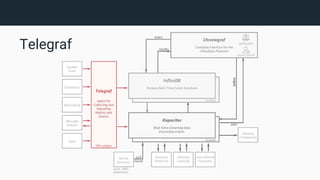
![Telegraf
● Understand Telegraf output:
$ telegraf --config telegraf.conf --input-filter cpu --test
[measurement],[tag1,tag2] [field1,field2,field3] [timestamp]
system,host=tux,env=prod load1=1.25,load5=1.27,load15=1.29 1509997632000000000](https://image.slidesharecdn.com/introduction-to-influxdb-and-tick-stack-171108225610/85/Introduction-to-InfluxDB-and-TICK-Stack-11-320.jpg)
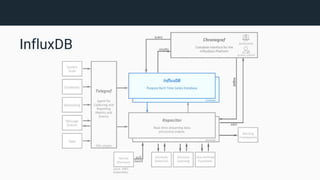

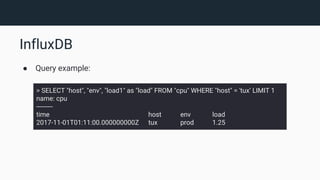
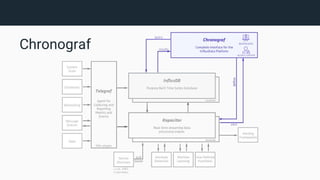

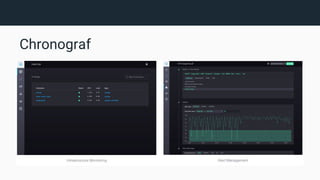
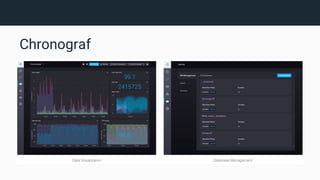
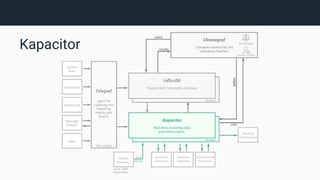





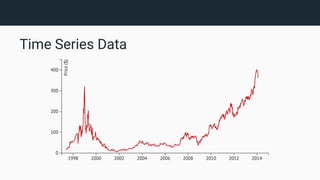
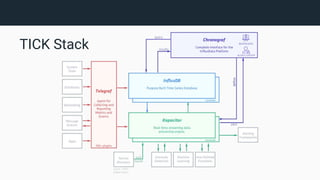
The document provides an introduction to InfluxDB and the TICK stack (Telegraf, InfluxDB, Chronograf, Kapacitor), which is designed for managing and analyzing time series data. It outlines the characteristics of time series data and the functions of each component in the stack, emphasizing their capabilities in data collection, storage, visualization, and processing. Additionally, it highlights potential use cases such as infrastructure monitoring and anomaly detection.






































![Paul Dix [InfluxData] | InfluxDays Keynote: Future of InfluxDB | InfluxDays N...](https://cdn.slidesharecdn.com/ss_thumbnails/2021-10-26whytimeseries-influxdaysna-211026005527-thumbnail.jpg?width=640&height=640&fit=bounds)

![Paul Dix [InfluxData] | InfluxDays Opening Keynote | InfluxDays Virtual Exper...](https://cdn.slidesharecdn.com/ss_thumbnails/2020-11-10influxdays-introducinginfluxdbiox-201110182839-thumbnail.jpg?width=640&height=640&fit=bounds)



![Paul Dix [InfluxData] The Journey of InfluxDB | InfluxDays 2022](https://cdn.slidesharecdn.com/ss_thumbnails/2022-11-02influxdays-journeyofinfluxdb-221020214252-ff7c76c5-thumbnail.jpg?width=640&height=640&fit=bounds)
































