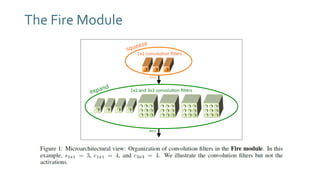
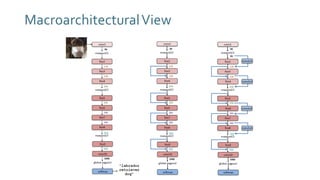
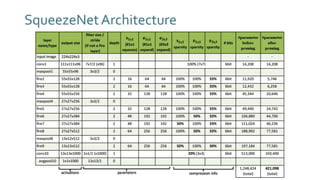
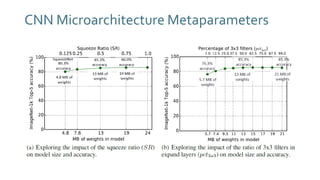
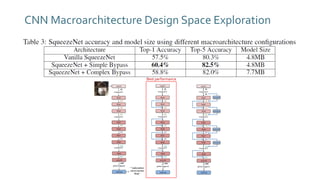
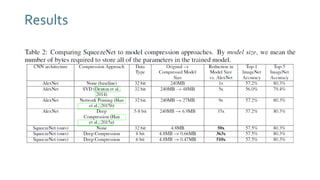
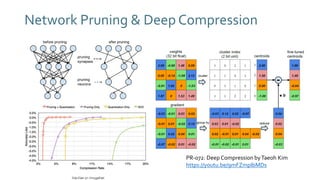
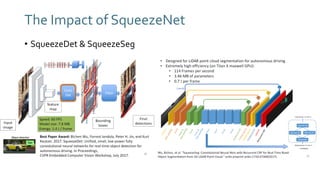
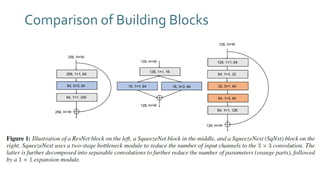
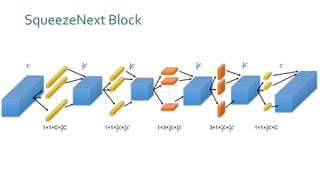
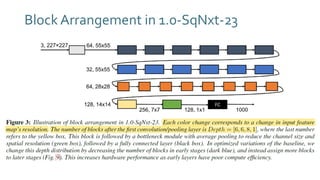
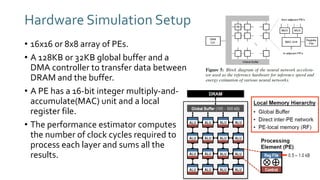
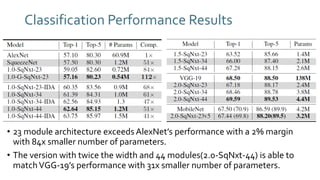
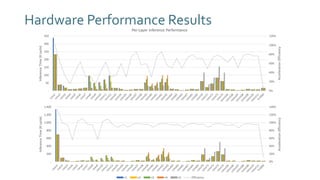
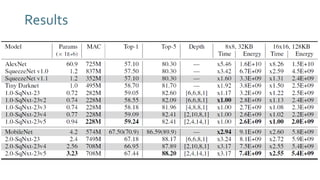
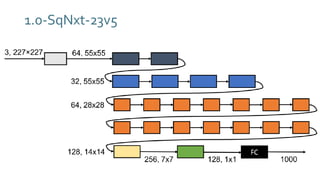
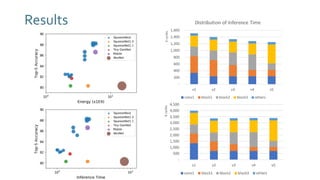
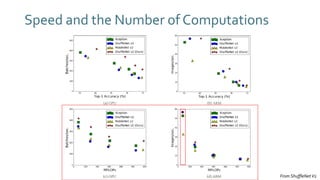
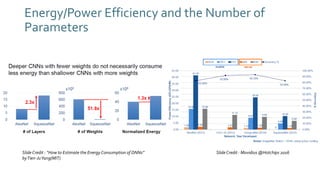
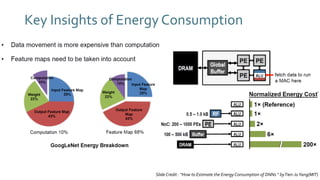
The document discusses SqueezeNext, a hardware-aware neural network designed to improve efficiency and accuracy in deep learning models. It highlights strategies for reducing parameters while enhancing classification performance, particularly for edge devices, by employing techniques such as separable convolutions and bottleneck layers. The architecture shows significant performance improvements over traditional models like AlexNet while maintaining a smaller model size.