Downloaded 10 times













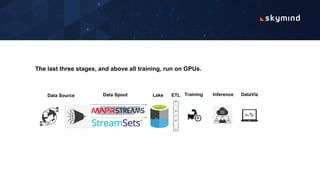






Network intrusion detection uses deep learning to analyze network traffic logs and detect anomalous activity that could indicate hackers. The logs are preprocessed and fed into a neural network to be analyzed in batches on a GPU cluster. The trained model can then detect intrusions in new incoming log data from multiple sources in real-time and help network administrators find malicious traffic on the network.































































































![[DSC Europe 25] Milos Belcevic - Product Professional's Journey to Full-Stack...](https://cdn.slidesharecdn.com/ss_thumbnails/1zovd6fgsycdg4wvgvls-milos-belcevic-product-professionals-journey-to-full-stack-product-developer-260123083019-d993120d-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Josip Saban - Career building for data professionals.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/zroflcttkm1vmli0txea-josip-saban-career-building-for-data-professionals-260123083019-587cdb8c-thumbnail.jpg?width=640&height=640&fit=bounds)