Downloaded 35 times



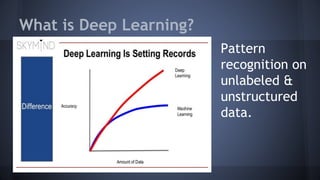





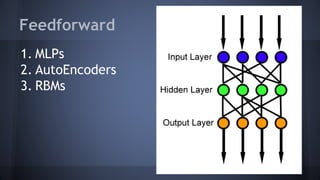
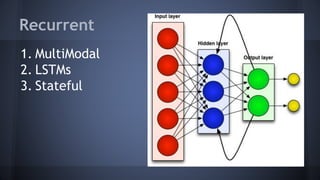

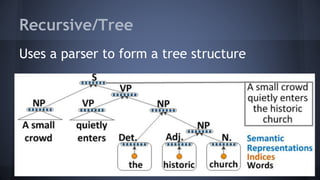



















This document provides an overview of deep learning, including what it is, why it is difficult, and problems to consider. Deep learning uses neural networks with 3 or more layers to perform pattern recognition on unlabeled and unstructured data like images and text. It is computationally intensive and requires large datasets and specialized hardware like GPUs. Some challenges include dealing with messy real-world data, scaling networks across large clusters, combining different neural network types, and tuning hyperparameters.










































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)










