Downloaded 96 times







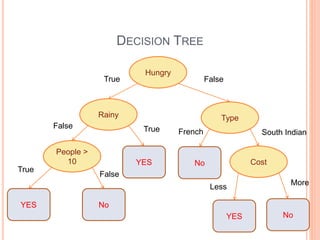

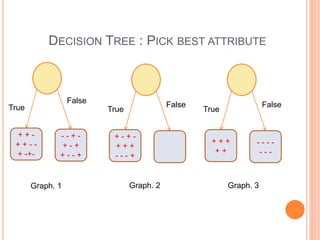



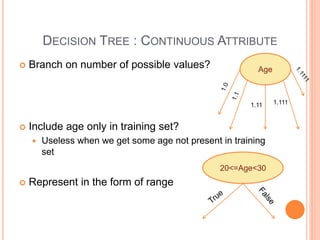
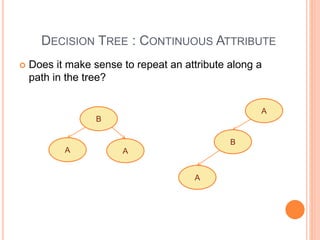












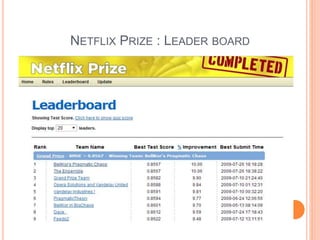
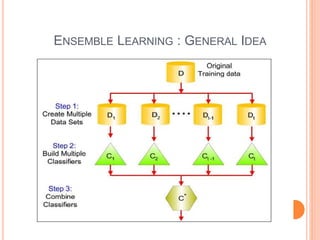











This document discusses decision trees, softmax regression, and ensemble methods in machine learning. It provides details on how decision trees use information gain to split nodes based on attributes. Softmax regression is described as a generalization of logistic regression for multi-class classification problems. Ensemble methods like bagging, random forests, and boosting are covered as techniques that improve performance by combining multiple models.













![ViT (Vision Transformer) Review [CDM]](https://cdn.slidesharecdn.com/ss_thumbnails/vitreviewcdm-201012184226-thumbnail.jpg?width=640&height=640&fit=bounds)







































![[ppt]](https://cdn.slidesharecdn.com/ss_thumbnails/ppt2931-thumbnail.jpg?width=640&height=640&fit=bounds)





![Hacking-Uncovered-How-People-Get-Hacked-and-How-to-Stay-Safe[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/hacking-uncovered-how-people-get-hacked-and-how-to-stay-safe1-260130170011-4883a9c7-thumbnail.jpg?width=640&height=640&fit=bounds)













