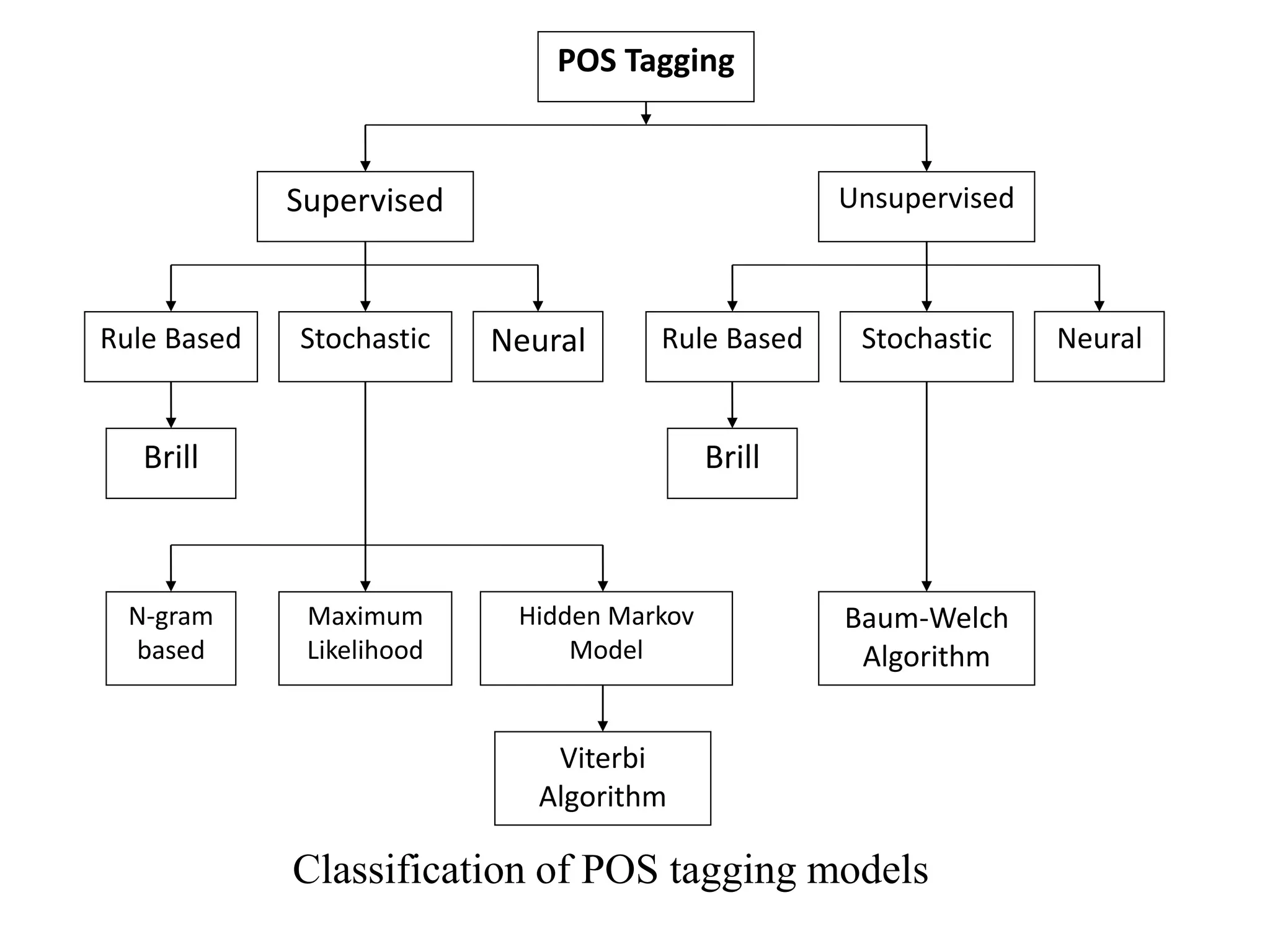
This document provides an overview of basic probability concepts and statistical methods. It discusses probability as it relates to outcomes and events, and as the tool used in statistics to make inferences from samples. It then covers specific probability concepts like n-gram models, which use the previous n-1 words to predict the next word. The document also summarizes part-of-speech tagging methods, including rule-based, supervised stochastic, and unsupervised approaches. Freely available POS taggers for various languages are also listed.



![Probability theory is a formal way of representing
probabilistic concepts and describing uncertain
events.
Probability is a mapping from the set of events or
sample space into the set [0, 1].
Naturally, the probability of a particular event or set
of events is the fraction of the time that the particular
event or set of events occur.
Thus, a probability mapping goes from the set of all
possible events to their respective probabilities of
occurring.](https://image.slidesharecdn.com/7probabilityandstatisticsanintroduction-190919173706/75/7-probability-and-statistics-an-introduction-4-2048.jpg)
























![Some models also use information about capitalization and
punctuation, the usefulness of which are largely dependent
on the language being tagged.
The earliest algorithms for automatically assigning Part-of-
Speech were based on a two-stage architecture [Harris Z. S,
1962].
The first stage used a dictionary to assign each word a list of
potential parts of speech.
The second stage used large lists of hand-written disambiguation
rules to bring down this list to a single Part-of-Speech for each
word.](https://image.slidesharecdn.com/7probabilityandstatisticsanintroduction-190919173706/75/7-probability-and-statistics-an-introduction-40-2048.jpg)
![The ENGTWOL [Voutilainen Atro, 1995] tagger is based on the
same two-stage architecture, although both the lexicon and the
disambiguation rules are much more sophisticated than the early
algorithms.
The ENGTWOL lexicon is based on the two-level morphology.
It has about 56,000 entries for English word stems, counting a
word with multiple parts of speech (e.g. nominal and verbal
senses of hit) as separate entries, and of course not counting
inflected and many derived forms.
Each entry is annotated with a set of morphological and
syntactic features. In the first stage of the tagger, each word is
run through the two-level lexicon transducer and the entries for
all possible parts of speech are returned.](https://image.slidesharecdn.com/7probabilityandstatisticsanintroduction-190919173706/75/7-probability-and-statistics-an-introduction-41-2048.jpg)




![Apart from these, quiet a few different approaches to
tagging have been developed.
Support Vector Machines: This is the powerful machine
learning method used for various applications in NLP and
other areas like bio-informatics, data mining, etc.
Neural Networks: These are potential candidates for the
classification task since they learn abstractions from
examples [Schmid H, 1994].
Decision Trees:
A decision tree is a decision support tool that uses a tree-
like graph. It is one way to display an algorithm.](https://image.slidesharecdn.com/7probabilityandstatisticsanintroduction-190919173706/75/7-probability-and-statistics-an-introduction-46-2048.jpg)
![These are classification devices based on hierarchical
clusters of questions. They have been used for natural
language processing such as POS Tagging [Schmid
H, 1994].
The software “Weka” can be used for classifying the
ambiguous words.](https://image.slidesharecdn.com/7probabilityandstatisticsanintroduction-190919173706/75/7-probability-and-statistics-an-introduction-47-2048.jpg)





![QTAG Part of speech tagger
An HMM-based Java POS tagger from
Birmingham U. (Oliver Mason). English and
German parameter files. [Java class files, not
source.]
The TOSCA/LOB tagger.
Currently available for MS-DOS only. But the
decision to make this famous system available is very
interesting from an historical perspective, and for software
sharing in academia more generally. LOB tag set.
Brill's Transformation-based learning Tagger
A symbolic tagger, written in C. It's no longer available from a
canonical location, but one may find a version from the
Wikipedia page or one can try a reimplementation such as
fnTBL.](https://image.slidesharecdn.com/7probabilityandstatisticsanintroduction-190919173706/75/7-probability-and-statistics-an-introduction-53-2048.jpg)






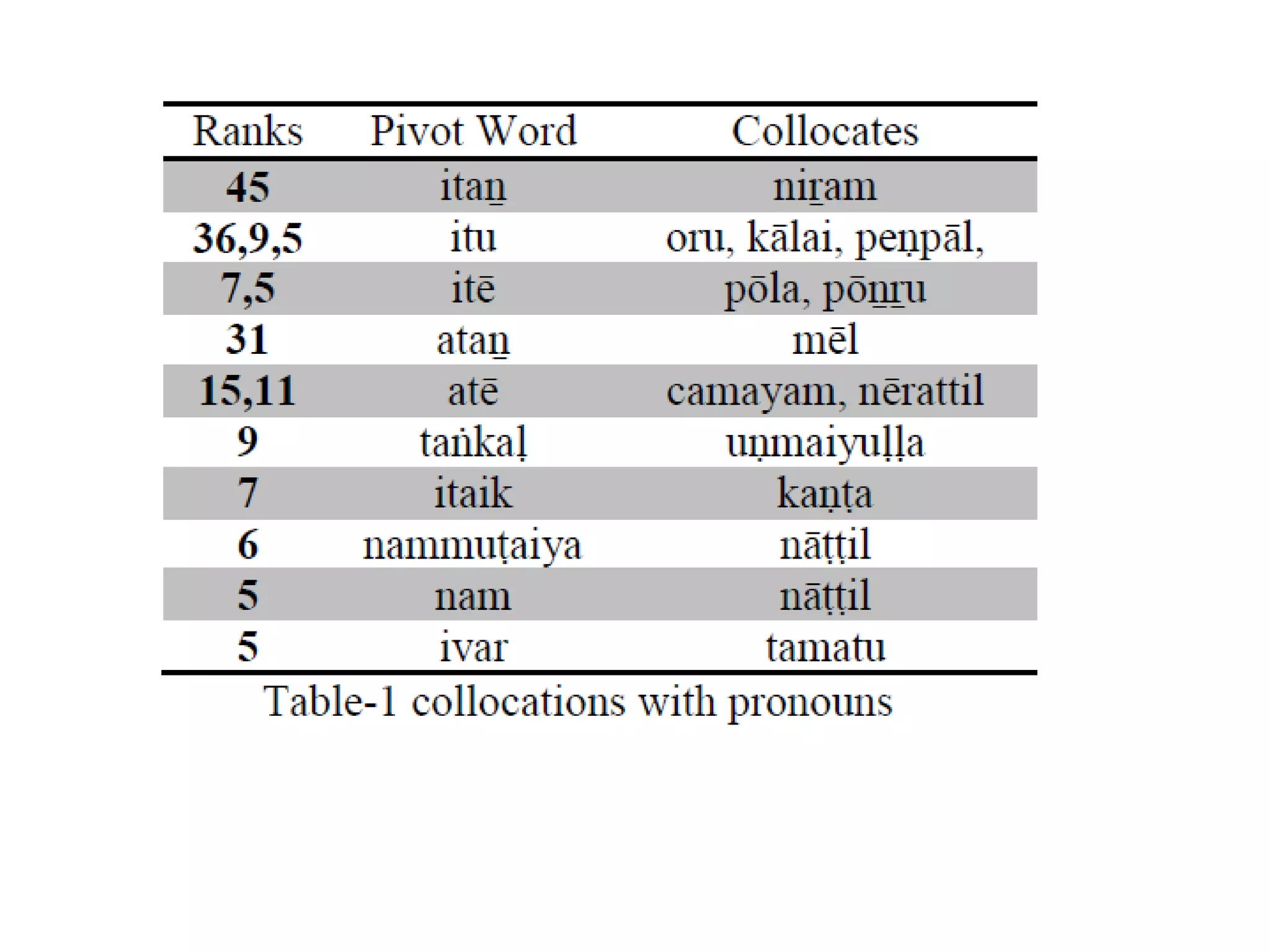
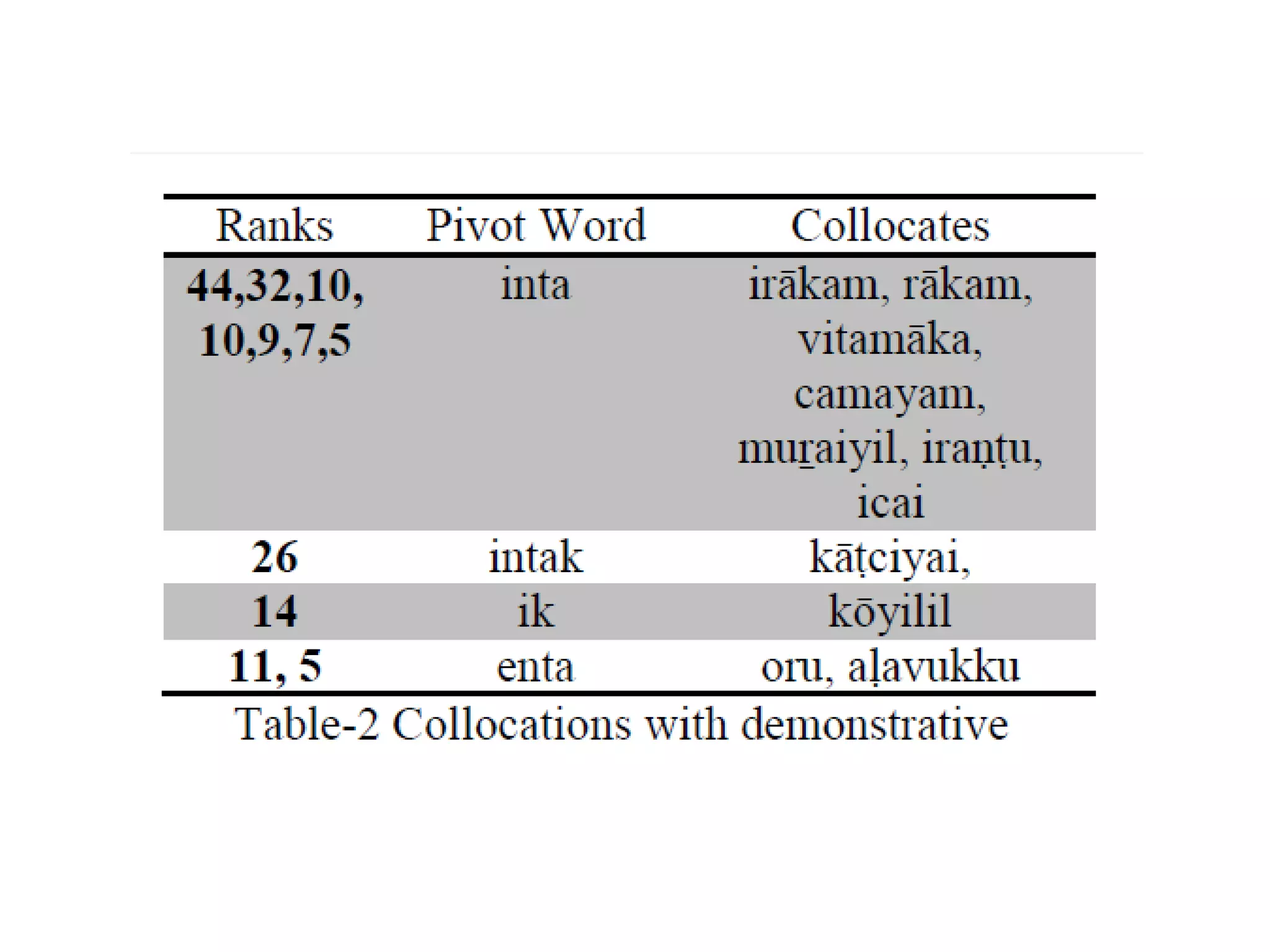
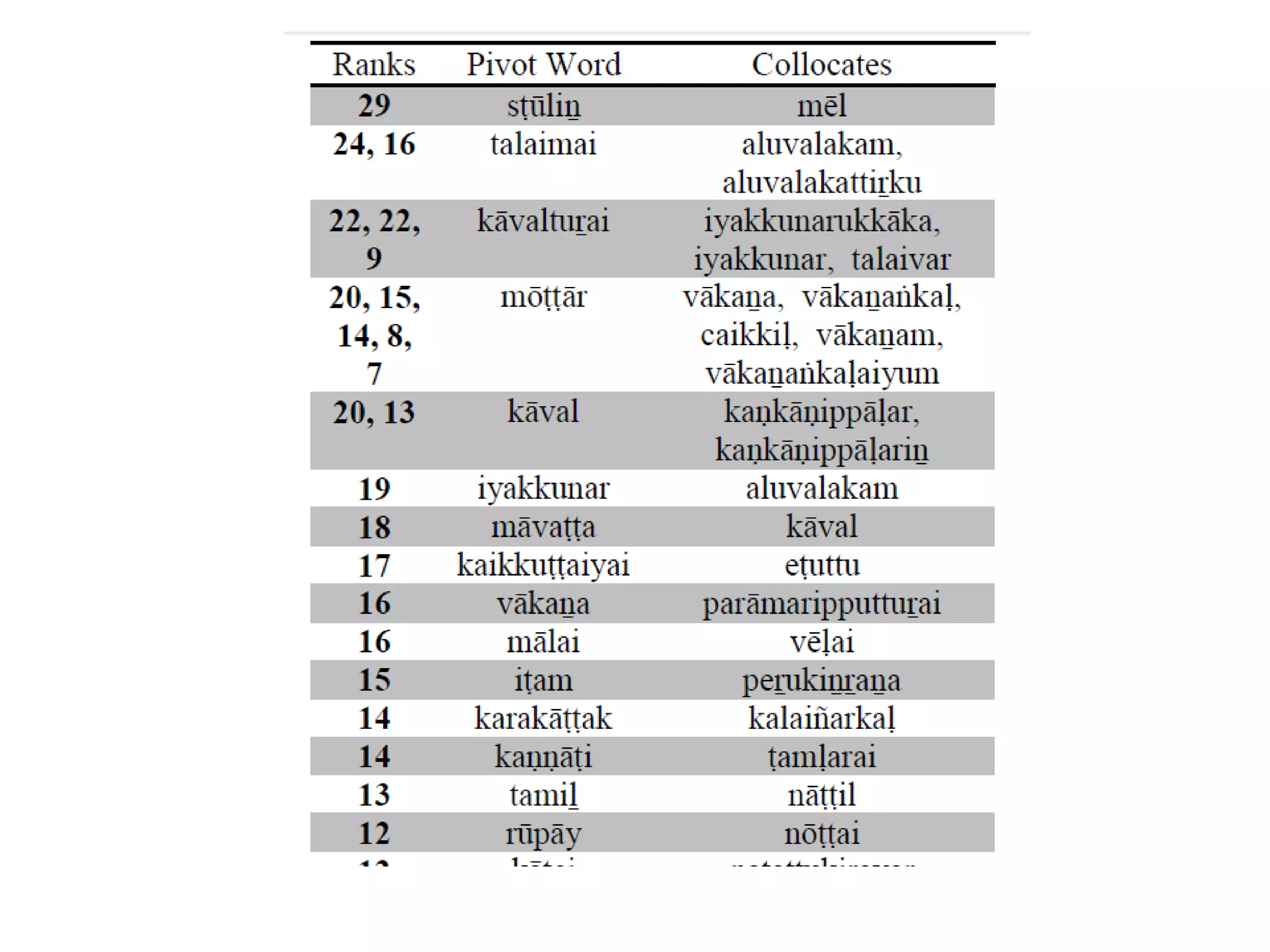
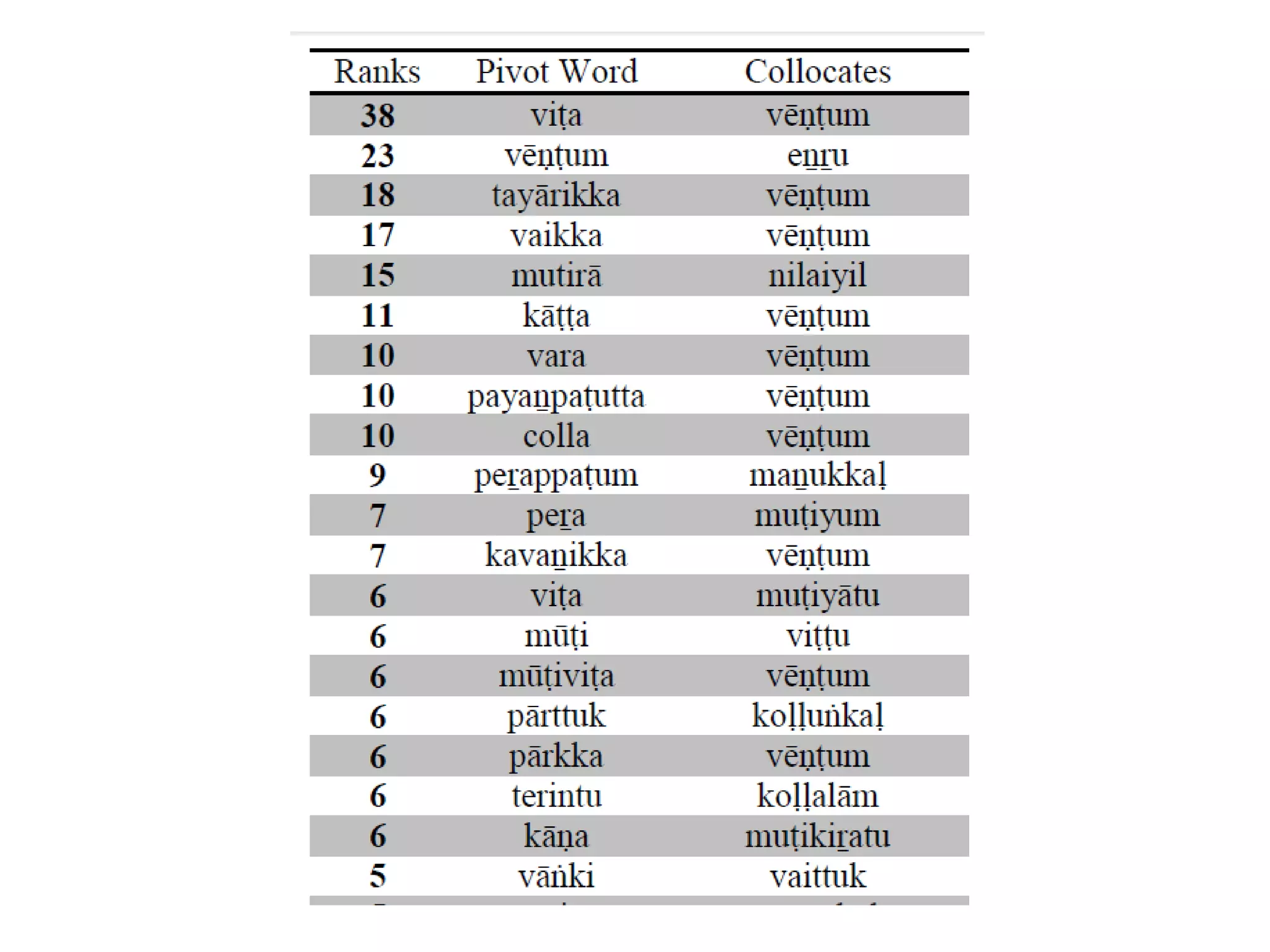
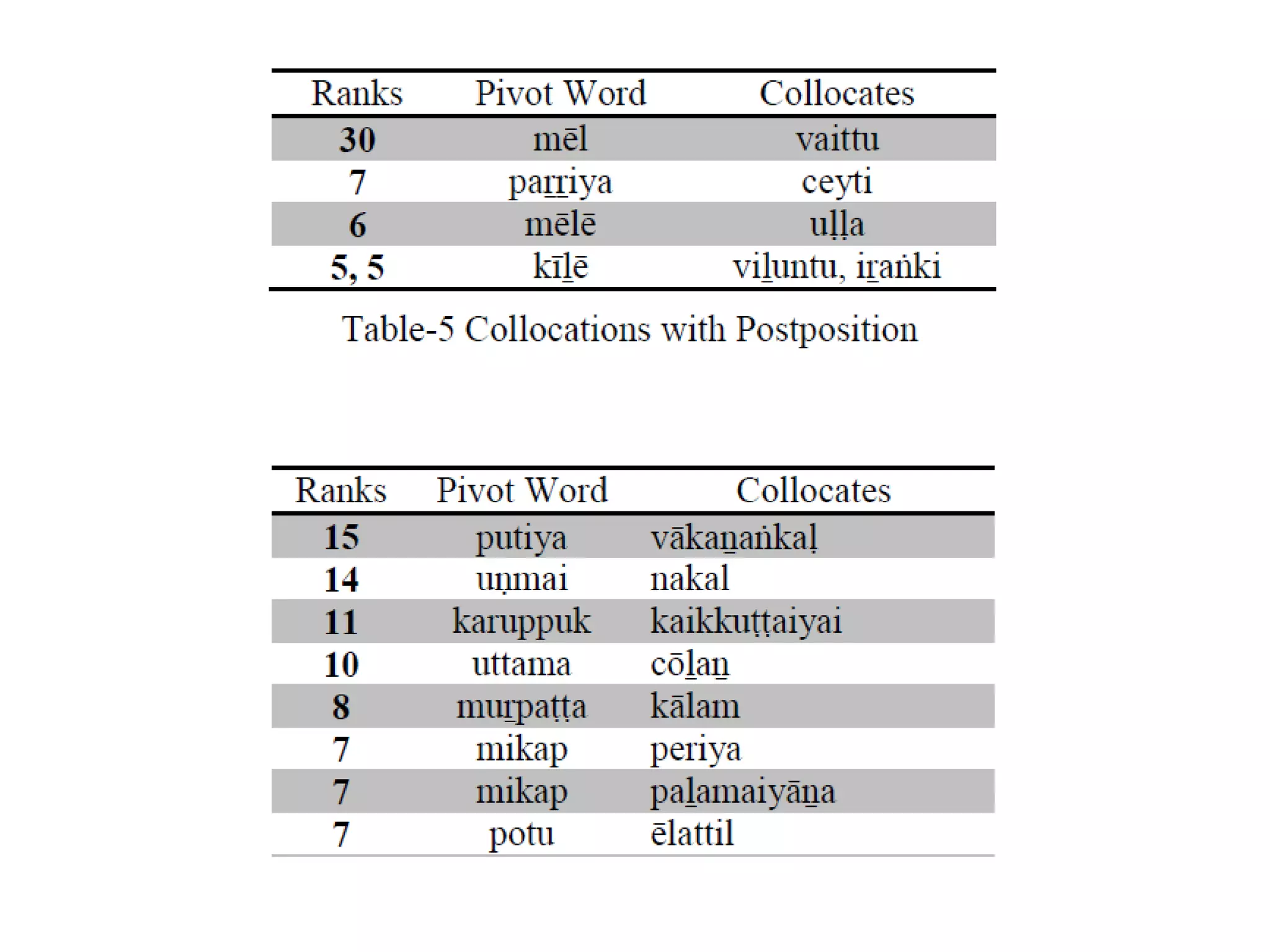
![Complexity in Dravidian POS tagging
As Dravidian is an agglutinative language, Nouns get
inflected for number and cases. Verbs get inflected for
various inflections which include tense, person, number,
gender suffixes.
Verbs are adjectivalized and adverbialized. Also verbs
and adjectives are nominalized by means of certain
nominalizers. Adjectives and adverbs do not inflect.
Many post-positions in Tamil [Arden 1942; Rajendran S,
2007] are from nominal and verbal sources. So, many
times one has to depend on the syntactic function or
context to decide upon whether one is a noun or adjective
or adverb or postposition.](https://image.slidesharecdn.com/7probabilityandstatisticsanintroduction-190919173706/75/7-probability-and-statistics-an-introduction-60-2048.jpg)







![For Telugu, three POS taggers have been proposed by using
different POS tagging approaches viz., (1) Rule-based
approach, (2) Transformation based learning (TBL)
approach of Erich Brill (3) Maximum Entropy Model, a
machine learning technique [Ramasree, R.J and Kusuma
Kumari, P, 2007].
Hidden Markov Model (HMM) based tagger for Hindi was
proposed by Manish Shrivastava and Pushpak Bhattacharyya
(2008). The authors attempted to utilize the morphological
richness of the languages without resorting to complex and
expensive analysis. The core idea of their approach was to
explode the input in order to increase the length of the input
and to reduce the number of unique types encountered during
learning. This in turn increases the probability score of the
correct choice while simultaneously decreasing the ambiguity
of the choices at each stage.](https://image.slidesharecdn.com/7probabilityandstatisticsanintroduction-190919173706/75/7-probability-and-statistics-an-introduction-68-2048.jpg)
![A stochastic Hidden Markov Model (HMM) based part of
speech tagger has been proposed for Malayalam. To perform
parts of tagging speech using stochastic approach, an annotated
corpus is needed. Due to the non-availability of annotated
corpus, a morphological analyzer was also developed to
generate a tagged corpus from the training set [Manju K e.tal,
2009].
Various methodologies have been developed for POS Tagging
for Tamil language. A rule-based POS tagger for Tamil was
developed and tested [Arulmozhi et al., 2004]. This system
gives only the major tags and the sub tags are overlooked
during evaluation. A hybrid POS tagger for Tamil using HMM
technique and a rule based system was also developed
[Arulmozhi P and Sobha L, 2006].](https://image.slidesharecdn.com/7probabilityandstatisticsanintroduction-190919173706/75/7-probability-and-statistics-an-introduction-69-2048.jpg)

![Considerable Effort of developing a POS Tagger in other
Indian Languages have also been put in for Malayalam, an
HMM based tagger was proposed by Manju et. al., since
they did not had an annotated corpus, they used a
morphological analyzer to generate the corpus which was
then used for training the HMM algorithm. Another tagger
for Malayalam was developed by Anthony et. al. [2009] who
used Support Vector Machines (SVM). They used a
SVMTool for tagging which was developed by Giménez and
Màrquez. For developing this tagger Anthony et. al. first
proposed a tagset which they claim is suitable for
Malayalam and then created an annotated corpus using this
tagset. Their tagger reported 94% accuracy with their tagset.](https://image.slidesharecdn.com/7probabilityandstatisticsanintroduction-190919173706/75/7-probability-and-statistics-an-introduction-71-2048.jpg)













































































