Downloaded 20 times








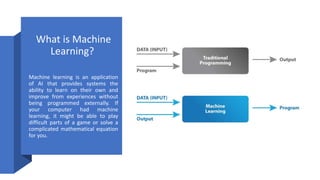




















The document discusses big data and machine learning, defining big data as vast and complex datasets that challenge traditional management tools, while highlighting its advantages and challenges. It also defines machine learning as an AI application that learns from data, presenting real-world applications and various types, such as supervised and unsupervised learning. The document emphasizes the relationship between big data and machine learning, outlining a framework for processing big data using machine learning techniques and presenting research challenges in the field.



































































