Download as PDF, PPTX


![Hello!
I am Stefano Baghino
Software Engineer @ DATABIZ
stefano.baghino@databiz.it
@stefanobaghino
Favorite PL: Scala
My hero: XKCD’s Beret Guy
What I fear: [object Object]](https://image.slidesharecdn.com/talk-spark-intro-151124160033-lva1-app6891/75/Stefano-Baghino-From-Big-Data-to-Fast-Data-Apache-Spark-3-2048.jpg)














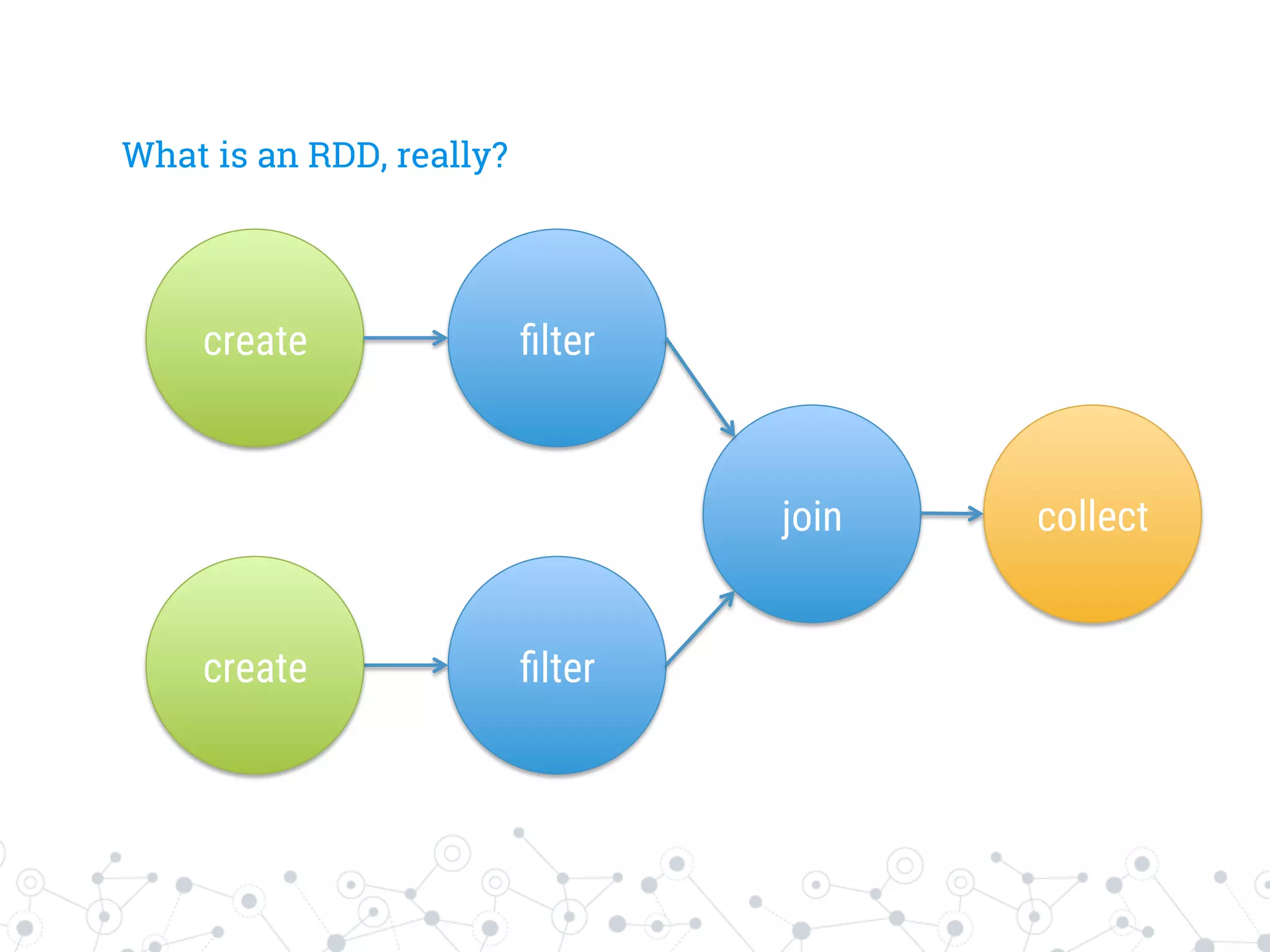



![Step 1: Create the logical DAG
HadoopRDD
MappedRDD
ShuffledRDD
MappedValuesRDD
Array[(Char, Int)]
sc.textFile...
map(n => (n.charAt(0),...
groupByKey()
mapValues(n => n.toSet...
collect()](https://image.slidesharecdn.com/talk-spark-intro-151124160033-lva1-app6891/75/Stefano-Baghino-From-Big-Data-to-Fast-Data-Apache-Spark-26-2048.jpg)
![Step 2: Create the execution plan
u Pipeline as much as possible
u Split into “stages” based on the need to “shuffle” data
HadoopRDD
MappedRDD
ShuffledRDD
MappedValuesRDD
Array[(Char, Int)]
Alice
Bob
Andy
(A, Alice)
(B, Bob)
(A, Andy)
(A, (Alice, Andy))
(B, Bob)
(A, 2)
Res0 = [(A, 2),….]
(B, 1)
Stage
1
Res0 = [(A, 2), (B, 1)]
Stage
2](https://image.slidesharecdn.com/talk-spark-intro-151124160033-lva1-app6891/75/Stefano-Baghino-From-Big-Data-to-Fast-Data-Apache-Spark-27-2048.jpg)





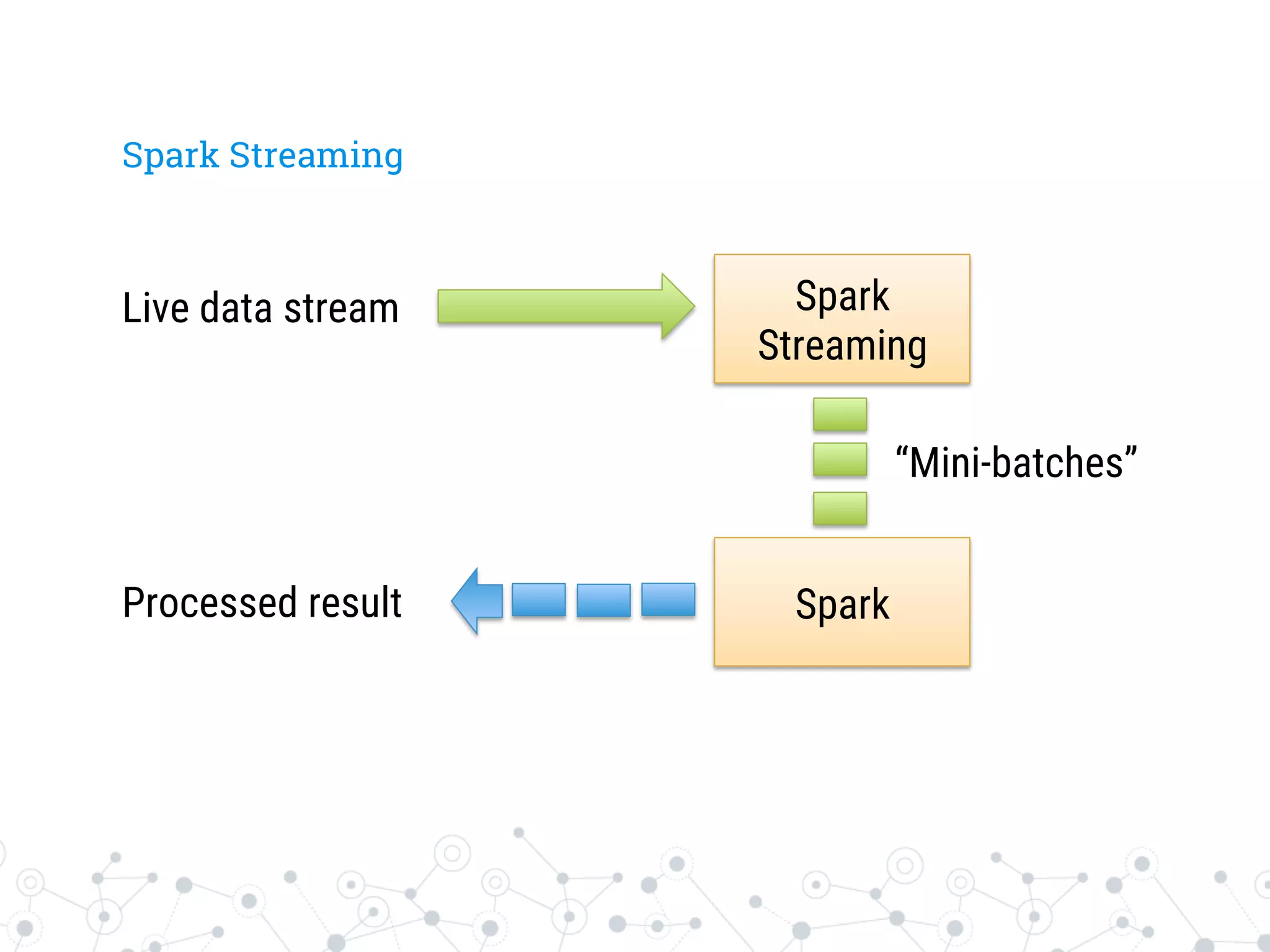






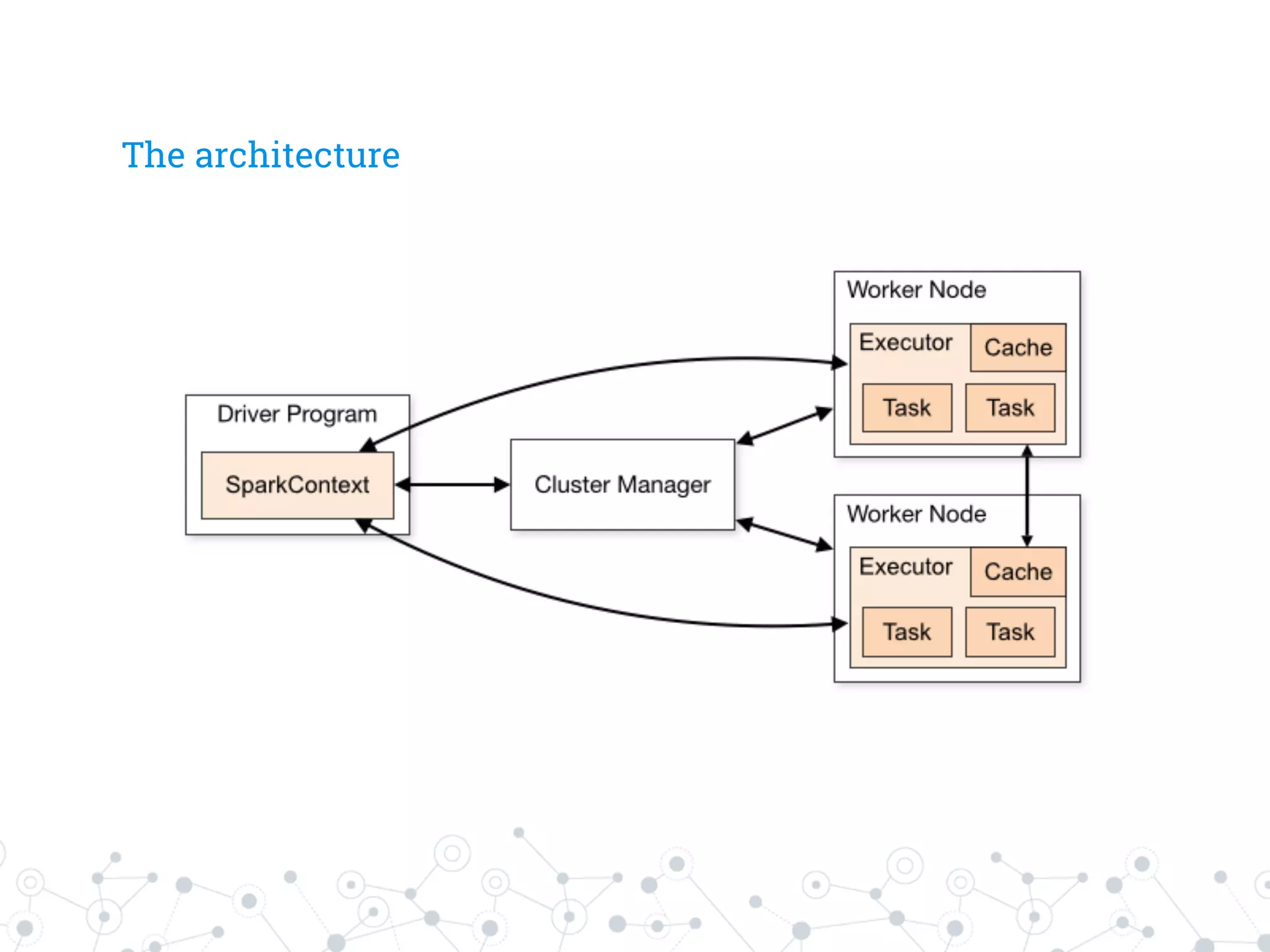
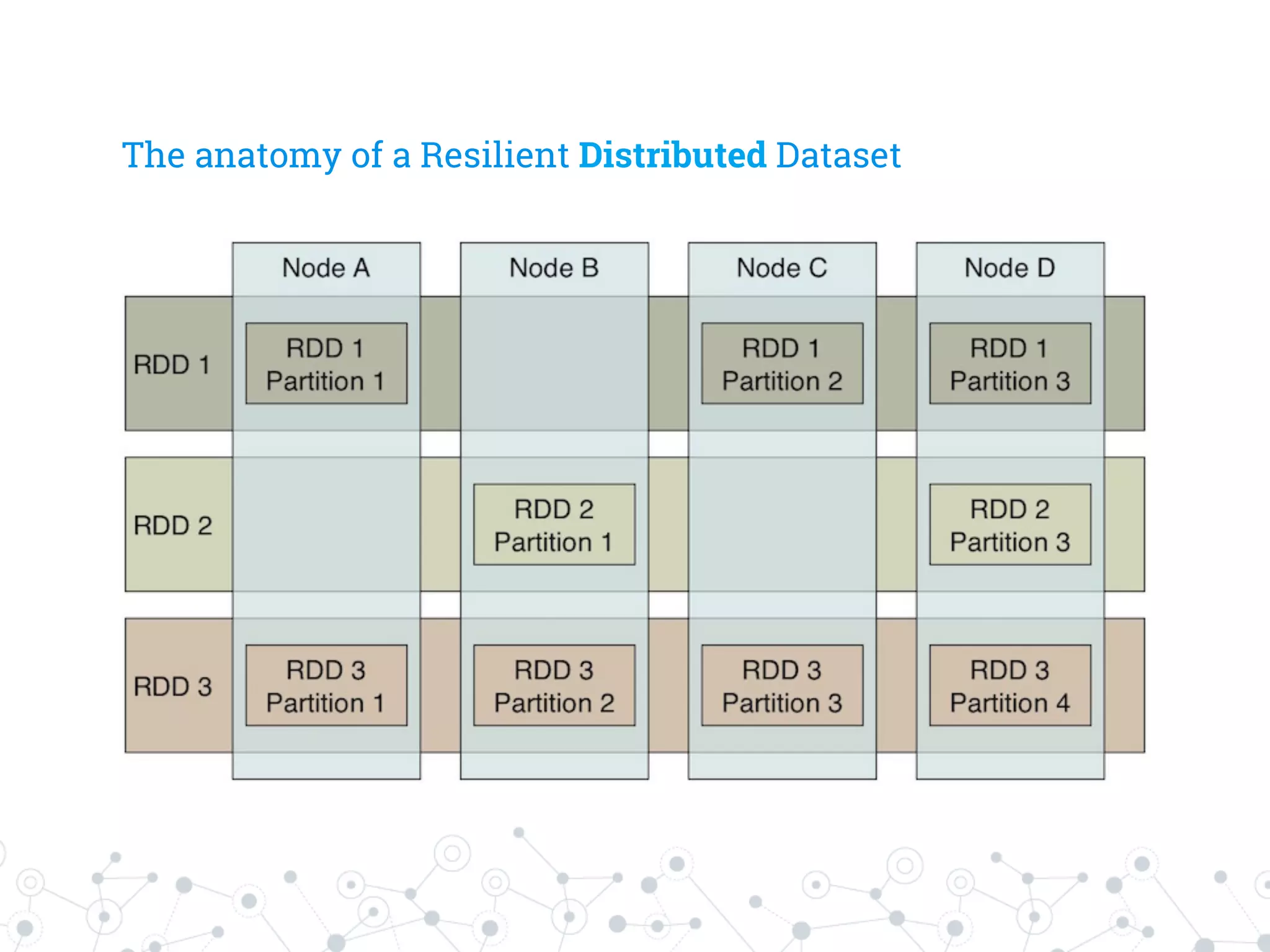
The document is a presentation by Stefano Baghino on Apache Spark, discussing the transition from big data to fast data, highlighting the functionalities and advantages of Spark, including its in-memory processing and ease of use for developers. It covers concepts such as resilient distributed datasets (RDDs), Spark's architecture, and real-time data processing through Spark Streaming. The presentation aims to provide insights into Spark's ecosystem and its applications in various programming environments.














































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)


















