Downloaded 220 times





![Filter* data
before an
expensive reduce
or aggregation
consider*
coalesce(
Use* data
structures that
require less
memory
Serialize*
PySpark
serializing
is built-in
Scala/
Java?
persist(storageLevel.[*]_SER)
Recommended:
kryoserializer *
tuning.html#tuning-
data-structures
See "Optimize partitions."
*
See "GC investigation." *
See "Checkpointing." *
The Spark Tuning Cheat-Sheet](https://image.slidesharecdn.com/9gbanyabida-160224015238/85/Spark-Tuning-for-Enterprise-System-Administrators-By-Anya-Bida-8-320.jpg)
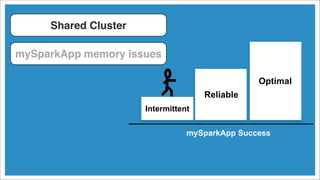










![Reduce the memory needed for
mySparkApp. How?
mySparkApp memory issues
persist(storageLevel.[*]_SER)
Recommended: kryoserializer *](https://image.slidesharecdn.com/9gbanyabida-160224015238/85/Spark-Tuning-for-Enterprise-System-Administrators-By-Anya-Bida-27-320.jpg)



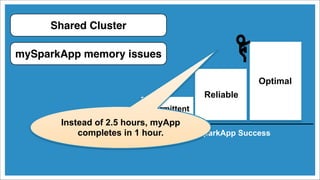

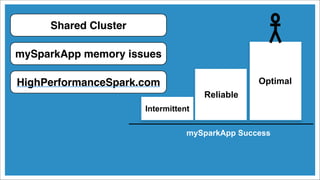


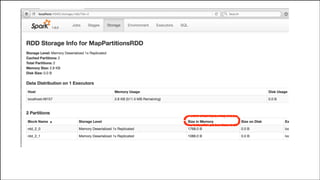
The document discusses tuning Apache Spark applications for enterprise system administrators. It covers identifying important Spark configuration parameters and how to configure them. Specifically, it addresses how to reduce memory usage through techniques like serialization and data structure optimization. It also provides guidance on gracefully handling memory limitations through checkpointing to avoid driver failures.










































































































