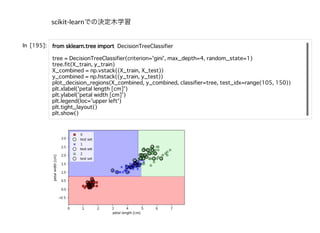
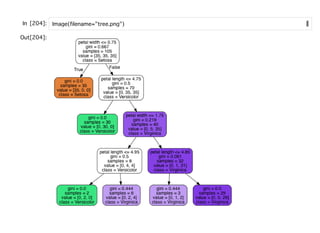
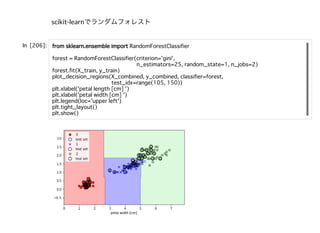
scikit-learnの線形モデル(40個くらいある)scikit-learnの線形モデル(40個くらいある)
linear_model.LogisticRegression([penalty, …]):Logistic Regression(aka logit,
MaxEnt) classi er.
linear_model.LogisticRegressionCV([Cs, …]):Logistic Regression CV (aka logit,
MaxEnt) classi er.
linear_model.PassiveAggressiveClassi er([…]):Passive Aggressive Classi er
linear_model.Perceptron([penalty, alpha, …]):Read more in the User Guide.
linear_model.RidgeClassi er([alpha, …]):Classi er using Ridge regression.
linear_model.RidgeClassi erCV([alphas, …]):Ridge classi er with built-in cross-
validation.
linear_model.SGDClassi er([loss, penalty, …]):Linear classi ers (SVM, logistic
regression, a.o.) with SGD training.
linear_model.LinearRegression([…]):Ordinary least squares Linear Regression.
linear_model.Ridge([alpha, t_intercept, …]):Linear least squares with l2
regularization.
linear_model.RidgeCV([alphas, …]):Ridge regression with built-in cross-
validation.
linear_model.SGDRegressor([loss, penalty, …]):Linear model tted by
minimizing a regularized empirical loss with SGD
8.
linear_model.ElasticNet([alpha, l1_ratio, …]):Linearregression with combined L1
and L2 priors as regularizer.
linear_model.ElasticNetCV([l1_ratio, eps, …]):Elastic Net model with iterative
tting along a regularization path.
linear_model.Lars([ t_intercept, verbose, …]):Least Angle Regression model
a.k.a.
linear_model.LarsCV([ t_intercept, …]):Cross-validated Least Angle Regression
model.
linear_model.Lasso([alpha, t_intercept, …]):Linear Model trained with L1 prior
as regularizer (aka the Lasso)
linear_model.LassoCV([eps, n_alphas, …]):Lasso linear model with iterative
tting along a regularization path.
linear_model.LassoLars([alpha, …]):Lasso model t with Least Angle Regression
a.k.a.
linear_model.LassoLarsCV([ t_intercept, …]):Cross-validated Lasso, using the
LARS algorithm.
linear_model.LassoLarsIC([criterion, …]):Lasso model t with Lars using BIC or
AIC for model selection
linear_model.OrthogonalMatchingPursuit([…]):Orthogonal Matching Pursuit
model (OMP)
linear_model.OrthogonalMatchingPursuitCV([…]):Cross-validated Orthogonal
Matching Pursuit model (OMP).
9.
linear_model.ARDRegression([n_iter, tol, …]):BayesianARD regression.
linear_model.BayesianRidge([n_iter, tol, …]):Bayesian ridge regression.
linear_model.MultiTaskElasticNet([alpha, …]):Multi-task ElasticNet model
trained with L1/L2 mixed-norm as regularizer
linear_model.MultiTaskElasticNetCV([…]):Multi-task L1/L2 ElasticNet with
built-in cross-validation.
linear_model.MultiTaskLasso([alpha, …]):Multi-task Lasso model trained with
L1/L2 mixed-norm as regularizer.
linear_model.MultiTaskLassoCV([eps, …]):Multi-task Lasso model trained with
L1/L2 mixed-norm as regularizer.
10.
linear_model.HuberRegressor([epsilon, …]):Linear regressionmodel that is
robust to outliers.
linear_model.RANSACRegressor([…]):RANSAC (RANdom SAmple Consensus)
algorithm.
linear_model.TheilSenRegressor([…]):Theil-Sen Estimator: robust multivariate
regression model.
linear_model.PassiveAggressiveRegressor([C, …]):Passive Aggressive Regressor
linear_model.enet_path(X, y[, l1_ratio, …]):Compute elastic net path with
coordinate descent.
linear_model.lars_path(X, y[, Xy, Gram, …]):Compute Least Angle Regression or
Lasso path using LARS algorithm [1]
linear_model.lars_path_gram(Xy, Gram, n_samples):lars_path in the suf cient
stats mode [1]
linear_model.lasso_path(X, y[, eps, …]):Compute Lasso path with coordinate
descent
linear_model.orthogonal_mp(X, y[, …]):Orthogonal Matching Pursuit (OMP)
linear_model.orthogonal_mp_gram(Gram, Xy[, …]):Gram Orthogonal Matching
Pursuit (OMP)
linear_model.ridge_regression(X, y, alpha[, …]):Solve the ridge equation by the
method of normal equations.
![[DSO] Machine Learning Seminar Vol.2[DSO] Machine Learning Seminar Vol.2
2020-02-xx
SKUE](https://image.slidesharecdn.com/chapter3slides-200226170409/85/DSO-Machine-Learning-Seminar-Vol-2-Chapter-3-1-320.jpg)
![[DSO] Machine Learning Seminar Vol.2[DSO] Machine Learning Seminar Vol.2
2020-02-xx
SKUE](https://image.slidesharecdn.com/chapter3slides-200226170409/75/DSO-Machine-Learning-Seminar-Vol-2-Chapter-3-1-2048.jpg)




![scikit-learnの線形モデル(40個くらいある)scikit-learnの線形モデル(40個くらいある)
linear_model.LogisticRegression([penalty, …]):Logistic Regression (aka logit,
MaxEnt) classi er.
linear_model.LogisticRegressionCV([Cs, …]):Logistic Regression CV (aka logit,
MaxEnt) classi er.
linear_model.PassiveAggressiveClassi er([…]):Passive Aggressive Classi er
linear_model.Perceptron([penalty, alpha, …]):Read more in the User Guide.
linear_model.RidgeClassi er([alpha, …]):Classi er using Ridge regression.
linear_model.RidgeClassi erCV([alphas, …]):Ridge classi er with built-in cross-
validation.
linear_model.SGDClassi er([loss, penalty, …]):Linear classi ers (SVM, logistic
regression, a.o.) with SGD training.
linear_model.LinearRegression([…]):Ordinary least squares Linear Regression.
linear_model.Ridge([alpha, t_intercept, …]):Linear least squares with l2
regularization.
linear_model.RidgeCV([alphas, …]):Ridge regression with built-in cross-
validation.
linear_model.SGDRegressor([loss, penalty, …]):Linear model tted by
minimizing a regularized empirical loss with SGD](https://image.slidesharecdn.com/chapter3slides-200226170409/85/DSO-Machine-Learning-Seminar-Vol-2-Chapter-3-7-320.jpg)
![linear_model.ElasticNet([alpha, l1_ratio, …]):Linear regression with combined L1
and L2 priors as regularizer.
linear_model.ElasticNetCV([l1_ratio, eps, …]):Elastic Net model with iterative
tting along a regularization path.
linear_model.Lars([ t_intercept, verbose, …]):Least Angle Regression model
a.k.a.
linear_model.LarsCV([ t_intercept, …]):Cross-validated Least Angle Regression
model.
linear_model.Lasso([alpha, t_intercept, …]):Linear Model trained with L1 prior
as regularizer (aka the Lasso)
linear_model.LassoCV([eps, n_alphas, …]):Lasso linear model with iterative
tting along a regularization path.
linear_model.LassoLars([alpha, …]):Lasso model t with Least Angle Regression
a.k.a.
linear_model.LassoLarsCV([ t_intercept, …]):Cross-validated Lasso, using the
LARS algorithm.
linear_model.LassoLarsIC([criterion, …]):Lasso model t with Lars using BIC or
AIC for model selection
linear_model.OrthogonalMatchingPursuit([…]):Orthogonal Matching Pursuit
model (OMP)
linear_model.OrthogonalMatchingPursuitCV([…]):Cross-validated Orthogonal
Matching Pursuit model (OMP).](https://image.slidesharecdn.com/chapter3slides-200226170409/85/DSO-Machine-Learning-Seminar-Vol-2-Chapter-3-8-320.jpg)
![linear_model.ARDRegression([n_iter, tol, …]):Bayesian ARD regression.
linear_model.BayesianRidge([n_iter, tol, …]):Bayesian ridge regression.
linear_model.MultiTaskElasticNet([alpha, …]):Multi-task ElasticNet model
trained with L1/L2 mixed-norm as regularizer
linear_model.MultiTaskElasticNetCV([…]):Multi-task L1/L2 ElasticNet with
built-in cross-validation.
linear_model.MultiTaskLasso([alpha, …]):Multi-task Lasso model trained with
L1/L2 mixed-norm as regularizer.
linear_model.MultiTaskLassoCV([eps, …]):Multi-task Lasso model trained with
L1/L2 mixed-norm as regularizer.](https://image.slidesharecdn.com/chapter3slides-200226170409/85/DSO-Machine-Learning-Seminar-Vol-2-Chapter-3-9-320.jpg)
![linear_model.HuberRegressor([epsilon, …]):Linear regression model that is
robust to outliers.
linear_model.RANSACRegressor([…]):RANSAC (RANdom SAmple Consensus)
algorithm.
linear_model.TheilSenRegressor([…]):Theil-Sen Estimator: robust multivariate
regression model.
linear_model.PassiveAggressiveRegressor([C, …]):Passive Aggressive Regressor
linear_model.enet_path(X, y[, l1_ratio, …]):Compute elastic net path with
coordinate descent.
linear_model.lars_path(X, y[, Xy, Gram, …]):Compute Least Angle Regression or
Lasso path using LARS algorithm [1]
linear_model.lars_path_gram(Xy, Gram, n_samples):lars_path in the suf cient
stats mode [1]
linear_model.lasso_path(X, y[, eps, …]):Compute Lasso path with coordinate
descent
linear_model.orthogonal_mp(X, y[, …]):Orthogonal Matching Pursuit (OMP)
linear_model.orthogonal_mp_gram(Gram, Xy[, …]):Gram Orthogonal Matching
Pursuit (OMP)
linear_model.ridge_regression(X, y, alpha[, …]):Solve the ridge equation by the
method of normal equations.](https://image.slidesharecdn.com/chapter3slides-200226170409/85/DSO-Machine-Learning-Seminar-Vol-2-Chapter-3-10-320.jpg)



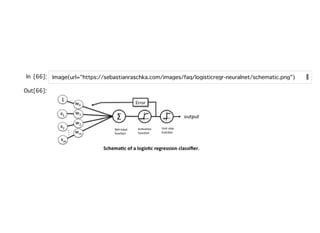

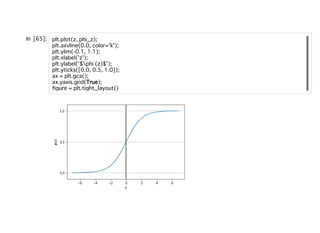



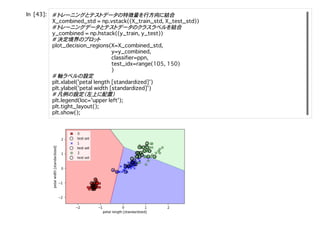
![重みの学習重みの学習
前章(2章)では誤差平⽅和をコスト関数としてそれを最⼩にするパラメータを勾配
降下法・確率的勾配降下法により求めていった。ロジスティック回帰モデルの場合は
尤度関数を⽬的関数として、それの最⼤化を⾏う。
尤度とはパラメータが与えられたもとでの、データの出現しやすさを表している。
今、⾃分の⽬の前にデータがあるが、そのデータは特定の分布から発⽣して、実際に
観測されるものは発⽣しやすいものだろうとする考え⽅に従っている。(頻度主義)
考え⽅
データがある
発⽣しやすいからこそ観測されたと考える
特定の分布を仮定する
発⽣しやすさ(尤度)が最も⾼くなるよ
うパラメータを決める(尤度関数の最適
化)
尤度関数は以下のように表される。
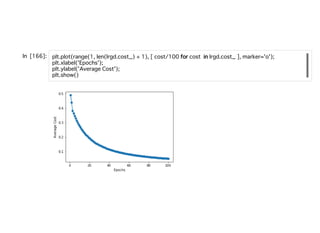
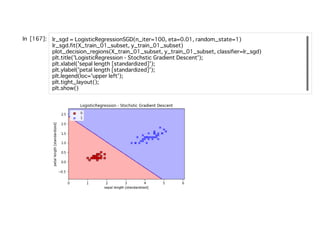
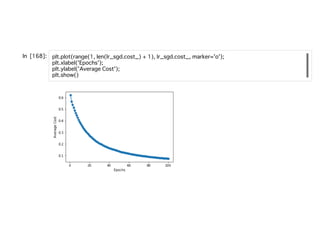
計算のしやすさから、これの対数をとった対数尤度の最⼤化を⾏っていく。
L(w) = P(y|x; w) = P( | ; w) = (ϕ( ) (1 − ϕ( )
∏
i=1
n
y
(i)
x
(i)
∏
i=1
n
z
(i)
)
y
(i)
z
(i)
)
1−y
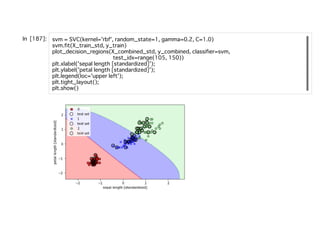
(i)
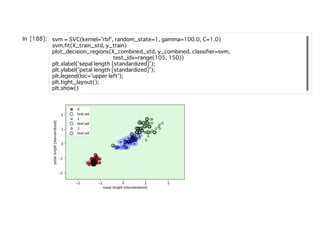
l(w) = log L(w) = [ log(ϕ( )) + (1 − ) log(1 − ϕ( ))]
∑
i=1
n
y
(i)
z
(i)
y
(i)
z
(i)](https://image.slidesharecdn.com/chapter3slides-200226170409/85/DSO-Machine-Learning-Seminar-Vol-2-Chapter-3-20-320.jpg)

![勾配降下法などで最⼩化するためのコスト関数として対数尤度を書き換える勾配降下法などで最⼩化するためのコスト関数として対数尤度を書き換える
最⼤化の関数に-1をかければ最⼩化の問題に置き換えることができる。
理解がしやすいようにインスタンスが⼀つのケースを⾒てみると
ラベルであるyが1ないし0のときは以下のように場合分けができる。
J(w) = [− log(ϕ( )) − (1 − ) log(1 − ϕ( ))]
∑
i=1
n
y
(i)
z
(i)
y
(i)
z
(i)
J(ϕ(z), y; w) = −y log(ϕ(z)) − (1 − y) log(1 − ϕ(z))
J(ϕ(z), y; w) =
{
(−1) log(ϕ(z)) y = 1
(−1) log(1 − ϕ(z)) y = 0](https://image.slidesharecdn.com/chapter3slides-200226170409/85/DSO-Machine-Learning-Seminar-Vol-2-Chapter-3-22-320.jpg)

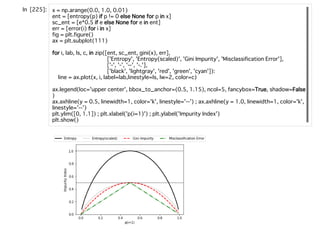
![クラスに属する確率φ(z)の様々な値に応じた分類コスト関数の値域。なお、zの定義域
は[-10, 10]としている。
クラスが1のときに、クラスが1である確率が⾼ければ、分類コスト関数は⼩さくなる
ことがわかる。逆に、クラスが1のときにクラスが1である確率が低ければ、分類コス
トは⾼くなる。その場合は、分類コストを下げるためにクラスが1である確率を上げ
るためにパラメータを調整していく必要がある。](https://image.slidesharecdn.com/chapter3slides-200226170409/85/DSO-Machine-Learning-Seminar-Vol-2-Chapter-3-24-320.jpg)
![ADALINE実装をロジスティック回帰のアルゴリズムに変換するADALINE実装をロジスティック回帰のアルゴリズムに変換する
ロジスティック回帰を独⾃に実装する場合は2章で⾏ったADALINE実装のコスト関数J
を新しいコスト関数に置き換えるだけでよい。
2章(ADALINE(単層ニューラルネットワーク))より追加で⾏うこと
コスト関数を書き換える
線形活性化関数をシグモイド活性化関数に置き換える
しきい値関数を書き換えて-1と1の代わりにクラスラベル0と1を返
すようにする
J(w) = − [ log(ϕ( )) + (1 − ) log(1 − ϕ( ))]
∑
i
y
(i)
z
(i)
y
(i)
z
(i)](https://image.slidesharecdn.com/chapter3slides-200226170409/85/DSO-Machine-Learning-Seminar-Vol-2-Chapter-3-25-320.jpg)
![ロジスティック回帰での勾配降下法に基づく学習アルゴリズムロジスティック回帰での勾配降下法に基づく学習アルゴリズム
まずロジスティック回帰における対数尤度
を最⼩化する際に対数尤度を各パラメータで偏微分すると、
シグモイド関数φ(z)の偏導関数は以下のように書き換えることができる。
l(w) = log L(w) = [ log(ϕ( )) + (1 − ) log(1 − ϕ( ))]
∑
i=1
n
y
(i)
z
(i)
y
(i)
z
(i)
= =
(
y − (1 − y)
)
∂l(w)
∂wj
∂l(w)
∂ϕ(z)
∂ϕ(z)
∂wj
1
ϕ(z)
1
1 − ϕ(z)
∂ϕ(z)
∂wj
= = =
(
1 −
)
∂ϕ(z)
∂z
∂(1 + e
−z
)
−1
∂z
∂(1 + e
−z
)
−1
∂(1 + )e
−z
∂(1 + )e
−z
∂z
1
1 + e
−z
1
1 + e
−1
= ϕ(z)(1 − ϕ(z))](https://image.slidesharecdn.com/chapter3slides-200226170409/85/DSO-Machine-Learning-Seminar-Vol-2-Chapter-3-26-320.jpg)



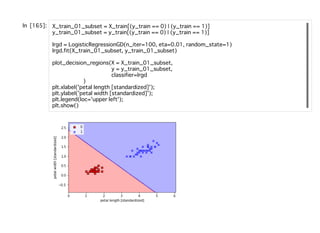







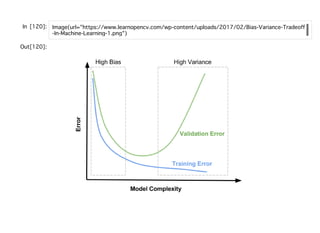

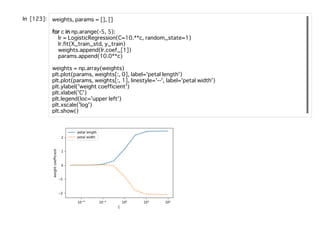
![正則化の適⽤
ロジスティック回帰のコスト関数に正則化の項を追加すれば良い。
scikit-learnのパラメータCはここでいう、
に該当する。なお、デフォルトの設定ではl2正則化となっており、Cのデフォルト値が
1となっている。つまりλが1のケースとなる。この関係を元のコスト関数に代⼊し
て、両辺にCを掛けるとコスト関数は以下のようになる。
この式から、Cの値を⼩さくすると正則化の強さを⾼めることがわかる。
J(w) = − [ log(ϕ( )) + (1 − ) log(1 − ϕ( ))] + ‖w
∑
i
y
(i)
z
(i)
y
(i)
z
(i)
λ
2
‖
2
C =
1
λ
J(w) = −C [ log(ϕ( )) + (1 − ) log(1 − ϕ( ))] + ‖w
∑
i
y
(i)
z
(i)
y
(i)
z
(i)
1
2
‖
2](https://image.slidesharecdn.com/chapter3slides-200226170409/85/DSO-Machine-Learning-Seminar-Vol-2-Chapter-3-44-320.jpg)































![[DSO] Machine Learning Seminar Vol.1 Chapter 1 and 2](https://cdn.slidesharecdn.com/ss_thumbnails/chapter12slides-200211153032-thumbnail.jpg?width=640&height=640&fit=bounds)












![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)






















![[読会]Logistic regression models for aggregated data](https://cdn.slidesharecdn.com/ss_thumbnails/logisticregressionmodelsforaggregateddata-211229094148-thumbnail.jpg?width=640&height=640&fit=bounds)













![[丸ノ内アナリティクスバンビーノ#23]データドリブン施策によるサービス品質向上の取り組み](https://cdn.slidesharecdn.com/ss_thumbnails/marunouchianalytics202107-210729113930-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Music×Analytics]プロの音に近づくための研究と練習](https://cdn.slidesharecdn.com/ss_thumbnails/muanalt-210227062125-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSO] Machine Learning Seminar Vol.8 Chapter 9](https://cdn.slidesharecdn.com/ss_thumbnails/chapter9slides-200927083926-thumbnail.jpg?width=640&height=640&fit=bounds)

![[第11回]データ分析ランチセッション - モダンな機械学習データパイプラインKedroを触ってみる](https://cdn.slidesharecdn.com/ss_thumbnails/lunchsession11-200325093135-thumbnail.jpg?width=640&height=640&fit=bounds)
![[第6回]データ分析ランチセッション - Camphrでモダンな自然言語処理](https://cdn.slidesharecdn.com/ss_thumbnails/dsolunchsession6-200219123751-thumbnail.jpg?width=640&height=640&fit=bounds)

![[第1回]データ分析ランチセッション ~ Qiita Advent Calendar2019から得た情報10選](https://cdn.slidesharecdn.com/ss_thumbnails/dsolunchsession1-200110120923-thumbnail.jpg?width=640&height=640&fit=bounds)



