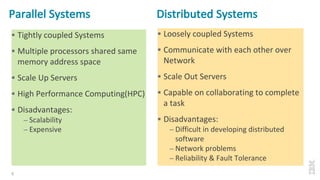
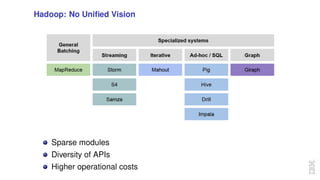
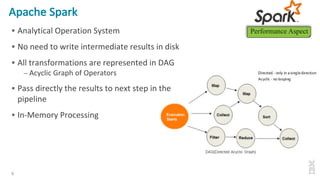
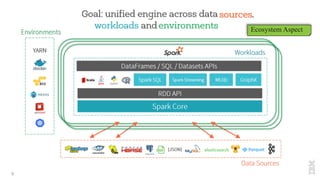
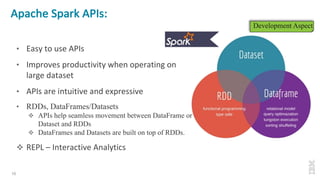
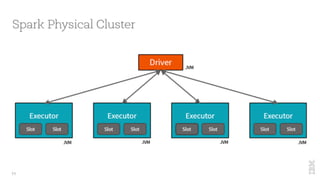
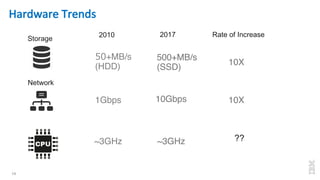
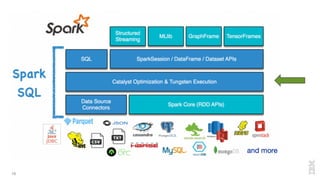
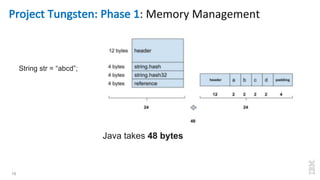
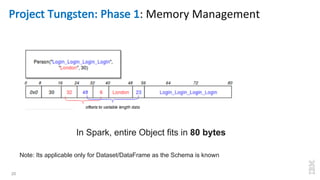
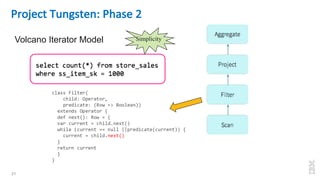
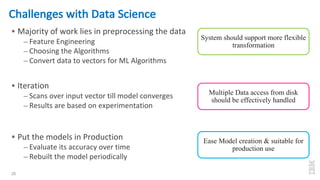
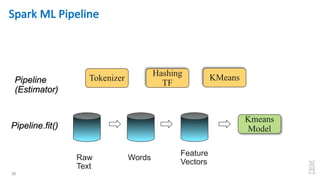
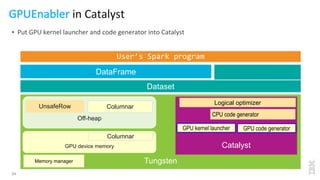
The document discusses the development of Apache Spark, its architecture, and its applications in big data processing, highlighting its advantages over traditional systems like Hadoop. It emphasizes Spark's in-memory processing capabilities, use of DataFrames, and integration with machine learning libraries. Additionally, it outlines Project Tungsten's phases aimed at improving Spark's performance, along with GPU acceleration strategies to optimize computation-heavy applications.