Downloaded 110 times

















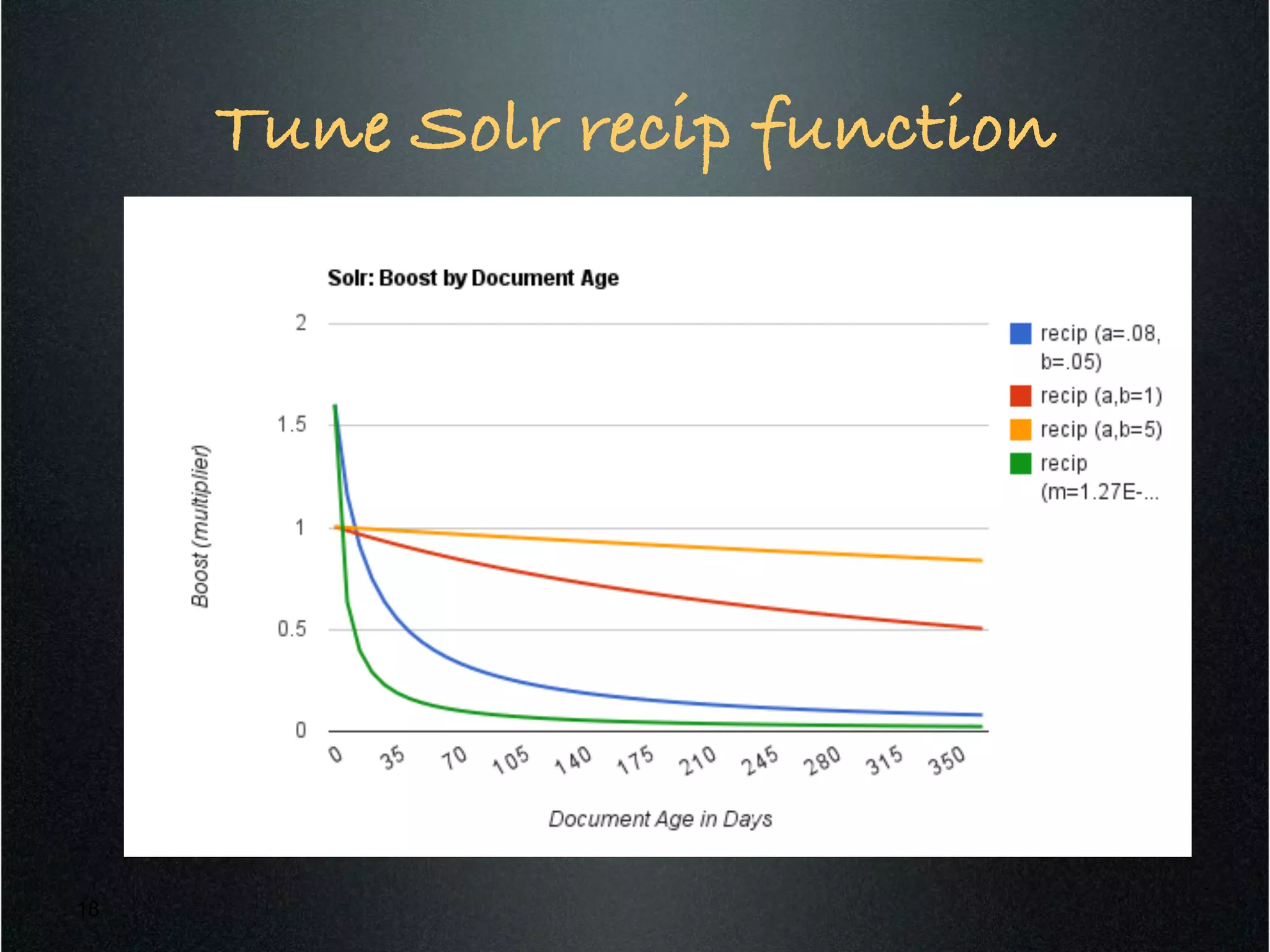


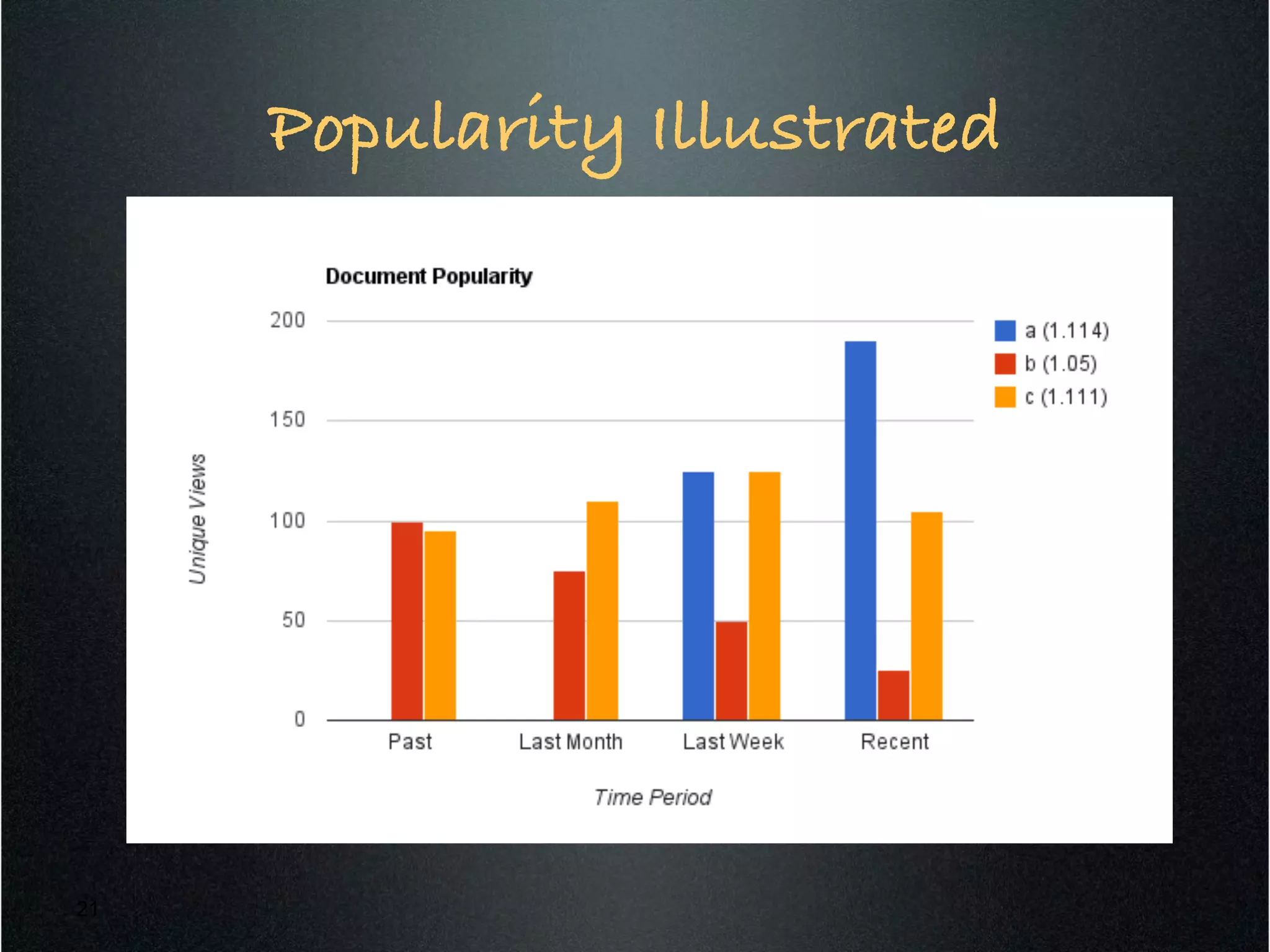

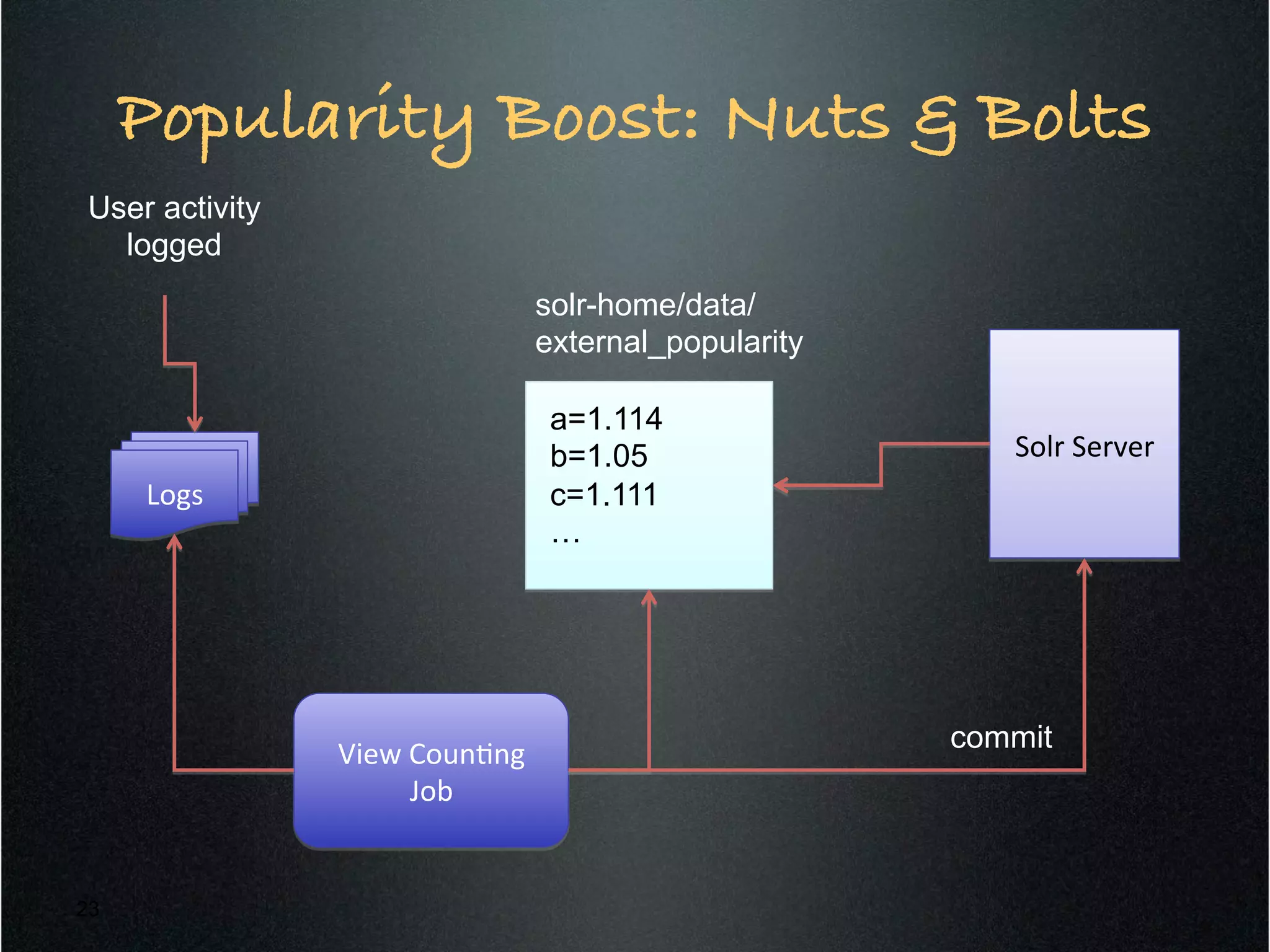






Apache Solr is a standalone full-text search server built on Apache Lucene. It exposes Lucene's Java API through REST-like endpoints that can be called from any programming language. Solr provides features like full-text search, faceted navigation, spell checking, result highlighting and more. It also includes capabilities for result grouping, query elevation, pivot facets, and pluggable workflows. Documents can be boosted based on age, popularity, and user preferences through functions and external fields in Solr.




















































































