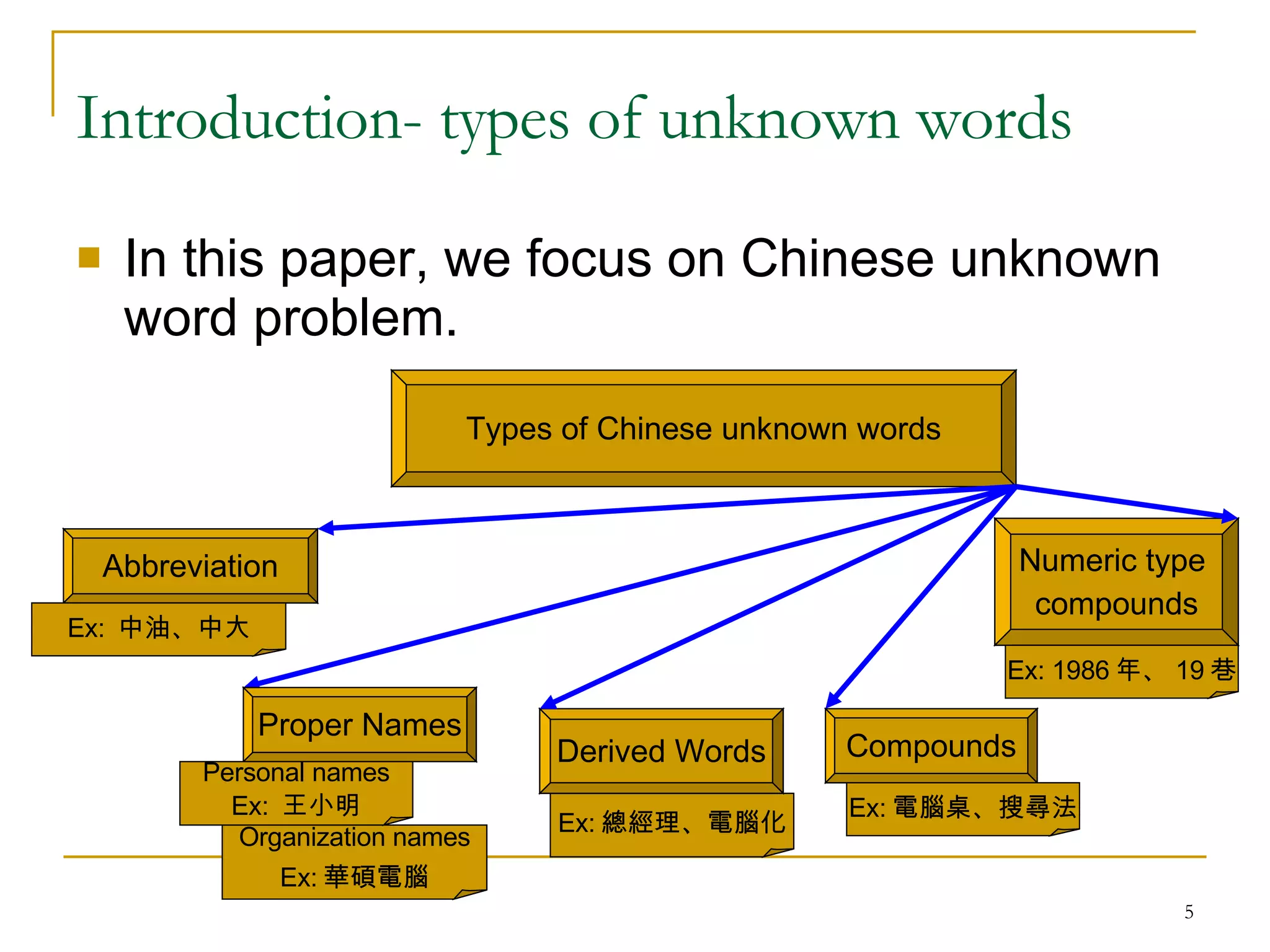
The document discusses using pattern mining and machine learning techniques to identify and extract unknown words from Chinese text. It begins with an introduction on Chinese word segmentation challenges and types of unknown words. It then discusses related work using particular and general methods. The main techniques described are using continuity pattern mining to derive unknown word detection rules (Phase 1), and applying machine learning classification and sequential learning for extraction (Phase 2). Experimental results show improvements over previous work, with an F1-score of 0.614 for unknown word extraction.







![Related Works- particular methods So far, research on Chinese word segmentation has lasted for a decade. First, researchers apply different kinds of information to discover different kinds of unknown words (particular). Proper nouns (Chinese personal names 、 transliteration names 、 Organization names) <[Chen & Li, 1996] 、 [Chen & Chen, 2000]> Patterns, Frequency, Context Information](https://image.slidesharecdn.com/pattern-mining-to-unknown-word-extraction-1014-seminar-1224076974514338-9/75/Pattern-Mining-To-Unknown-Word-Extraction-10-9-2048.jpg)
![Related Works- general methods (Rule-based) Then, researchers start to figure out methods extracting whole kinds of unknown words. Rule-based Detection and Extraction: <[Chen et al., 1998]> Distinguish monosyllabic words and monosyllabic morphemes <[Chen et al., 2002]> Combine Morphological rules with Statistical rules to extract personal names 、 transliteration names and compound nouns. (Precision: 89%, Recall: 68%) <[Ma et al., 2003]> Utilize context free grammar concept and propose a bottom-up merging algorithm Adopt morphological rules and general rules to extract all kinds of unknown words. ( Precision: 76%, Recall: 57%)](https://image.slidesharecdn.com/pattern-mining-to-unknown-word-extraction-1014-seminar-1224076974514338-9/75/Pattern-Mining-To-Unknown-Word-Extraction-10-10-2048.jpg)
![Related Works- general methods (Machine Learning-based) Sequential Learning: <[T. G. Dietterich, 2002]> Transform sequential learning problem into classification problem Direct method, like HMM 、 CRF <[Goh et. al, 2006]> HMM+SVM, (Precision: 63.8%, Recall: 58.3%) <[Tsai et. al, 2006]> CRF, (Recall: 73%) Indirect method, like Sliding Window 、 Recurrent Sliding Windows](https://image.slidesharecdn.com/pattern-mining-to-unknown-word-extraction-1014-seminar-1224076974514338-9/75/Pattern-Mining-To-Unknown-Word-Extraction-10-11-2048.jpg)
![Related Works – Imbalanced Data Imbalance Data Problem Ensemble method <C. Li, 2007> Combine learning ability of multiple base classifiers using voting. Cost-sensitive learning and sampling <G. M. Weiss et. al, 2007> Focus more on minority class examples. <C. Drummond et. al, 2003> Under-sampling is more sensitive than over-sampling. <[Seyda et. al, 2007]> Select the most informative instances.](https://image.slidesharecdn.com/pattern-mining-to-unknown-word-extraction-1014-seminar-1224076974514338-9/75/Pattern-Mining-To-Unknown-Word-Extraction-10-12-2048.jpg)
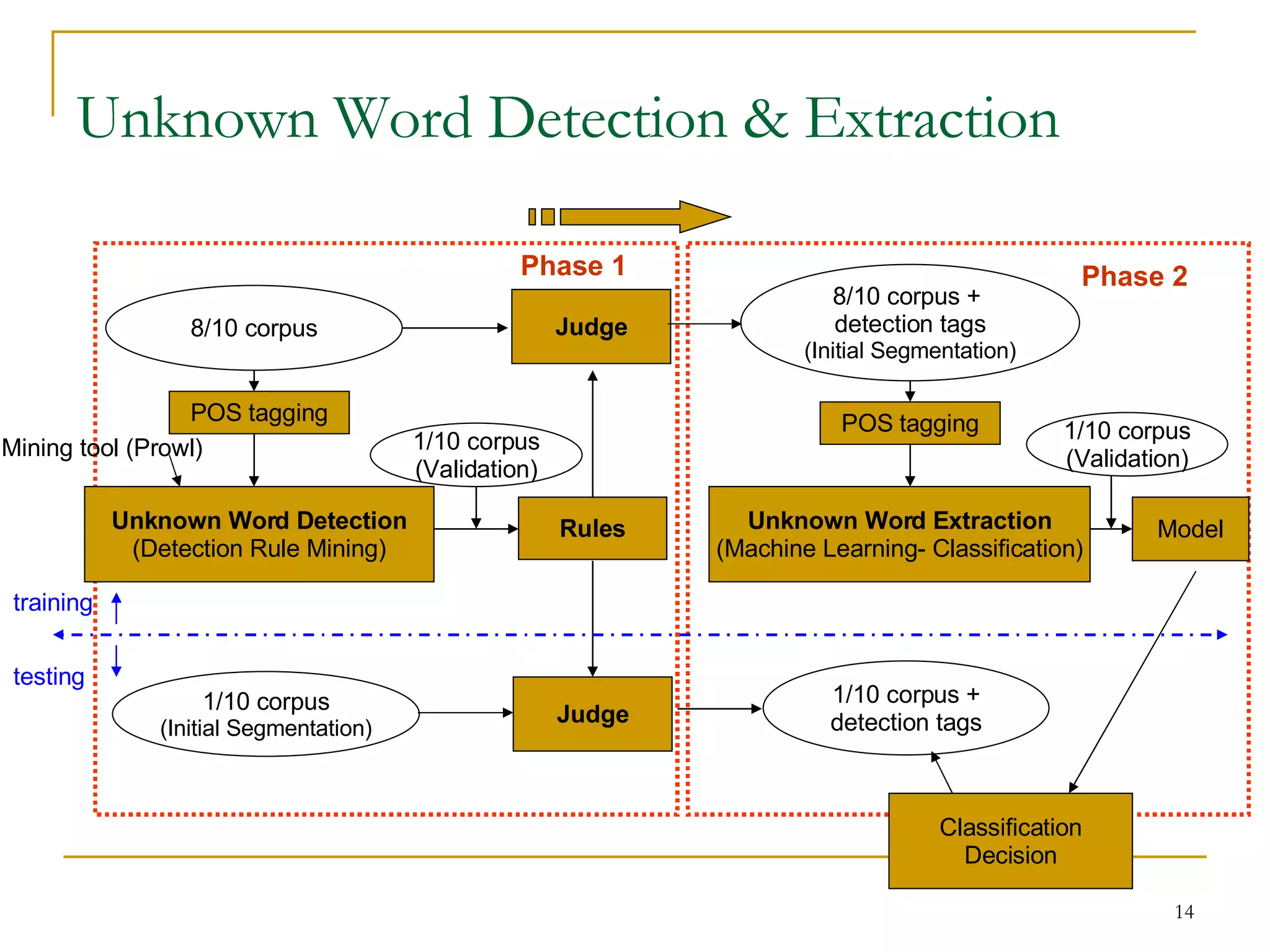
![Unknown Word Detection & Extraction Our idea is similar to [Chen et al, 2002]: Unknown word detection Continuity pattern mining to derive detection rules. Unknown word extraction Machine learning based – classification algorithms and sequential learning (indirect). We call: unknown word detection as “Phase 1” unknown word extraction as “Phase 2”.](https://image.slidesharecdn.com/pattern-mining-to-unknown-word-extraction-1014-seminar-1224076974514338-9/75/Pattern-Mining-To-Unknown-Word-Extraction-10-13-2048.jpg)


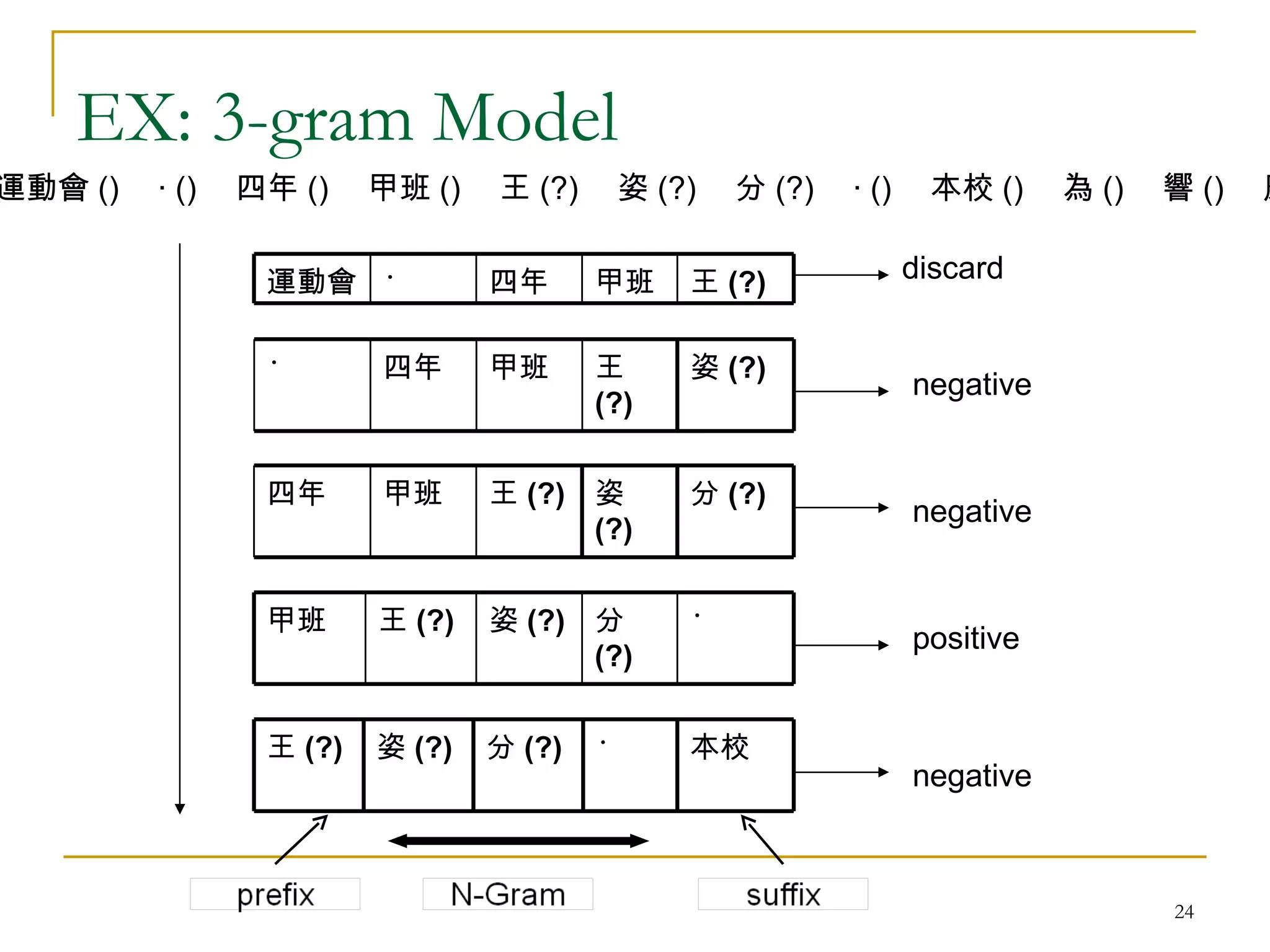
![Unknown word detection- Continuity Pattern Mining Prowl <[Huang et. al, 2004]> Starts with 1-frequent pattern Extend to 2 pattern by two adjacent 1-frequent patterns, then evaluate its frequency. Iteratively extends to longer length of patterns.](https://image.slidesharecdn.com/pattern-mining-to-unknown-word-extraction-1014-seminar-1224076974514338-9/75/Pattern-Mining-To-Unknown-Word-Extraction-10-17-2048.jpg)







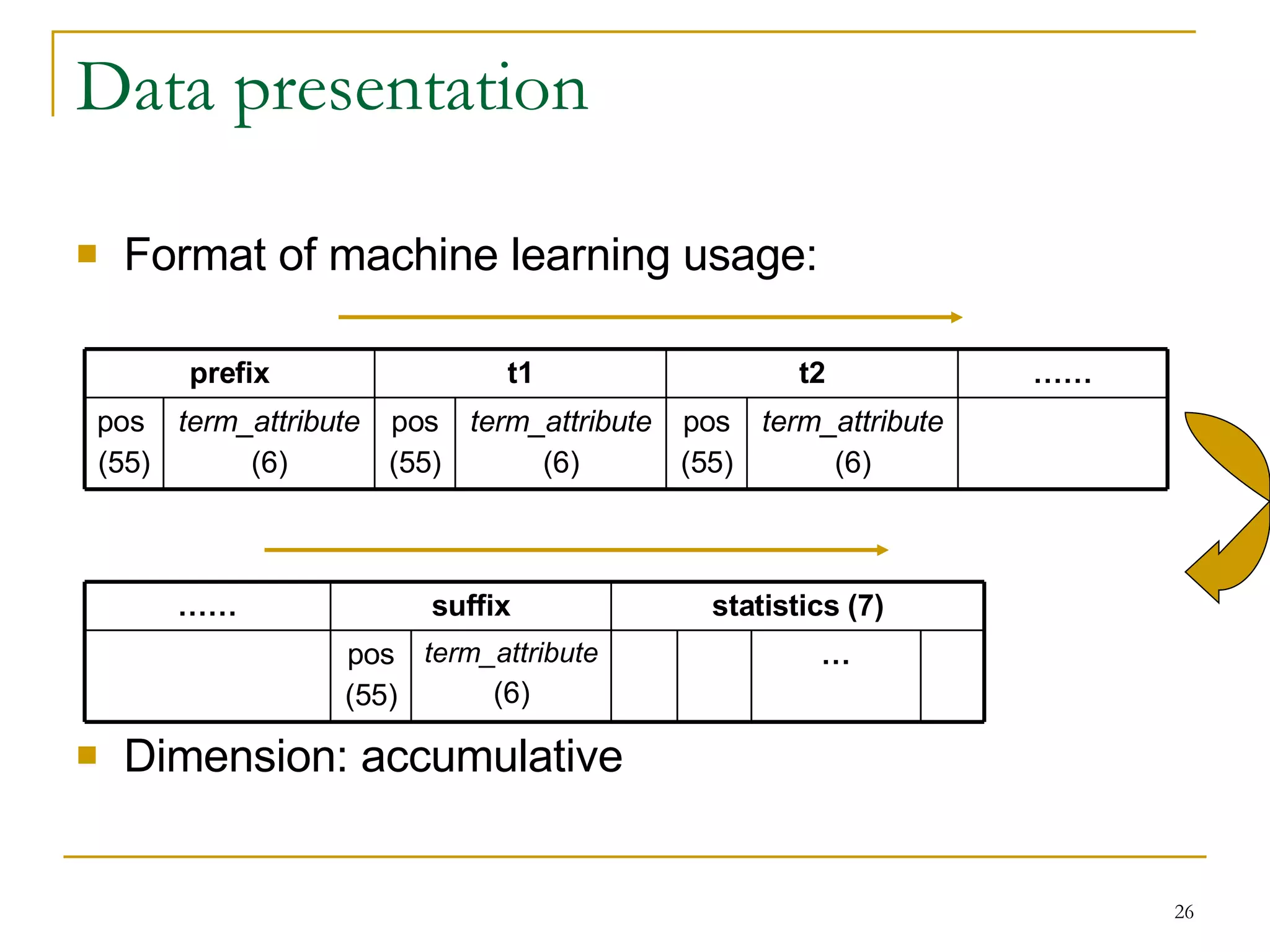

![Unknown Word Detection 8/10 balanced corpus (460m words) as training data. Use Pattern mining tool: Prowl [Huang et al., 2004] 1/10 balanced corpus as validation data. Use accuracy and frequency as threshold of detection rules. 1/10 balanced corpus as real test data (for phase 2): 60.3% precision and 93.6% recall Threshold (Accuracy) Precision Recall F-measure (our system) F-measure (AS system) 0.7 0.9324 0.4305 0.589035 0.71250 0.8 0.9008 0.5289 0.66648 0.752447 0.9 0.8343 0.7148 0.769941 0.76955 0.95 0.764 0.8288 0.795082 0.76553 0.98 0.686 0.8786 0.770446 0.744036 0.76158 0.9092 0.6552 29 0.77033 0.780085 0.787466 0.795082 F-measure 0.8995 0.8932 0.8819 0.8288 Recall 0.6736 0.6924 0.7113 0.764 Precision 19 11 7 3 Fre>=](https://image.slidesharecdn.com/pattern-mining-to-unknown-word-extraction-1014-seminar-1224076974514338-9/75/Pattern-Mining-To-Unknown-Word-Extraction-10-28-2048.jpg)

![Unknown Word Extraction In judging overlap and conflict problem of different combination of unknown words : <[Chen et al., 2002]> frequency (w) * length (w) . Ex: “ 律師 班 奈 特” , => freq( 律師 + 班 )*3 : freq( 班 + 奈 + 特 )*3 Our method: First solve identical N-gram overlap : P (combine | overlap) Ex: “ 單 親 家庭” : P( 單親 | 親 ) : P( 親家庭 | 親 ) Then solve different N-gram conflict : Real frequency freq (X)-freq (Y), if X is included in Y ex: X=“ 醫學”、“學院” , Y=“ 醫學院”](https://image.slidesharecdn.com/pattern-mining-to-unknown-word-extraction-1014-seminar-1224076974514338-9/75/Pattern-Mining-To-Unknown-Word-Extraction-10-30-2048.jpg)
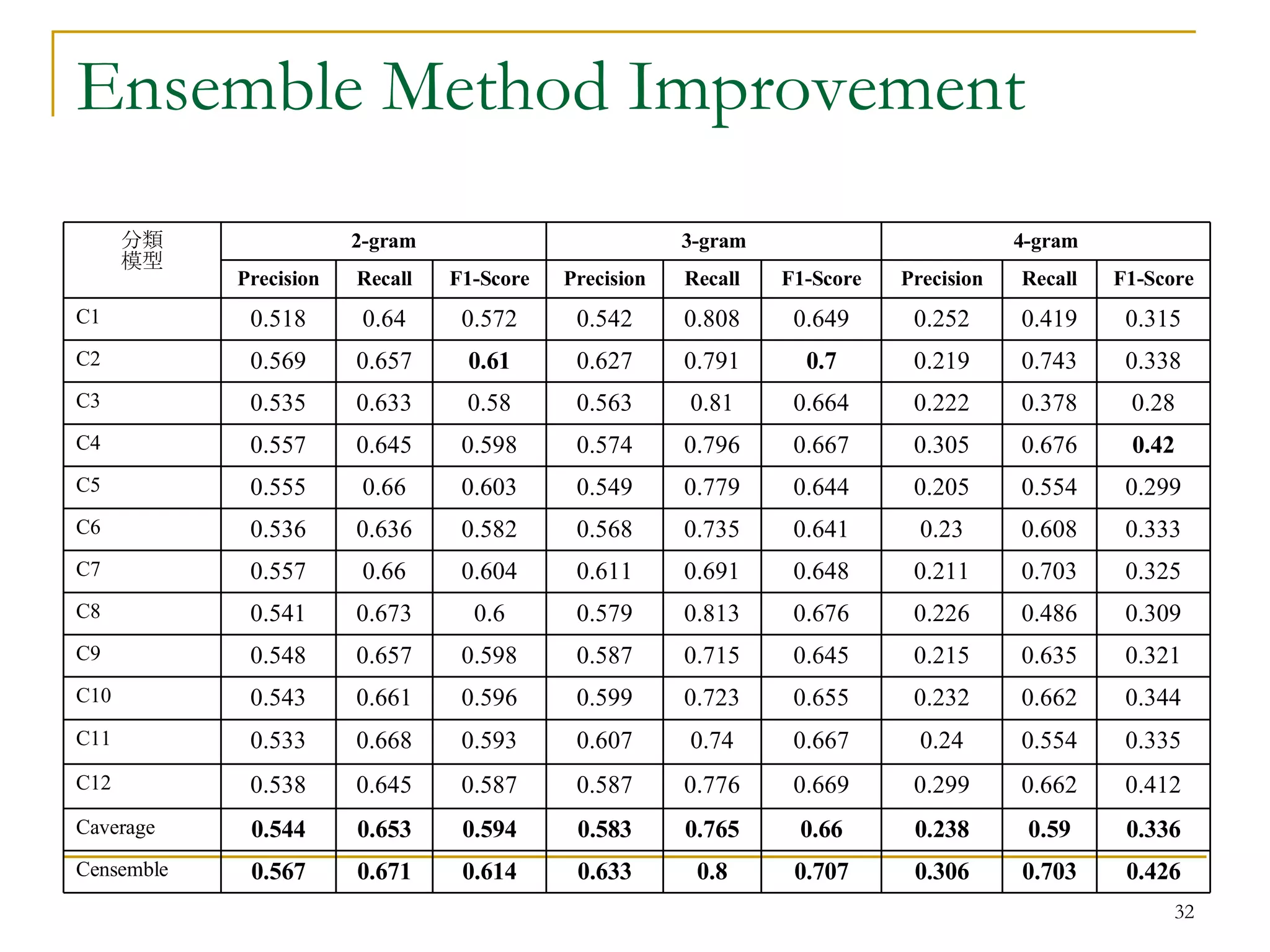
![Extraction result Comparison: <[Ma et al., 2003]> morphological rules+ statistical rules+ context free grammar rules Precision: 76%, Recall: 57% Our result 0.627 68.2% 58.1% Total 0.614 67.1% 56.7% 2-gram 0.707 80% 63.3% 3-gram 0.426 70.3% 30.6% 4-gram F1-score Recall Precision n-gram](https://image.slidesharecdn.com/pattern-mining-to-unknown-word-extraction-1014-seminar-1224076974514338-9/75/Pattern-Mining-To-Unknown-Word-Extraction-10-31-2048.jpg)













![[系列活動] 文字探勘者的入門心法](https://cdn.slidesharecdn.com/ss_thumbnails/textmininghandout-170320140215-170327095320-thumbnail.jpg?width=640&height=640&fit=bounds)

































































