DNS 라운드로빈과 로드밸런서의차이
• DNS Round Robin
– DNS를 이용해서 하나의 서비스에 여러 대의
서버를 분산시키는 방법.
– 웹 서버 마다 공인 IP 할당.
– 균등하게 분산 안됨.
– 웹 서버가 다운되어도 감지 못함.
3.
DNS 라운드로빈과 로드밸런서의차이
• Load Balancer
– 하나의 IP주소에 대해 요청을 복수의 서버로
분산.
– 공인 IP를 가진 가상적인 서버로 동작하여 요
청의 대해 실제 웹 서버로 중계 역할.
– 여러 대의 리얼 서버중 한 대를 선택해서 중계.
– 고가의 장비 및 유지 보수 비용이 큼.
• 비용 절약으로인한 OSS(opensource
software) 구축
4.
IPVS-리눅스로 로드밸런서 구성
•리눅스로 특별한 S/W 없이 라우터 운용가능.
• IPVS(IP Virtual Server)라는 부하 분산 기능을 제공
하는 모듈도 포함.
• 로드밸런서 종류와 IPVS 기능
– L4 스위치
• 트랜스 포트 계층까지 의 정보를 분석.
• IP, Port에 따라 분산대상 서버지정.
– L7 스위치
• 애플리케이션 계층까지 정보를 분석.
• URL에 따라 분산대상 서버 지정.
– IPVS에 내장되어 있는 것은 L4 스위치에 해당.
• L7 스위치는 이용불가.
5.
스케쥴링 알고리즘
• rr(round-robin)
– 차례대로 처리.
• wrr(weighted round-robin)
– rr + 가중치.
• lc(least-connection)
– 접속수가 가장 적은 서버 선택.
• wlc(weighted least-connection)
– lc + 가중치.
• sed(shortest expected delay)
– 응답속도가 가장 빠른 서버 선택.
• nq(never queue)
– sed와 동일 그러니 active 수가 0인 서버 최우선으로 선택.
6.
스케쥴링 알고리즘
• sh(sourcehashing)
– source ip 주소 해시 값 계산 후 분산 서버 선택.
• dh(destination hashing)
– 목적지 ip 주소 해시 값 계산 후 분산 서버 선택.
• lblc(locality-based least-connection)
– 접속수가 가중치로 지정한 값을 넘기 전까지 동일한 서버
선택.
• lblcr(locality-based least-connection with
replication)
– lblc + 모든 서버의 접속수가 가중치로 지정한 값을 넘는
경우 접속수가 가장 적은 서버 선택.
7.
IPVS 사용하기
• ipvsadm
– IPVS에서 제공하는 명령툴.
– 가상서버를 정의하고 리얼 서버를 할당.
– 접속상황,전송률, 통계정보를 제공.
• Keepalived
– IPVS를 이용하여 가상서버를 구축.
– 리얼 서버의 상태 체크.(다운 시 부하분산 제외)
• HTTP_GET, SSL_GET, TCP_CHECK, SMTP_CHECK,
MISC_CHECK
8.
L4스위치와 L7스위치
L4 스위치
L7 스위치
• L4스위치는 클라이언트가 통신하는 곳은 리얼 서버.
• L7 스위치에 클라이언트와 리얼 서버 각각의 TCP
세션을 전개.
9.
NAT와 DSR
• NAT(NetworkAddress Translation)
– 한 네트워크 컴퓨터의 IPv4 주소를 다른 네트워크 컴
퓨터의 IPv4 주소로 변환.
• DSR(Direct Server Return)
– 로드밸런서 사용시 리얼서버에서 클라이언트로 되돌아
가는 경우 목적지의 주소가 스위치 주소가 아닌 클라
이언트 주소로 전달하는 개념.
– 로드밸런서 병목, 높은 트래픽이 있는 경우 DSR로 권
장.
다중화 프로토콜 VRRP
•라우터나 로드밸러서 벤더들의 독자적인
다중화 프로토콜
– 서로 다른 벤더간 호환 불가.
• HSRP(Hot standby Routing Protocol)기
반으로 벤더에 의존하지 않는 다중화 프로
토콜 VRRP(Virtual Router Redundancy
Protocol) 개발.
14.
VRRP 패킷
• 마스터노드가 정기적으로 VRRP 패킷을 멀티캐스팅
(224.0.0.18)주소로 송신.
– 마스터가 정상 작동임을 알리는 메시지(Advertisement)
• 백업 노드는 VRRP 패킷을 수신하는 동안은 대기중, 일정
시간 수신 하지 못하면 마스터 노드 다운으로 판단 장애
극복 시작.
15.
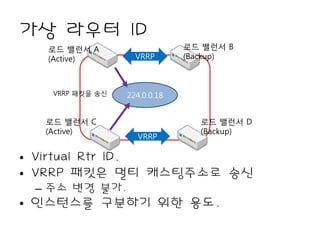
가상 라우터 ID
로드 밸런서 A 로드 밸런서 B
(Active) VRRP (Backup)
VRRP 패킷을 송신 224.0.0.18
로드 밸런서 C 로드 밸런서 D
(Active) (Backup)
VRRP
• Virtual Rtr ID.
• VRRP 패킷은 멀티 캐스팅주소로 송신
– 주소 변경 불가.
• 인스턴스를 구분하기 위한 용도.
16.
우선순위(Priority)
• Priority.
• VRRP구조적으로 100대의 백업 노드를 가
질수 있음.
• 백업 노드가 2대 이상 작동 시 우선순위
부여.
• 수치적으로 높을수록 우선순위가 높음.
• 사용범위는 1~255, 기본값은 100
17.
선점형 모드(Preemptive Mode)
•선점형 모드 유효화
– 자신의 Priority보다 낮은 값을 수신하면
master상태로 변경.
– Default mode.
• 선전형 모드 무효화
– 자신의 Priority 보다 낮은 값을 수신하더라도
현 상태를 유지.
18.
가상 MAC주소
• VRRP에는가상 MAC주소가 정의.
• 장애극복 시 IP주소뿐만 아니라, MAC주소
도 함께 인계.
– MAC 주소를 인계하지 않을 경우, 통신 상대
가 되는 모든 장비의 ARP 테이블의 변경 필요.
• Physical/Virtual 2가지 mode
– Default mode Virtual.
19.
Keepalived의 구조상의 문제
•Keepalived의 VRRP는 가상 MAC주소를 허용하지 않
음.
• 장애극복 시 ARP 엔트리가 갱신되지 않는 장비가 있
을 경우, APR 캐시가 clear가 되까지 통신되지 않을
위험성 소지.
• gratuitous ARP의 지연송신
– 마스터 상태로 변경 후 GARP를 송신 시 네트워크 상태 불
안정, 일시적인 트래픽이 집중되어 통신이 안될 수 있음.
– 수 초 정도 기다린 후 GARP 송신.
– grap_master_delay로 설정.
– Default value 5초.

























![[야생의 땅: 듀랑고] 서버 아키텍처 - SPOF 없는 분산 MMORPG 서버](https://cdn.slidesharecdn.com/ss_thumbnails/public-140529222503-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)






![[NDC17] Kubernetes로 개발서버 간단히 찍어내기](https://cdn.slidesharecdn.com/ss_thumbnails/ndc-170529041601-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DEVIEW 2021] 1000만 글로벌 유저를 지탱하는 기술과 사람들](https://cdn.slidesharecdn.com/ss_thumbnails/1000-deview-220204010915-thumbnail.jpg?width=640&height=640&fit=bounds)


















![[오픈소스컨설팅]Zabbix Installation and Configuration Guide](https://cdn.slidesharecdn.com/ss_thumbnails/zabbixinstallationconfigurationguide-130702191713-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)























































