



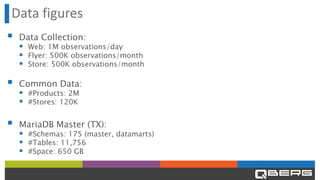


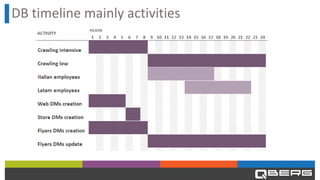
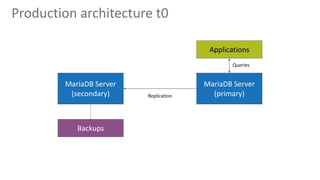



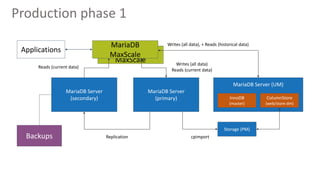



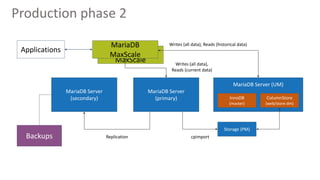
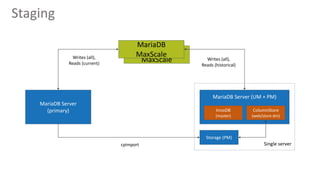



Qberg, a market research institute, specializes in consumer goods' price intelligence across Italy, Europe, and LATAM, utilizing data collection methods from various sources to provide insights. The company has recently enhanced its data management architecture by introducing MariaDB AX and MaxScale to improve data storage and query processing efficiency while addressing issues with slow customer queries and OLTP/OLAP operations on the same database. This new setup aims to expedite access to historical data and accommodate longer data periods for improved customer service.


































![[db tech showcase OSS 2017] A23: Analytics with MariaDB ColumnStore by MariaD...](https://cdn.slidesharecdn.com/ss_thumbnails/mariadbcolumnstore-dbtechshowcasetokyo2017-170628024921-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase OSS 2017] A25: Replacing Oracle Database at DBS Bank by Mar...](https://cdn.slidesharecdn.com/ss_thumbnails/mariadbcolumnstore-dbtechshowcasetokyo2017-170628030047-thumbnail.jpg?width=640&height=640&fit=bounds)


















































