Download as PDF, PPTX














![Tuning Commands
MariaDB [test]> select count(*) from t1 where i = 5;
+----------+
| count(*) |
+----------+
| 2200000 |
+----------+
1 row in set (0.27 sec)
MariaDB [test]> select calGetStats()G
*************************** 1. row ***************************
calGetStats(): Query Stats: MaxMemPct-0; NumTempFiles-0; TempFileSpace-0B;
ApproxPhyI/O-11042; CacheI/O-11042; BlocksTouched-11042; PartitionBlocksEliminated-0;
MsgBytesIn-332KB; MsgBytesOut-3KB; Mode-Distributed
1 row in set (0.00 sec)
calGetStats: Information On The Last Query Executed Within A Given Session](https://image.slidesharecdn.com/mariadbcolumnstorelondonroadshow-170707083720/85/Big-Data-Analytics-with-MariaDB-ColumnStore-27-320.jpg)
![MariaDB [test]> select calSetTrace(1);
+----------------+
| calSetTrace(1) |
+----------------+
| 0 |
+----------------+
1 row in set (0.00 sec)
MariaDB [test]> select d.name dept_name,
-> count(*) emp_count,
-> sum(e.salary) salary_cost
-> from emp e
-> join i_dept d on e.dept_id = d.dept_id
-> group by dept_name;
+-------------+-----------+-------------+
| dept_name | emp_count | salary_cost |
+-------------+-----------+-------------+
| Engineering | 2 | 2500 |
| Sales | 2 | 3800 |
+-------------+-----------+-------------+
2 rows in set, 1 warning (0.03 sec)
Tuning Commands
calGetTrace: Detailed distributed query execution plan
MariaDB [test]> select calGetTrace()G
*************************** 1. row ***************************
calGetTrace():
Desc Mode Table TableOID ReferencedColumns PIO LIO PBE Elapsed Rows
CES UM - - - - - - 0.000 2
BPS PM e 3013 (dept_id,salary) 2 4 0 0.008 2
HJS PM e-d 3013 - - - - ----- -
TAS UM - - - - - - 0.000 2
1 row in set (0.00 sec)](https://image.slidesharecdn.com/mariadbcolumnstorelondonroadshow-170707083720/85/Big-Data-Analytics-with-MariaDB-ColumnStore-28-320.jpg)



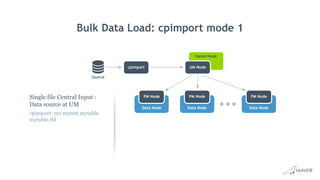
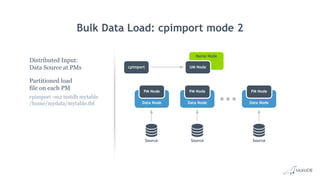
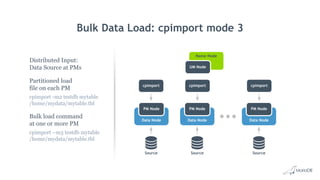
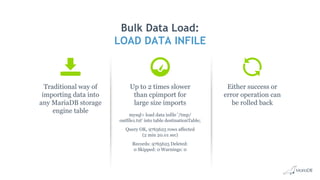
![Bulk Data Load: cpimport
• Fastest way to load data into MariaDB ColumnStore
• Load data from CSV file
cpimport dbName tblName [loadFile]
• Load data from Standard Input
mysql -e 'select * from source_table;' -N db2 | cpimport destination_db
destination_tbl -s 't‘
• Load data from Binary Source file
cpimport -I1 mydb mytable sourcefile.bin
• Multiple tables in can be loaded in parallel by launching multiple jobs
• Read queries continue without being blocked
• Successful cpimport is auto-committed
• In case of errors, entire load is rolled back](https://image.slidesharecdn.com/mariadbcolumnstorelondonroadshow-170707083720/85/Big-Data-Analytics-with-MariaDB-ColumnStore-33-320.jpg)


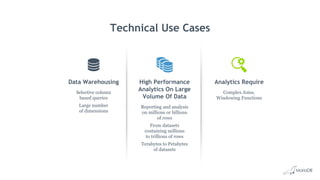
![Industry Category Use Case
Gaming Behavior Analytics Projecting and predicting user behavior based on past and current data
Advertising Customer Analytics Customer behavior data for market segmentation and predictive analytics.
Advertising Loyalty Analytics Customer analytics focusing on a person’s commitment to a product, company, or brand.
Web,
E-commerce
Click Stream Analytics
Web activity analysis, software testing, market research with analytics on data about the clicks areas of web pages while
web browsing [Deal News]
Marketing Promotional Testing Using marketing and campaign management data to identify the best criteria to be used for a particular marketing offer.
Social Network Network Analytics Relationship analytics among network nodes
Financial Fraud Analytics
Monitoring user financial transactions and identifying patterns of behaviour to predict and detect abnormal or fraudulent
activity to prevent damage to user and institution.
Healthcare Patient Analytics Analyzing patient medical records to identify patterns to be used for improved medical treatment.
Healthcare Clinical Analytics Analyzing clinical data and its impact on patients to identify patterns to be used for improved medical treatment.
Telco
Network and Application
Performance Analytics
Streaming data from network devices and applications enriched with business operations data to uncover actionable
insights for network planning, operations and marketing analytics
Aviation Flight analytics
Proactively project parts replacement, maintenance and air-plane retirement based on real-time and historically collected
flight parameter data [Boeing]
Customer Use Cases](https://image.slidesharecdn.com/mariadbcolumnstorelondonroadshow-170707083720/85/Big-Data-Analytics-with-MariaDB-ColumnStore-41-320.jpg)



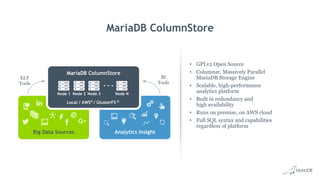
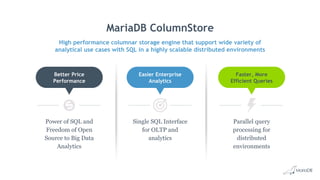
MariaDB ColumnStore is an open source columnar database storage engine that provides high performance analytics capabilities on large datasets using standard SQL. It uses a distributed architecture that stores data by column rather than by row to enable fast queries by only accessing the relevant columns. It can scale horizontally on commodity servers to support analytics workloads on datasets ranging from millions to trillions of rows.





























![[db tech showcase Tokyo 2017] C37: MariaDB ColumnStore analytics engine : use...](https://cdn.slidesharecdn.com/ss_thumbnails/mariadbcolumnstoreusecases1-170911080447-thumbnail.jpg?width=640&height=640&fit=bounds)

![[db tech showcase OSS 2017] A25: Replacing Oracle Database at DBS Bank by Mar...](https://cdn.slidesharecdn.com/ss_thumbnails/mariadbcolumnstore-dbtechshowcasetokyo2017-170628030047-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase OSS 2017] A23: Analytics with MariaDB ColumnStore by MariaD...](https://cdn.slidesharecdn.com/ss_thumbnails/mariadbcolumnstore-dbtechshowcasetokyo2017-170628024921-thumbnail.jpg?width=640&height=640&fit=bounds)















































