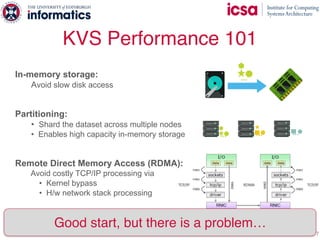
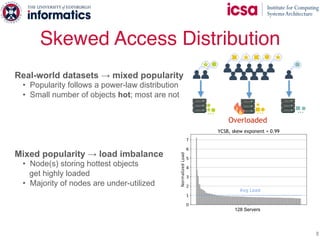
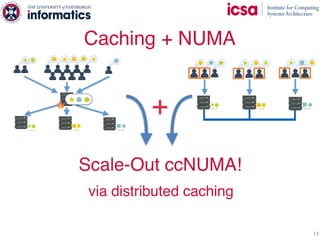
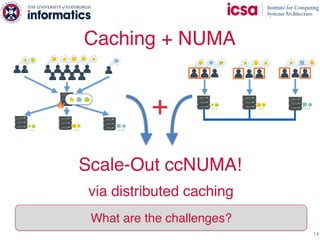
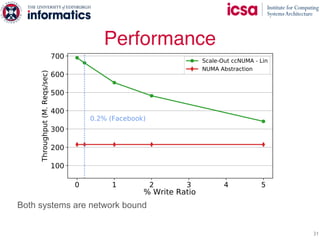
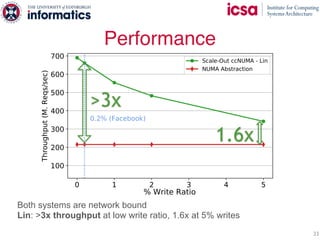
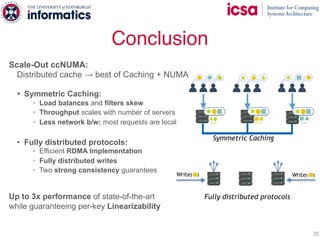
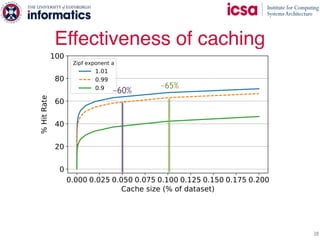
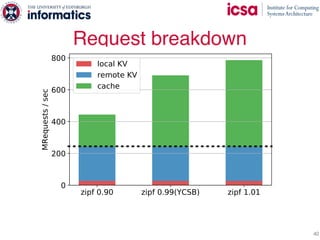
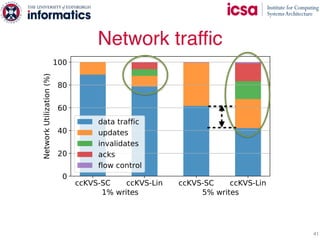
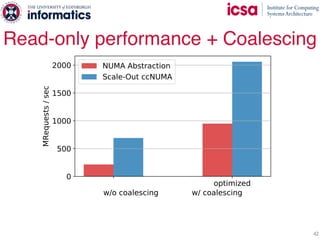
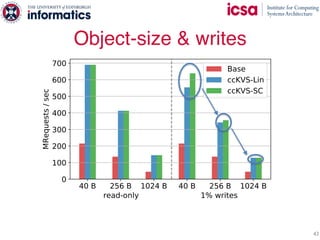
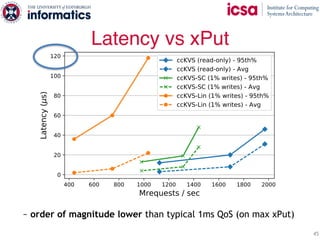
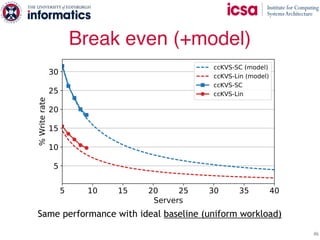
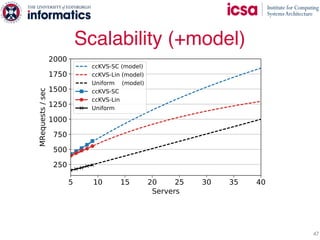
The document discusses the challenges and solutions of scaling distributed key-value stores (KVS) by implementing a hybrid model called scale-out ccNUMA, which integrates symmetric caching to balance loads while maintaining consistency. It highlights issues related to skewed access distribution leading to performance bottlenecks and presents caching strategies that improve system throughput by distributing hot objects effectively across nodes. The proposed methods show significant performance improvements, achieving up to three times the throughput compared to traditional systems while ensuring strong consistency guarantees.


![Large-scale online services
2
Backed by Key-Value Stores (KVS)
Characteristics:
• Numerous users
• Read-mostly workloads
( e.g. Facebook 0.2% writes [ATC’13] )
Distributed KVS](https://image.slidesharecdn.com/scale-outccnumaeurosyspdf-180426181718/85/Scale-out-ccNUMA-Eurosys-18-2-320.jpg)





![Centralized cache [SOCC’11, SOSP’17]
• Dedicated node resides in front of the KVS
caching hot objects.
◦ Filters the skew with a small cache
◦ Throughput is limited by the single cache
Existing Skew Mitigation Techniques
10
… … …
← Cache](https://image.slidesharecdn.com/scale-outccnumaeurosyspdf-180426181718/85/Scale-out-ccNUMA-Eurosys-18-10-320.jpg)
![Centralized cache [SOCC’11, SOSP’17]
• Dedicated node resides in front of the KVS
caching hot objects.
◦ Filters the skew with a small cache
◦ Throughput is limited by the single cache
NUMA abstraction [NSDI’14, SOCC’16]
• Uniformly distribute requests to all servers
• Remote objects RDMA’ed from home node
◦ Load balance the client requests
◦ No locality → excessive network b/w
Most requests require remote access
Existing Skew Mitigation Techniques
11
… … …
… … …
← Cache](https://image.slidesharecdn.com/scale-outccnumaeurosyspdf-180426181718/85/Scale-out-ccNUMA-Eurosys-18-11-320.jpg)
![Centralized cache [SOCC’11, SOSP’17]
• Dedicated node resides in front of the KVS
caching hot objects.
◦ Filters the skew with a small cache
◦ Throughput is limited by the single cache
NUMA abstraction [NSDI’14, SOCC’16]
• Uniformly distribute requests to all servers
• Remote objects RDMA’ed from home node
◦ Load balance the client requests
◦ No locality → excessive network b/w
Most requests require remote access
Existing Skew Mitigation Techniques
12
… … …
… … …
Can we get the best of both worlds?
← Cache](https://image.slidesharecdn.com/scale-outccnumaeurosyspdf-180426181718/85/Scale-out-ccNUMA-Eurosys-18-12-320.jpg)






































































![[VLDB'25] The LAW Theorem: Local Reads and Linearizable Asynchronous Replication](https://cdn.slidesharecdn.com/ss_thumbnails/law-vldb25-latestv3-251019111018-53070a6a-thumbnail.jpg?width=640&height=640&fit=bounds)






![Zeus: Locality-aware Distributed Transactions [Eurosys '21 presentation]](https://cdn.slidesharecdn.com/ss_thumbnails/zeus-eurosys21-210419094422-thumbnail.jpg?width=640&height=640&fit=bounds)