spark 1.6을 기준으로 spark sql에 대해서 개략적으로 설명한 자료입니다. 발표 자료가 친절하지 않으나 한글로 된 자료가 없길래 혹시나 도움 되시는 분들이 있을까 하여 공유합니다.
발표자료 보다는 마지막 페이지의 참고자료들을 읽어보시기를 권장 드립니다.
출처만 남겨주시면 자유롭게 가져가셔서 사용하셔도 무방합니다.
2
목차
Spark SQL개요
Tungsten execution engine
Catalyst optimizer
RDD, DataFrame
Dataset
Spark SQL application (in Java)
Linking
example
참고 자료
3.
3
Spark SQL
정형/반정형데이터(structured/semi-structured Data) 처리에 특화된
Spark Library
Tungsten execution engine & Catalyst optimizer 기반
다양한 interface 지원
SQL, HiveSQL queries
Dataframe API
Scala, Java, Python, and R에서 사용 가능
Spark 1.3
Dataset API
Scala, Java 에서 사용 가능
Spark 1.6
다양한 Input source를 지원
RDD & 임시 테이블
JSON 데이터 셋
Parquet file
Hive Table
ODBC/JCBC 서버와의 연동
4.
4
Tungsten execution engine
스파크의 bottleneck은?
I/O나 network bandwidth가 아님
High bandwidth SSD & striped HDD의 등장
10Gbps network의 등장
CPU 와 memory에서 bottleneck 현상이 발생
기본적인 processing workload와 함께
Disk I/O를 최소화하기 위한 input data pruning workload
Shuffle을 위한 serialization과 hashing이 특히 key bottleneck
CPU와 memory의 효율을 높여야…
하드웨어의 한계에 가깝게 성능을 뽑아올 수 있는 System Engine이 필요!
Project Tungsten
Spark 1.4부터 DataFrame에 적용
spark 1.6에서 Dataset으로 확장
참고:
1. Project Tungsten – databrick
2. https://issues.apache.org/jira/browse/SPARK-7075
5.
5
Tungsten execution engine– three Goal
Memory Management and Binary Processing
JVM object 모델과 garbage collection의 overhead가 큼
=>장기적으로 data를 저장할 경우 Java objects 보다는 binary format으로 저장
메모리를 좀더 명확하게 관리할 필요가 있음
=> denser in-memory data format을 적용하여 메모리 사용률을 최소화 함
더 나은 memory accounting (size of bytes) 기술 적용(기존엔 Heuristics 기반)
이를 기반으로 하면서 domain semantics을 최대한 반영한 data processing을 지원해야 함
=>binary format의 in memory data에 대해서도 data type을 이해하는 operator를 지원
(serialization/deserialization 없이 data processing)
Cache-aware Computation
sorting and hashing for aggregations, joins, and shuffle의 성능이 향상이 필요
=>memory hierarchy를 활용하는 algorithm과 data struncture
Code Generation
expression evaluation, DataFrame/SQL operators, serializer의 성능 향상이 필요
=>modern compilers and CPUs의 성능을 제대로 활용할 수 있는 code generation
6.
6
Catalyst optimizer
스칼라함수형 프로그래밍 기법 특징을 살려 구현한 extensible optimizer
extensible design
새로운 optimization techniques과 feature들의 추가가 용이
외부 개발자가 optimizer를 확장하여 사용하기 용이
Catalyst의 구동 (In Spark SQL) ( 자세한 사항은 paper 참고)
Tree 구조를 기반으로 optimization
크게 4단계로 진행
그림 출처: Catalyst Optimizer - databrick
x+(1+2) 의 tree 예제 Catalyst의 phase
7.
7
RDD, DataFrame
DataFrames /SQL
Structured Binary Data (Tungsten)
• High level relational operation 사용 가능
• Catalyst optimization 적용 가능
• Lower memory pressure
• Memory accounting (avoid OOMs)
• Faster sorting / hashing / serialization
RDDs
Collections of Native JVM Objects
• 로직 상에 특정 data type 표현이 용이
• Compile-time type-safety 보장
• 함수형 프로그래밍 가능
두 타입 간의 변환은 지원 되지만..
높은 변환 cost
변환을 위한 boilerplate(표준 문안, 규칙) 숙지 필요
둘의 장점을 합쳐놓은 API를 제공할 수 있을까?
Catalyst optimizer & Tungsten execution engine의 장점을 활용할 수 있어야 함
Domain object의 type을 이해할 수 있고 이를 활용할 수 있어야 함
성능 ↑안전성 & 유연성 ↑
8.
8
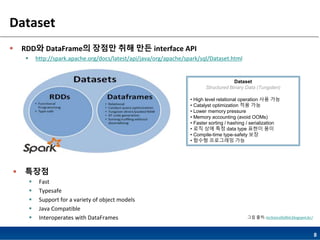
Dataset
RDD와 DataFrame의장점만 취해 만든 interface API
http://spark.apache.org/docs/latest/api/java/org/apache/spark/sql/Dataset.html
특장점
Fast
Typesafe
Support for a variety of object models
Java Compatible
Interoperates with DataFrames
Dataset
Structured Binary Data (Tungsten)
• High level relational operation 사용 가능
• Catalyst optimization 적용 가능
• Lower memory pressure
• Memory accounting (avoid OOMs)
• Faster sorting / hashing / serialization
• 로직 상에 특정 data type 표현이 용이
• Compile-time type-safety 보장
• 함수형 프로그래밍 가능
그림 출처: technicaltidbit.blogspot.kr/
9.
9
Dataset
Encoder
Dataset은테이블 형식의 Structured Binary data로 저장
JVM object인 RDD는 물론, DataFrame과도 형태가 다름
Processing 및 전송을 위해서는 serialization이 필요
RDD/DataFrame type의 data를 Dataset으로 변경하기 위해서는
Object의 타입에 맞는 특별한 Encoder가 필요(반대 방향으로의 변환에도 동일)
이전 버전까지 사용했던 java, kyro Serialization에 비해 성능 우수함
Data Serialization 성능 비교 그림 출처: Introducing Spark Datasets- databrick
10.
10
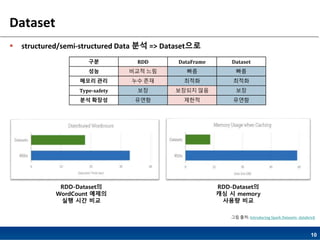
Dataset
structured/semi-structured Data분석 => Dataset으로
구분 RDD DataFrame Dataset
성능 비교적 느림 빠름 빠름
메모리 관리 누수 존재 최적화 최적화
Type-safety 보장 보장되지 않음 보장
분석 확장성 유연함 제한적 유연함
RDD-Dataset의
WordCount 예제의
실행 시간 비교
RDD-Dataset의
캐싱 시 memory
사용량 비교
그림 출처: Introducing Spark Datasets- databrick












![14
Spark SQL application (in Java)
(DataFrame example 2) Text File : Specifying the Schema
SparkConf sparkConf = new SparkConf().setAppName("dataFrame");
JavaSparkContext ctx = new JavaSparkContext(sparkConf);
SQLContext sqlContext = new org.apache.spark.sql.SQLContext(ctx);
JavaRDD<String> people = ctx.textFile("examples/src/main/resources/people.txt");
String schemaString = "name age";
List<StructField> fields = new ArrayList<StructField>();
for (String fieldName: schemaString.split(" ")) {
fields.add(DataTypes.createStructField(fieldName, DataTypes.StringType, true));
}
StructType schema = DataTypes.createStructType(fields);
JavaRDD<Row> rowRDD = people.map(new Function<String, Row>() {
public Row call(String record) throws Exception {
String[] fields = record.split(",");
return RowFactory.create(fields[0], fields[1].trim());
}
});
DataFrame peopleDataFrame = sqlContext.createDataFrame(rowRDD, schema);
peopleDataFrame.show();//1
peopleDataFrame.printSchema();//2
ctx.stop();
1.
2.
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.sql.SQLContext;
import org.apache.spark.sql.DataFrame;
import java.util.List;](https://image.slidesharecdn.com/sparksql-160119142112/85/Spark-sql-14-320.jpg)

![16
Spark SQL application (in Java)
(DataFrame example 3) Text File : Inferring the Schema(JavaBean)
SparkConf sparkConf = new SparkConf().setAppName("dataFrame");
JavaSparkContext ctx = new JavaSparkContext(sparkConf);
SQLContext sqlContext = new org.apache.spark.sql.SQLContext(ctx);
JavaRDD<Person> people = ctx.textFile("examples/src/main/resources/people.txt").map(
new Function<String, Person>() {
public Person call(String line) throws Exception {
String[] parts = line.split(",");
Person person = new Person();
person.setName(parts[0]);
person.setAge(Integer.parseInt(parts[1].trim()));
return person;
}});
DataFrame schemaPeople = sqlContext.createDataFrame(people, Person.class);
schemaPeople.registerTempTable("people");
DataFrame teenagers = sqlContext.sql("SELECT name, age FROM people WHERE age >= 13 AND age <= 19");
teenagers.show();//1
teenagers.printSchema();//2
ctx.stop();
1.
2.
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.sql.SQLContext;
import org.apache.spark.sql.DataFrame;
import org.apache.spark.sql.types.DataTypes;
import org.apache.spark.sql.types.StructType;
import org.apache.spark.sql.types.StructField;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.RowFactory;
import java.util.ArrayList;
import java.util.List;](https://image.slidesharecdn.com/sparksql-160119142112/85/Spark-sql-16-320.jpg)





















![[D2 COMMUNITY] Spark User Group - 스파크를 통한 딥러닝 이론과 실제](https://cdn.slidesharecdn.com/ss_thumbnails/520160211-160307085845-thumbnail.jpg?width=640&height=640&fit=bounds)













![[264] large scale deep-learning_on_spark](https://cdn.slidesharecdn.com/ss_thumbnails/246large-scaledeeplearningonspark-150915055051-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)




![[NoSQL] 2장. 집합적 데이터 모델](https://cdn.slidesharecdn.com/ss_thumbnails/2-130323002448-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)


![[NDC 2011] 게임 개발자를 위한 데이터분석의 도입](https://cdn.slidesharecdn.com/ss_thumbnails/ndc2011ver5-140313211642-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)





![NDC 2016, [슈판워] 맨땅에서 데이터 분석 시스템 만들어나가기](https://cdn.slidesharecdn.com/ss_thumbnails/ndc-2016-160429031551-thumbnail.jpg?width=640&height=640&fit=bounds)
















![[236] 카카오의데이터파이프라인 윤도영](https://cdn.slidesharecdn.com/ss_thumbnails/236-161025031702-thumbnail.jpg?width=640&height=640&fit=bounds)



![[경북] I'mcloud information](https://cdn.slidesharecdn.com/ss_thumbnails/imcloudinformation-151105091525-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)