



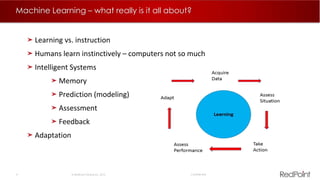


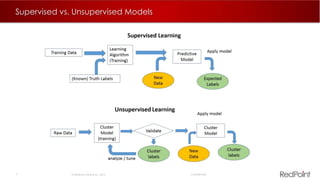
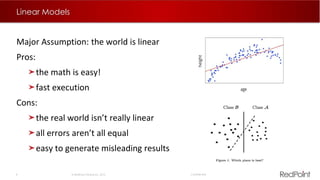

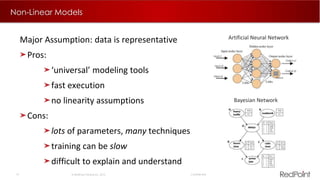

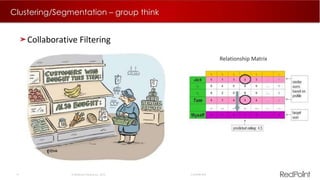

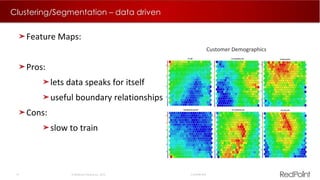

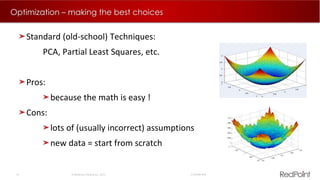
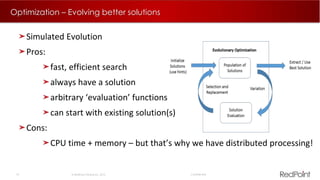
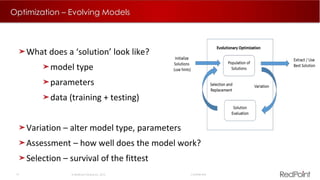
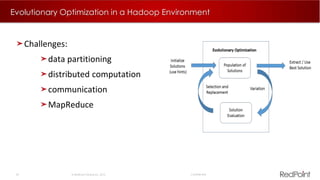

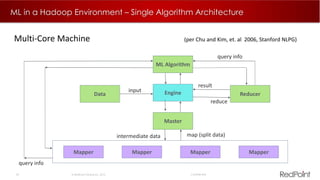

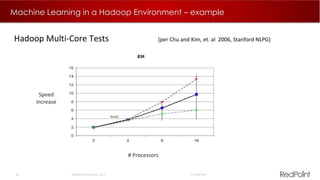
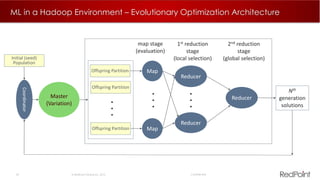





The document discusses machine learning techniques for analyzing big data. It outlines three tenants of success: prediction, optimization, and automation. Various machine learning models are examined, including linear models, decision trees, neural networks, and clustering. Implementing machine learning algorithms in Hadoop distributed environments is also discussed. Optimization techniques like evolutionary algorithms are presented. Regularly adapting models with updated data is recommended to keep analyses current.











































![Inspiring Travel at Airbnb [WIP]](https://cdn.slidesharecdn.com/ss_thumbnails/june91205pmairbnbqiancheng-150616222059-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)




















































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)









