More Related Content
![[DL輪読会]画像を使ったSim2Realの現況](https://cdn.slidesharecdn.com/ss_thumbnails/imagesim2real-201030025320-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF

PDF

PPTX
Efficient Neural Architecture Search via Parameters Sharing @ ICML2018読み会 
PDF
やさしく音声分析法を学ぶ: ケプストラム分析とLPC分析 
PDF

PDF
論文紹介:Dueling network architectures for deep reinforcement learning 
PDF
Vision and Language(メタサーベイ ) 
PDF
プレゼン・ポスターで自分の研究を「伝える」 (How to do technical oral/poster presentation) What's hot

KEY

PDF
ブレインパッドにおける機械学習プロジェクトの進め方 
PDF
コミュニティデザインの思考 / これから始めるコミュニティマネジメント入門 (2) 
PDF
新規事業・起業を妨げる「ビジネスモデル症候群」とは ![[DL輪読会]EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://cdn.slidesharecdn.com/ss_thumbnails/yokota20190621dlhack-190621022108-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
[DL輪読会]EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks 
ODP

PDF

PDF
![[DL輪読会]A Bayesian Perspective on Generalization and Stochastic Gradient Descent](https://cdn.slidesharecdn.com/ss_thumbnails/20171106dl2-171108033614-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DL輪読会]A Bayesian Perspective on Generalization and Stochastic Gradient Descent 
PDF
PM と PMM のためのコミュニティマネジメント 
PDF

PDF
cvpaper.challenge 研究効率化 Tips 
PPTX

PPTX
PubMedBERT: 生物医学NLPのための事前学習 
PDF
ドット絵でプログラミング!難解言語『Piet』勉強会 
PDF
Transformerを多層にする際の勾配消失問題と解決法について 
PDF
【メタサーベイ】Vision and Language のトップ研究室/研究者 
PDF

PDF
FineDiving: A Fine-grained Dataset for Procedure-aware Action Quality Assessm... 
PDF
Design Sprint Process / デザインスプリントの実際のプロセスについて Viewers also liked

PDF
日本音響学会2017秋 ”クラウドソーシングを利用した対訳方言音声コーパスの構築” 
PDF
雑音環境下音声を用いた音声合成のための雑音生成モデルの敵対的学習 
PPTX
Jap2017 ss65 優しいベイズ統計への導入法 
PDF
Lyric Jumper:アーティストごとの歌詞トピックの傾向に基づく歌詞探索サービス 
PDF

PDF
多腕バンディット問題: 定式化と応用 (第13回ステアラボ人工知能セミナー) 
PPTX

PDF

PDF
VentureCafe_第2回:SIerでのキャリアパスを考える_ござ先輩発表資料 V1.0 
PDF

PDF

PDF

PDF

PDF

PDF

PDF
(DL hacks輪読)Bayesian Neural Network 
PDF

PDF
Similar to 日本音響学会2017秋 ビギナーズセミナー "深層学習を深く学習するための基礎"

PPTX

PPT

PPTX
Cvim saisentan-6-4-tomoaki 
PDF
Building High-level Features Using Large Scale Unsupervised Learning 
PPTX
MIRU2014 tutorial deeplearning 
PPTX

PDF
Deep Learning - Forward Propagation 
PDF

PDF
NN, CNN, and Image Analysis 
PDF

PDF
深層学習(岡本孝之 著) - Deep Learning chap.1 and 2 
PDF

PDF

PDF

PPTX
「機械学習とは?」から始める Deep learning実践入門 
PDF

PPTX
Image net classification with Deep Convolutional Neural Networks 
PDF
東京都市大学 データ解析入門 10 ニューラルネットワークと深層学習 1 
PDF

PDF
More from Shinnosuke Takamichi

PDF
JTubeSpeech: 音声認識と話者照合のために YouTube から構築される日本語音声コーパス 
PDF

PDF
J-KAC:日本語オーディオブック・紙芝居朗読音声コーパス 
PDF
短時間発話を用いた話者照合のための音声加工の効果に関する検討 
PDF
リアルタイムDNN音声変換フィードバックによるキャラクタ性の獲得手法 
PDF
ここまで来た&これから来る音声合成 (明治大学 先端メディアコロキウム) 
PDF

PDF
Interspeech 2020 読み会 "Incremental Text to Speech for Neural Sequence-to-Sequ... 
PDF
サブバンドフィルタリングに基づくリアルタイム広帯域DNN声質変換の実装と評価 
PDF
P J S: 音素バランスを考慮した日本語歌声コーパス 
PDF
音響モデル尤度に基づくsubword分割の韻律推定精度における評価 
PDF

PDF
論文紹介 Unsupervised training of neural mask-based beamforming 
PDF
論文紹介 Building the Singapore English National Speech Corpus 
PDF
論文紹介 SANTLR: Speech Annotation Toolkit for Low Resource Languages 
PDF
話者V2S攻撃: 話者認証から構築される 声質変換とその音声なりすまし可能性の評価 
PDF

PDF
差分スペクトル法に基づく DNN 声質変換の計算量削減に向けたフィルタ推定 
PDF
音声合成・変換の国際コンペティションへの 参加を振り返って 
PDF
ユーザ歌唱のための generative moment matching network に基づく neural double-tracking 日本音響学会2017秋 ビギナーズセミナー "深層学習を深く学習するための基礎"
- 1.
- 2.
/18
概要
背景:その強力さが叫ばれて久しい深層学習技術
– LSTM,CNN, Seq2Seq, CTC, GAN, AE, MemoryNet, SuperNN, etc.
問題:名前は聞いたことあるけど,中身をよく知らない…
– (研究で使ってるけど,ぶっちゃけ中身をよく知らない)
本発表:
– “名前は聞いたことある” から “仕組みがちょっとわかる” へ
– 信号処理とも絡めつつ概要を紹介
2
このスライドはslideshareにアップロード済みです.
(twitter: #asj2017a か 高道HPを参照)
- 3.
- 4.
- 5.
/18
前のページの構造 (single-layerNN) を積み重ねる!
– 複数のSingle-layer NN から成る関数
Forward propagationを式で書くと…
Feed-Forward NN
5
⋯
⋯
⋯
⋯
𝒙 𝒚
𝒉1 = 𝒇1 𝑾1 𝒙 + 𝒃1 𝒚 = 𝒇 𝐿 𝑾L 𝒉 𝐿−1 + 𝒃 𝐿
𝒉1 𝒉 𝐿−1
𝒚 = 𝒇 𝐿 𝑾L 𝒇 𝐿−1 𝑾L−𝟏 … 𝒇1 𝑾1 𝒙 + 𝒃1 … + 𝒃 𝐿−1 + 𝒃 𝐿
- 6.
/18
推定値 𝒚と正解値 𝒚 から計算される損失関数 𝐿 ⋅ を最小化
– 二乗誤差 𝐿 𝐲, 𝒚 = 𝒚 − 𝒚 ⊤ 𝒚 − 𝒚
損失関数を最小化するようにモデルパラメータ 𝑾, 𝒃 を更新
– 勾配法がしばしば使われる(𝛼は学習係数 [AdaGradなどを使用])
モデルパラメータの学習
6
𝑾1 ← 𝑾1 − 𝛼
𝜕𝐿 𝐲, 𝒚
𝜕𝑾1
⋯
⋯
⋯
⋯
𝒙 𝒚𝒉1 𝒉 𝐿−1
𝒚
𝐿 ⋅ 𝐿 𝐲, 𝒚
𝜕𝐿 𝐲, 𝒚 𝜕𝒚𝜕𝒚 𝜕𝒉 𝐿−1𝜕𝒉1 𝜕𝑾1
合成関数なので,各関数の
微分の積として得られる
- 7.
- 8.
/18
RNN (Recurrent NN):
リカレント構造を持ったNN
NNの出力の一部を入力に戻すNN (LSTMは,これの派生)
– 構造情報など(例えば音声の時間構造)の依存性を記憶
8
𝒙 𝑡−2
⋯
𝒚 𝑡−2
𝒚 𝑡−2 𝐿 ⋅
Loss 𝑡−2
𝒙 𝑡−1
⋯
𝒚 𝑡−1
𝒚 𝑡−1 𝐿 ⋅
Loss 𝑡−1
𝒙 𝒕
⋯
𝒚 𝑡
𝒚 𝑡 𝐿 ⋅
Loss 𝑡
𝒙 𝑡+1
⋯
𝒚 𝑡+1
𝒚 𝑡+1 𝐿 ⋅
Loss 𝑡+1
- 9.
/18
BPTT: Back propagationThrough Time
当該時間におけるbackpropagationを,過去の時間に伝播
– 一定時間でbackwardを打ち切る方法をTruncated BPTTという
9
𝒙 𝑡−2
⋯
𝒚 𝑡−2
𝒚 𝑡−2 𝐿 ⋅
Loss 𝑡−2
𝒙 𝑡−1
⋯
𝒚 𝑡−1
𝒚 𝑡−1 𝐿 ⋅
Loss 𝑡−1
𝒙 𝒕
⋯
𝒚 𝑡
𝒚 𝑡 𝐿 ⋅
Loss 𝑡
𝒙 𝑡+1
⋯
𝒚 𝑡+1
𝒚 𝑡+1 𝐿 ⋅
Loss 𝑡+1
Backward path
- 10.
/18
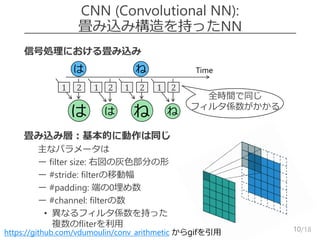
信号処理における畳み込み
畳み込み層:基本的に動作は同じ
–主なパラメータは
– ー filter size: 右図の灰色部分の形
– ー #stride: filterの移動幅
– ー #padding: 端の0埋め数
– ー #channel: filterの数
• 異なるフィルタ係数を持った
複数のfliterを利用
CNN (Convolutional NN):
畳み込み構造を持ったNN
10https://github.com/vdumoulin/conv_arithmetic からgifを引用
Timeは ね
は は
21 21
ね ね
21 21
全時間で同じ
フィルタ係数がかかる
- 11.
- 12.
- 13.
- 14.
/18
Deep generative model
(深層生成モデル)
Deep generative modelとは
– DNNを使ってデータの生成分布を表現するモデル
– 前述の自己回帰型CNNも,これに相当
ここでは,分布変形に基づく方法を紹介
– 既知の確率分布を観測データの分布に変形
– 生成データ 𝒚 の分布と観測データ 𝒚 の分布が似るようにDNNを学習
14
𝒙 ~ 𝑁 𝟎, 𝑰 𝑮 ⋅ 𝒚𝒚 = 𝑮 𝒙
生成
データの
分布
分布の近さを
計算
- 15.
/18
Generative Adversarial Network(GAN):
分布間距離の最小化
Generative adversarial network [Goodfellow et al., 2014.]
– 分布間の近似 Jensen-Shannon divergence を最小化
– 𝑮 ⋅ と,観測/生成データを識別する識別モデル 𝑫 ⋅ を敵対
15
𝒚
⋯
⋯
⋯
⋯
𝑮 ⋅
𝑫 ⋅
1: 観測
0: 生成
- 16.
/18
Moment Matching Network(MMN):
モーメント間距離の最小化
Moment matching network [Li et al., 2015.]
– 分布のモーメント (平均,分散,…) 間の二乗距離を最小化
– 実装上は,グラム行列のノルムの差を最小化
16
𝒚
𝒚
⋯
⋯
⋯
⋯
𝑮 ⋅
- 17.
- 18.
/18
まとめ
深層学習を深く学習するための基礎を紹介
基礎構造
–Feed-Forward neural networks (FFNN)
– Recurrent neural networks (RNN) … LSTMなど
– Convolutional neural networks (CNN) … WaveNetなど
Deep generative models
– Generative adversarial networks (GAN) … 敵対的学習
– Moment-matching networks (MMN)
18
- 19.
- 20.
- 21.
- 22.
/18
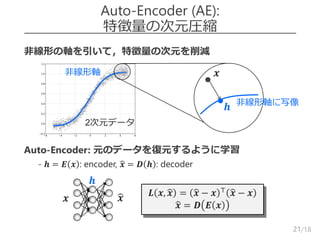
Denoising AE
より頑健な次元圧縮を行うため,入力側にノイズを付与
–ノイジーな入力から,元のデータを復元する
どんなノイズを加える?
– Drop: ランダムに,使用する次元を減らす
• 𝒙 = 1,1,0,0,1,0,1 ^⊤ ∘ 𝒙 ( ∘ は要素積)
– Gauss: ガウスノイズを付与する
• 𝒙 = 𝒙 + 𝑵 𝟎, 𝜆𝑰 ( 𝜆 は分散)
22
𝒙
𝒉
𝒙 𝑳 𝒙, 𝒙 = 𝒙 − 𝒙 ⊤
𝒙 − 𝒙
𝒙 = 𝑫 𝑬 𝒙






![/18
推定値 𝒚 と正解値 𝒚 から計算される損失関数 𝐿 ⋅ を最小化
– 二乗誤差 𝐿 𝐲, 𝒚 = 𝒚 − 𝒚 ⊤ 𝒚 − 𝒚
損失関数を最小化するようにモデルパラメータ 𝑾, 𝒃 を更新
– 勾配法がしばしば使われる(𝛼は学習係数 [AdaGradなどを使用])
モデルパラメータの学習
6
𝑾1 ← 𝑾1 − 𝛼
𝜕𝐿 𝐲, 𝒚
𝜕𝑾1
⋯
⋯
⋯
⋯
𝒙 𝒚𝒉1 𝒉 𝐿−1
𝒚
𝐿 ⋅ 𝐿 𝐲, 𝒚
𝜕𝐿 𝐲, 𝒚 𝜕𝒚𝜕𝒚 𝜕𝒉 𝐿−1𝜕𝒉1 𝜕𝑾1
合成関数なので,各関数の
微分の積として得られる](https://image.slidesharecdn.com/slidetakamichifinal-170925044252/85/2017-6-320.jpg)



![/18
CNNの全体構造
11
[LeCun et al., 1998.]
フィルタ
インデックス
⋯
⋯
⋯
Pooling層
例:最大値をとるmax-pooling](https://image.slidesharecdn.com/slidetakamichifinal-170925044252/85/2017-11-320.jpg)
![/18
自己回帰型CNN
12
CNNを自己回帰モデルとして扱う
– あるステップで生成した出力から,次のステップを推定
→ 信号処理の自己回帰 (エコーやハウリングなど) と同じ
– 系列を扱うRNNと違い,ステップごとに並列化して学習可能
WaveNet (PixelCNNの派生) [Oord et al., 2016.]
– これまでに生成した波形から,次の波形を生成
–
https://deepmind.com/blog/wavenet-generative-model-raw-audio/ から引用](https://image.slidesharecdn.com/slidetakamichifinal-170925044252/85/2017-12-320.jpg)


![/18
Generative Adversarial Network (GAN):
分布間距離の最小化
Generative adversarial network [Goodfellow et al., 2014.]
– 分布間の近似 Jensen-Shannon divergence を最小化
– 𝑮 ⋅ と,観測/生成データを識別する識別モデル 𝑫 ⋅ を敵対
15
𝒚
⋯
⋯
⋯
⋯
𝑮 ⋅
𝑫 ⋅
1: 観測
0: 生成](https://image.slidesharecdn.com/slidetakamichifinal-170925044252/85/2017-15-320.jpg)
![/18
Moment Matching Network (MMN):
モーメント間距離の最小化
Moment matching network [Li et al., 2015.]
– 分布のモーメント (平均,分散,…) 間の二乗距離を最小化
– 実装上は,グラム行列のノルムの差を最小化
16
𝒚
𝒚
⋯
⋯
⋯
⋯
𝑮 ⋅](https://image.slidesharecdn.com/slidetakamichifinal-170925044252/85/2017-16-320.jpg)