







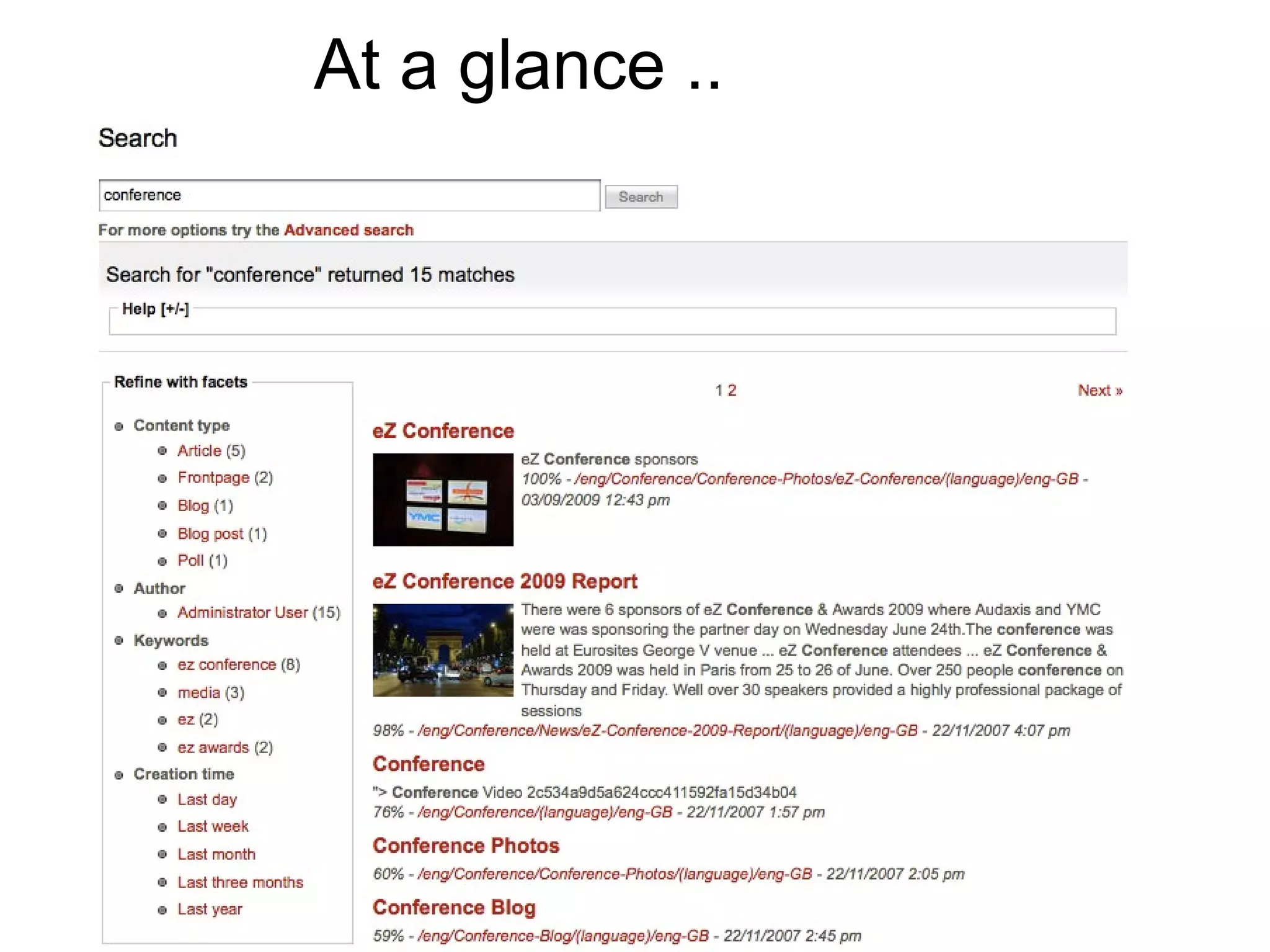



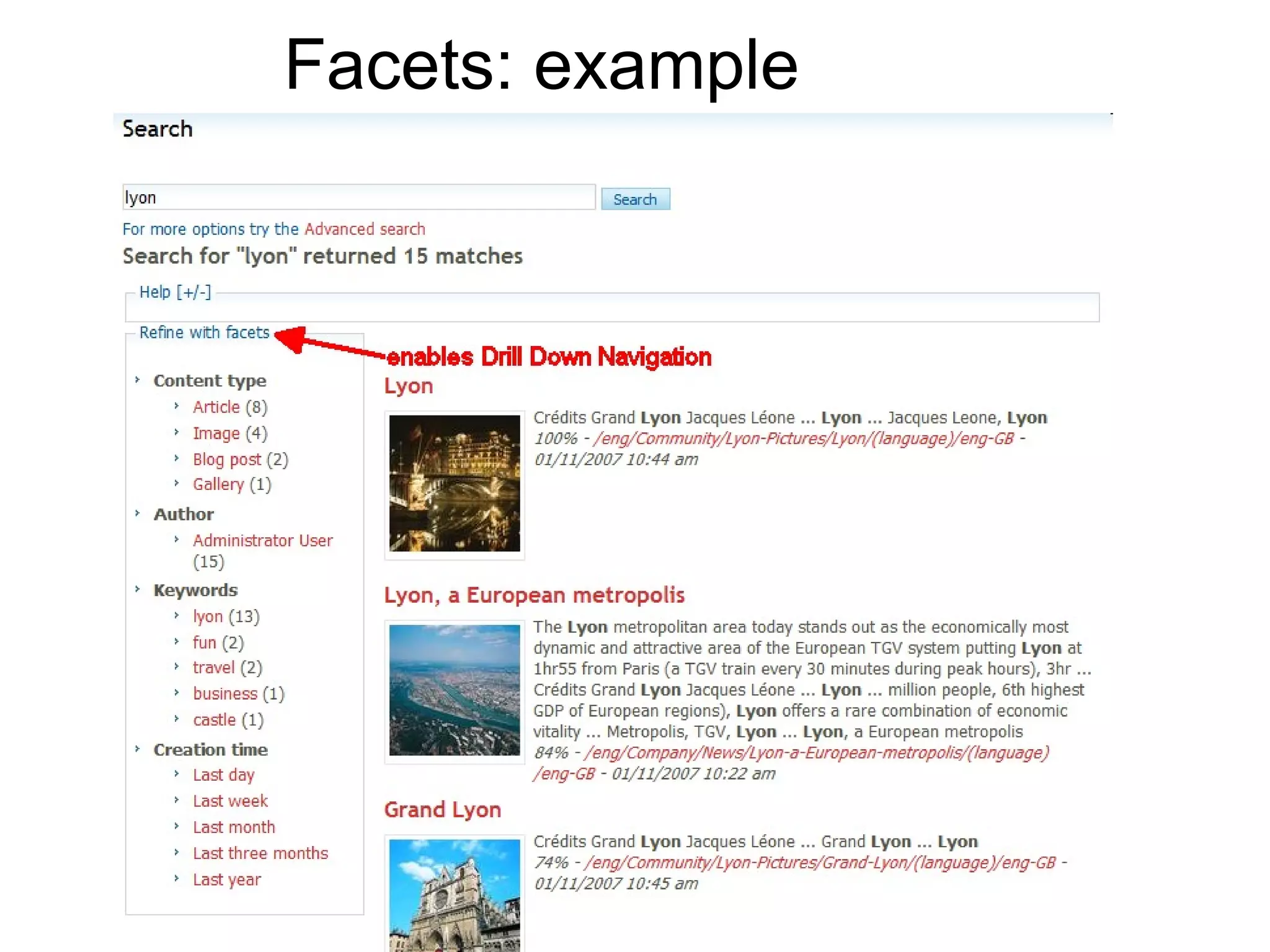



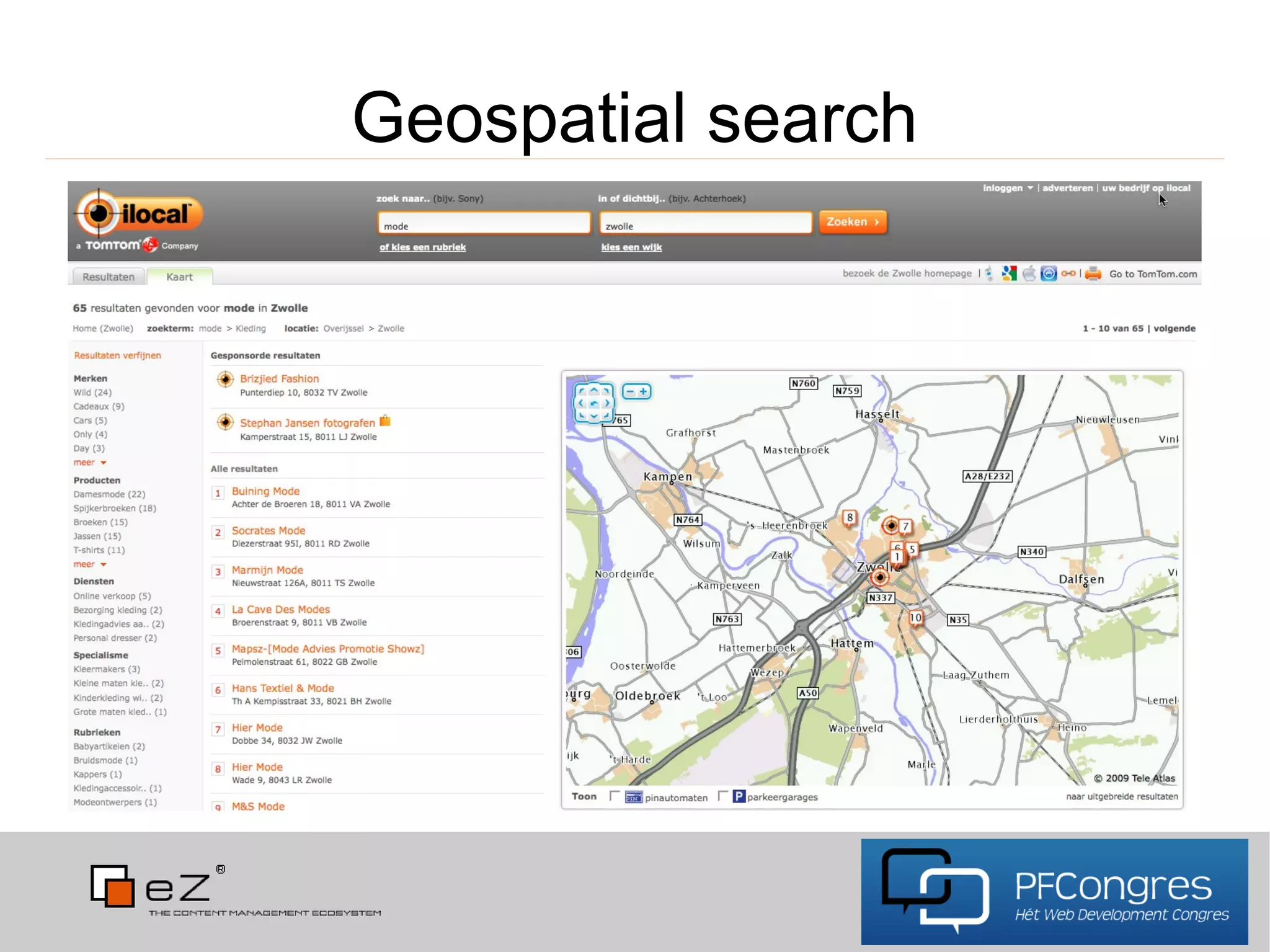
































The document discusses Apache Solr, an open-source search server built on top of the Apache Lucene project. It covers its internal concepts, features such as full-text search, relevancy ranking, geospatial search, and the flexible schema configurations available. Additionally, the document provides usage guidelines, use cases, and resources for integrating Solr with PHP and other applications.






















































