Recommended
PDF
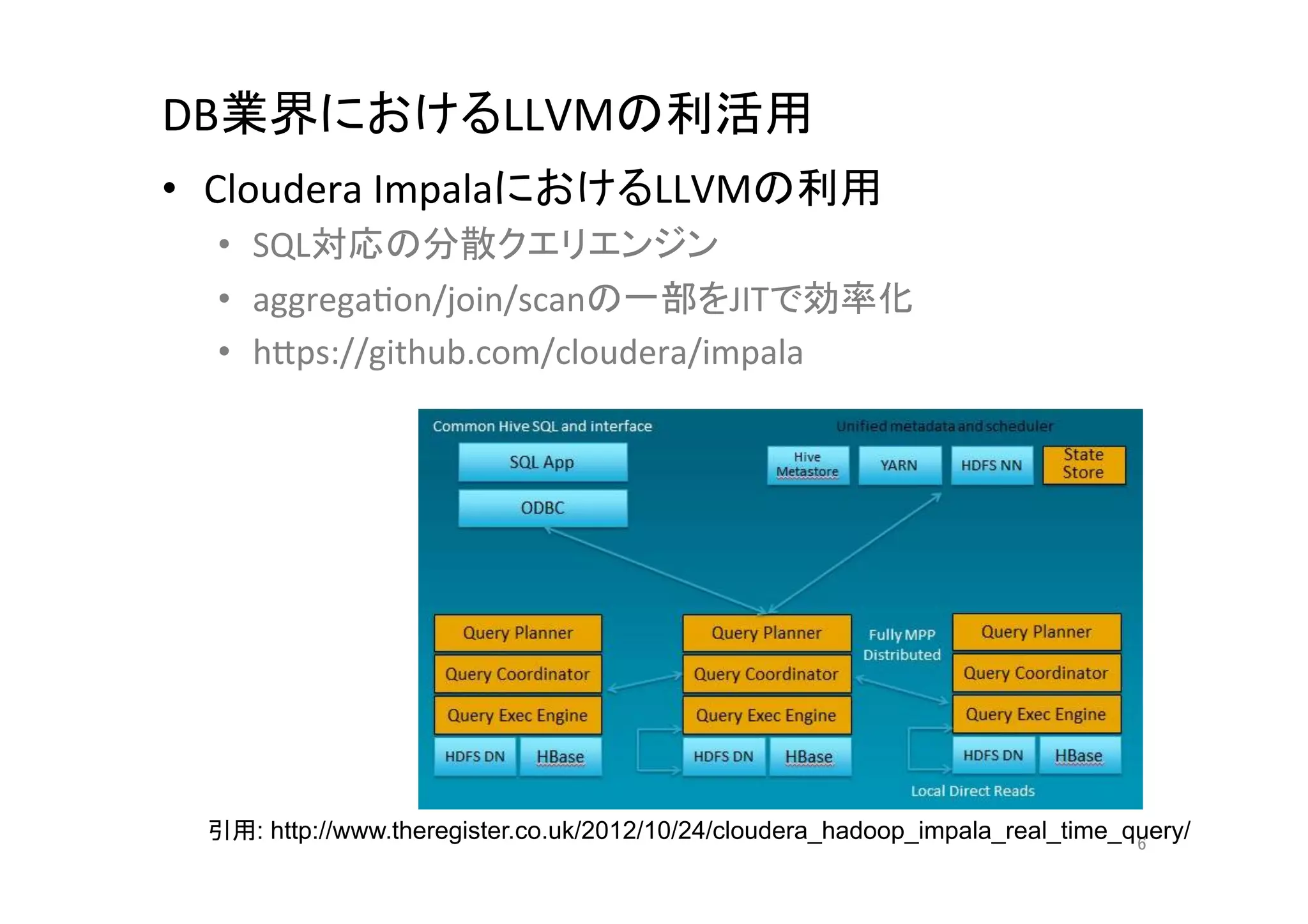
Intro to SVE 富岳のA64FXを触ってみた
PDF
組み込み関数(intrinsic)によるSIMD入門
PDF
PDF
PDF
PDF
いまさら聞けないarmを使ったNEONの基礎と活用事例
PDF
PDF
PPTX
CPU / GPU高速化セミナー!性能モデルの理論と実践:理論編
PDF
PPTX
PDF
PDF
ARM CPUにおけるSIMDを用いた高速計算入門
PDF
PDF
PPTX
PDF
AVX2時代の正規表現マッチング 〜半群でぐんぐん!〜
PDF
PDF
PDF
PDF
PDF
CUDAのアセンブリ言語基礎のまとめ PTXとSASSの概説
PDF
20230105_TITECH_lecture_ishizaki_public.pdf
PDF
プログラミングコンテストでのデータ構造 2 ~平衡二分探索木編~
PDF
PDF
C# ゲームプログラミングはホントにメモリのことに無頓着でいいの?
PDF
PDF
PDF
PDF
More Related Content
PDF
Intro to SVE 富岳のA64FXを触ってみた
PDF
組み込み関数(intrinsic)によるSIMD入門
PDF
PDF
PDF
PDF
いまさら聞けないarmを使ったNEONの基礎と活用事例
PDF
PDF
What's hot
PPTX
CPU / GPU高速化セミナー!性能モデルの理論と実践:理論編
PDF
PPTX
PDF
PDF
ARM CPUにおけるSIMDを用いた高速計算入門
PDF
PDF
PPTX
PDF
AVX2時代の正規表現マッチング 〜半群でぐんぐん!〜
PDF
PDF
PDF
PDF
PDF
CUDAのアセンブリ言語基礎のまとめ PTXとSASSの概説
PDF
20230105_TITECH_lecture_ishizaki_public.pdf
PDF
プログラミングコンテストでのデータ構造 2 ~平衡二分探索木編~
PDF
PDF
C# ゲームプログラミングはホントにメモリのことに無頓着でいいの?
PDF
PDF
Similar to LLVMで遊ぶ(整数圧縮とか、x86向けの自動ベクトル化とか)
PDF
PDF
PDF
PDF
PDF
PDF
PDF
PDF
PPTX
PDF
PDF
x64 のスカラー,SIMD 演算性能を測ってみた @ C++ MIX #10
PDF
PDF
x64 のスカラー,SIMD 演算性能を測ってみた v0.1 @ C++ MIX #10
PDF
Javaセキュアコーディングセミナー東京第2回講義
PDF
PDF
PDF
“Symbolic bounds analysis of pointers, array indices, and accessed memory reg...
PDF
Precise garbage collection for c
PDF
PDF
More from Takeshi Yamamuro
PDF
浮動小数点(IEEE754)を圧縮したい@dsirnlp#4
PDF
PDF
An Experimental Study of Bitmap Compression vs. Inverted List Compression
PDF
MLflowによる機械学習モデルのライフサイクルの管理
PDF
PDF
PDF
PDF
Introduction to Modern Analytical DB
PPTX
LLJVM: LLVM bitcode to JVM bytecode
PDF
PDF
PDF
20180417 hivemall meetup#4
PDF
Taming Distributed/Parallel Query Execution Engine of Apache Spark
PPT
Quick Overview of Upcoming Spark 3.0 + α
PDF
VLDB2013 R1 Emerging Hardware
PDF
PDF
A x86-optimized rank&select dictionary for bit sequences
PDF
PDF
LT: Spark 3.1 Feature Expectation
PDF
LLVMで遊ぶ(整数圧縮とか、x86向けの自動ベクトル化とか) 1. 2. clang
LLVMで遊ぶ
整数圧縮とか、x86向け自動ベクトル化とか
2013/3/30
maropu@x86/64最適化勉強会5
2
3. 本日の概要
• なんでお前clang(LLVM)の話してんの?
– RDBMS関連の話題で最近良く扱われるため勉強中
– 今書いている整数圧縮のコードをより高速化したい
• 整数圧縮ライブラリ:
vpacker
– hCps://github.com/maropu/vpacker
• clangのx86向け自動ベクトル化
– SIMDを使用した命令列への自動変換
3
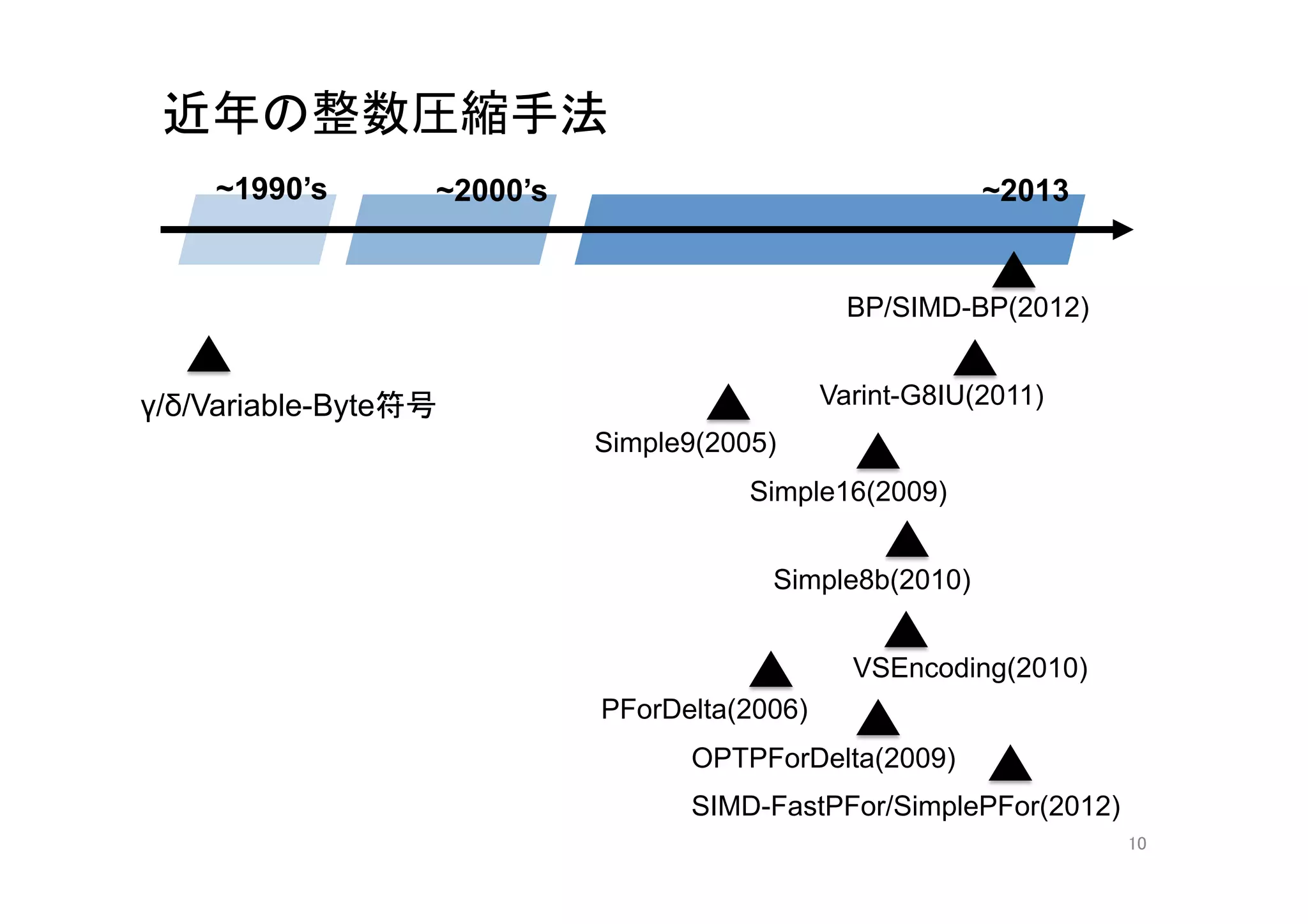
4. 5. 6. 7. 8. 9. 10. 近年の整数圧縮手法
~1990’s
~2000’s
~2013
BP/SIMD-BP(2012)
γ/δ/Variable-Byte符号
Varint-G8IU(2011)
Simple9(2005)
Simple16(2009)
Simple8b(2010)
VSEncoding(2010)
PForDelta(2006)
OPTPForDelta(2009)
SIMD-FastPFor/SimplePFor(2012)
10
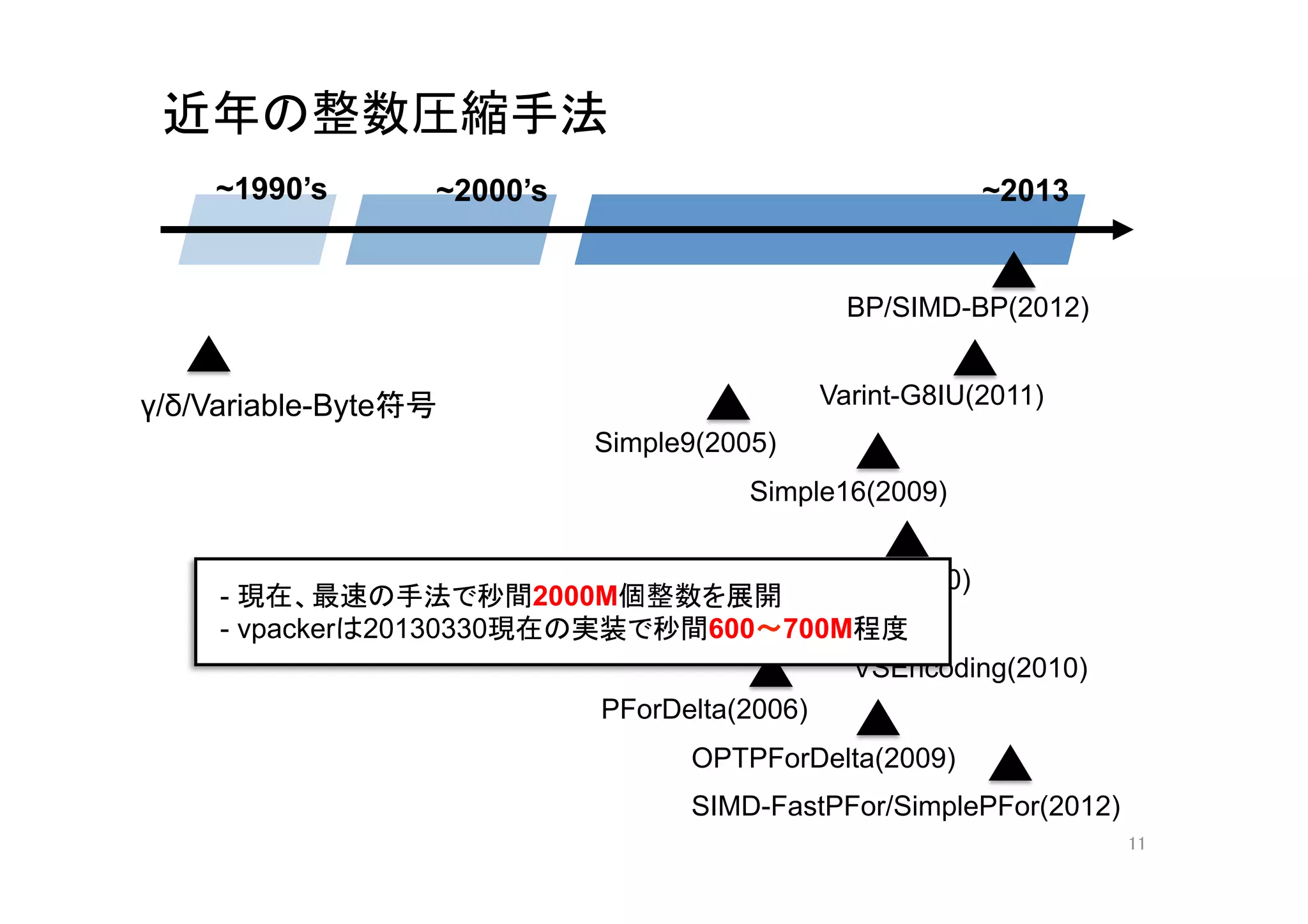
11. 近年の整数圧縮手法
~1990’s
~2000’s
~2013
BP/SIMD-BP(2012)
γ/δ/Variable-Byte符号
Varint-G8IU(2011)
Simple9(2005)
Simple16(2009)
Simple8b(2010)
- 現在、最速の手法で秒間2000M個整数を展開
- vpackerは20130330現在の実装で秒間600〜700M程度
VSEncoding(2010)
PForDelta(2006)
OPTPForDelta(2009)
SIMD-FastPFor/SimplePFor(2012)
11
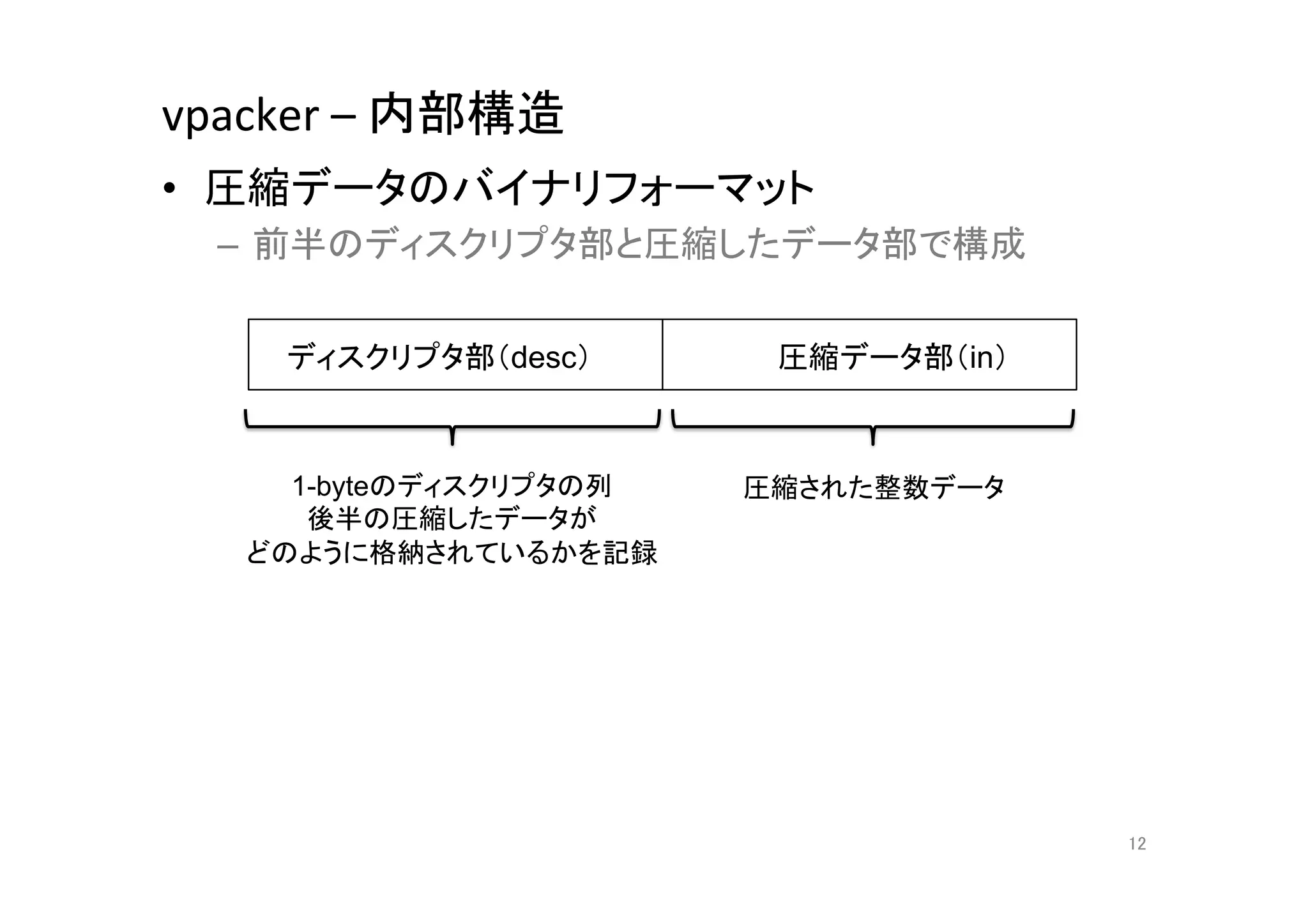
12. vpacker
–
内部構造
• 圧縮データのバイナリフォーマット
– 前半のディスクリプタ部と圧縮したデータ部で構成
ディスクリプタ部(desc)
圧縮データ部(in)
1-byteのディスクリプタの列 圧縮された整数データ
後半の圧縮したデータが
どのように格納されているかを記録
12
13. vpacker
–
内部構造
• 圧縮データのバイナリフォーマット
ディスクリプタ部(desc)
圧縮データ部(in)
1-byteのデータに固定長1-bitで8個の整数が格納
void unpack1_8(const char *in, uint32_t *out) {
*out++ = in[0] & 0x01;
*out++ = (in[0] >> 1) & 0x01;
*out++ = (in[0] >> 2) & 0x01;
...
*out++ = (in[0] >> 7) & 0x01;
}
13
14. vpacker
–
内部構造
• 圧縮データのバイナリフォーマット
2-byteのデータに固定長2-bitで8個の整数が格納
ディスクリプタ部(desc)
圧縮データ部(in)
1-byteのデータに固定長1-bitで8個の整数が格納
void unpack2_8(const char *in, uint32_t *out) {
*out++ = in[0] & 0x03;
*out++ = (in[0] >> 2) & 0x03;
*out++ = (in[0] >> 4) & 0x03;
...
*out++ = (in[1] >> 6) & 0x03;
}
14
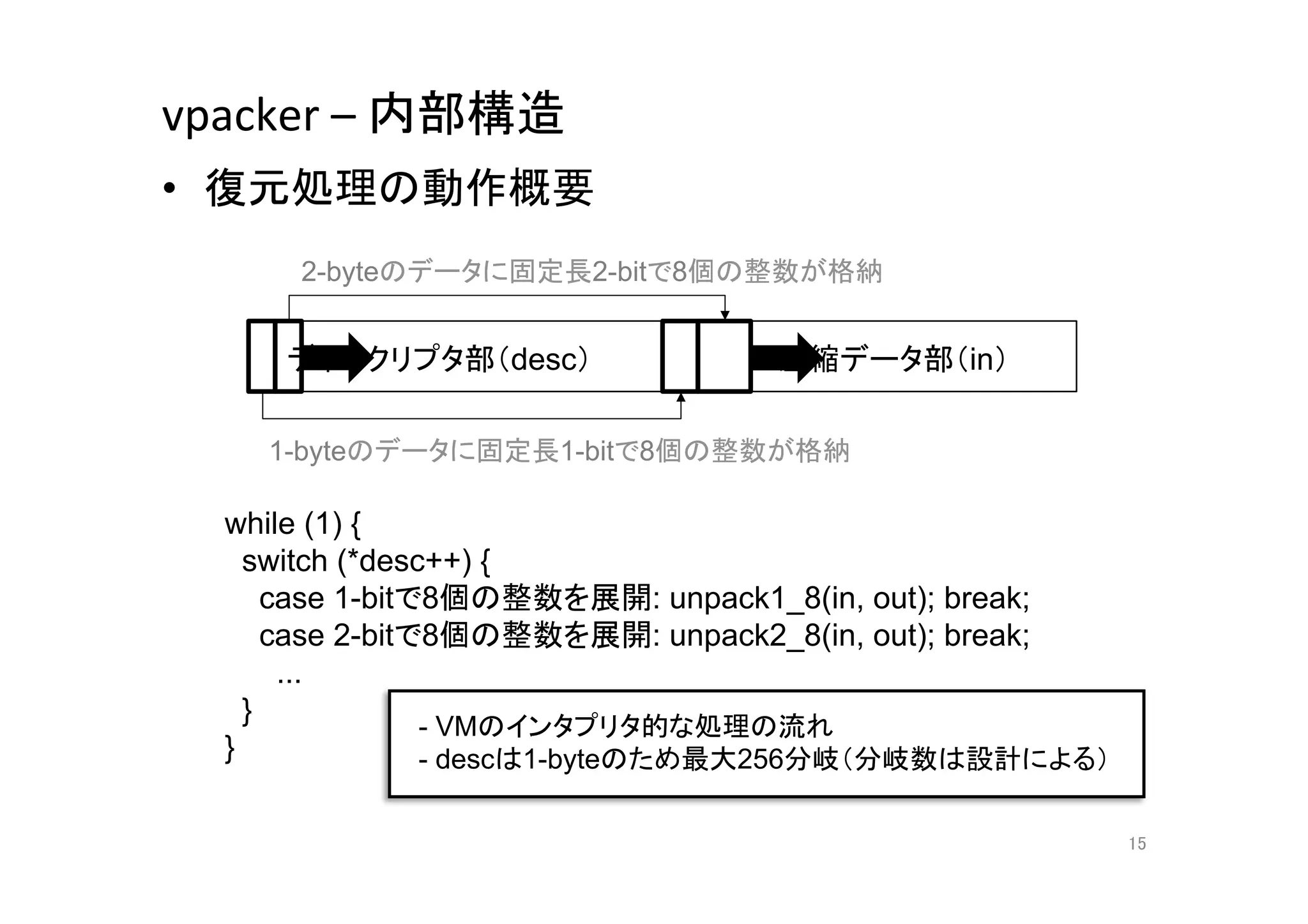
15. vpacker
–
内部構造
• 復元処理の動作概要
2-byteのデータに固定長2-bitで8個の整数が格納
ディスクリプタ部(desc)
圧縮データ部(in)
1-byteのデータに固定長1-bitで8個の整数が格納
while (1) {
switch (*desc++) {
case 1-bitで8個の整数を展開: unpack1_8(in, out); break;
case 2-bitで8個の整数を展開: unpack2_8(in, out); break;
...
}
- VMのインタプリタ的な処理の流れ
}
- descは1-byteのため最大256分岐(分岐数は設計による)
15
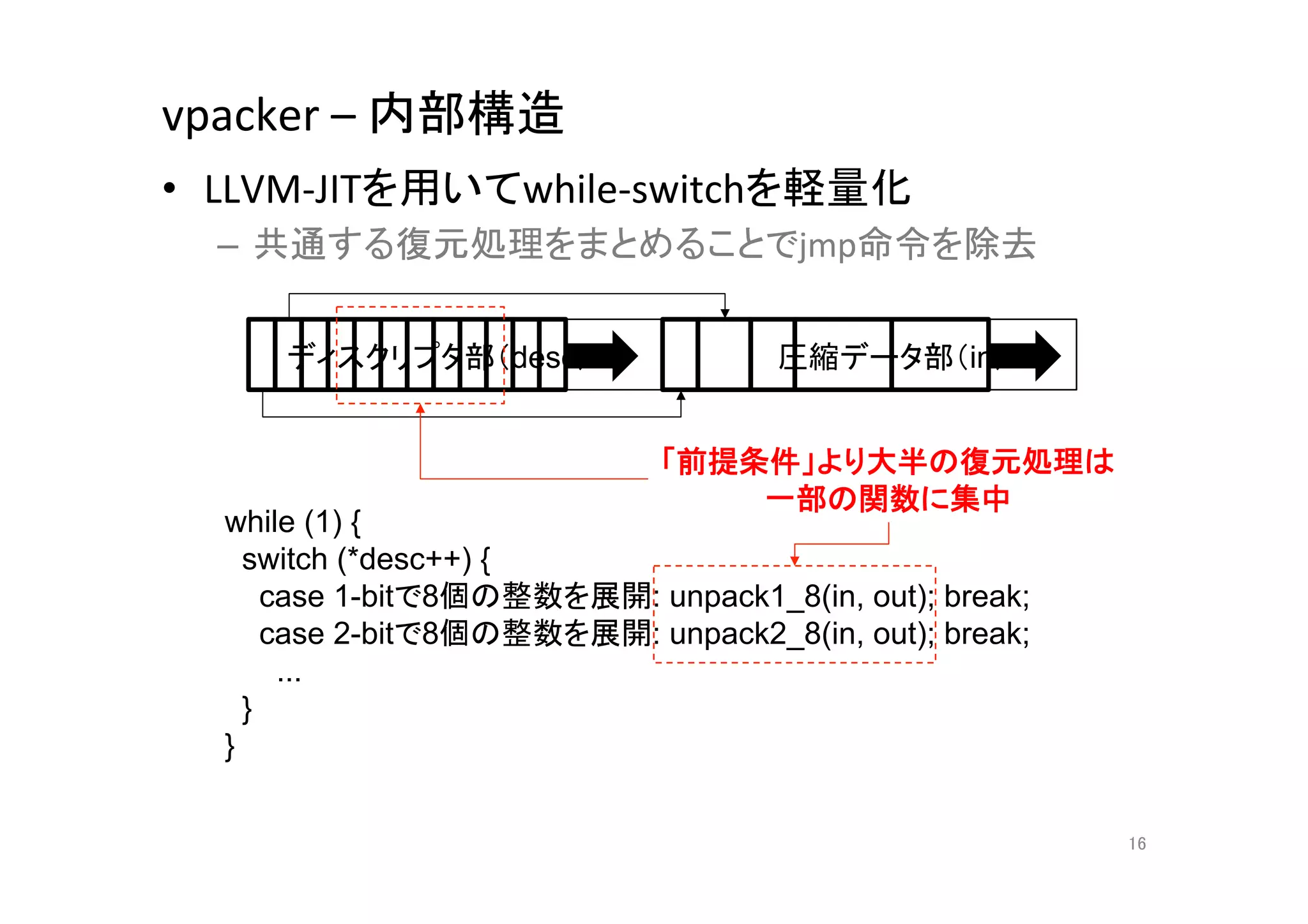
16. vpacker
–
内部構造
• LLVM-‐JITを用いてwhile-‐switchを軽量化
– 共通する復元処理をまとめることでjmp命令を除去
ディスクリプタ部(desc)
圧縮データ部(in)
「前提条件」より大半の復元処理は
一部の関数に集中
while (1) {
switch (*desc++) {
case 1-bitで8個の整数を展開: unpack1_8(in, out); break;
case 2-bitで8個の整数を展開: unpack2_8(in, out); break;
...
}
}
16
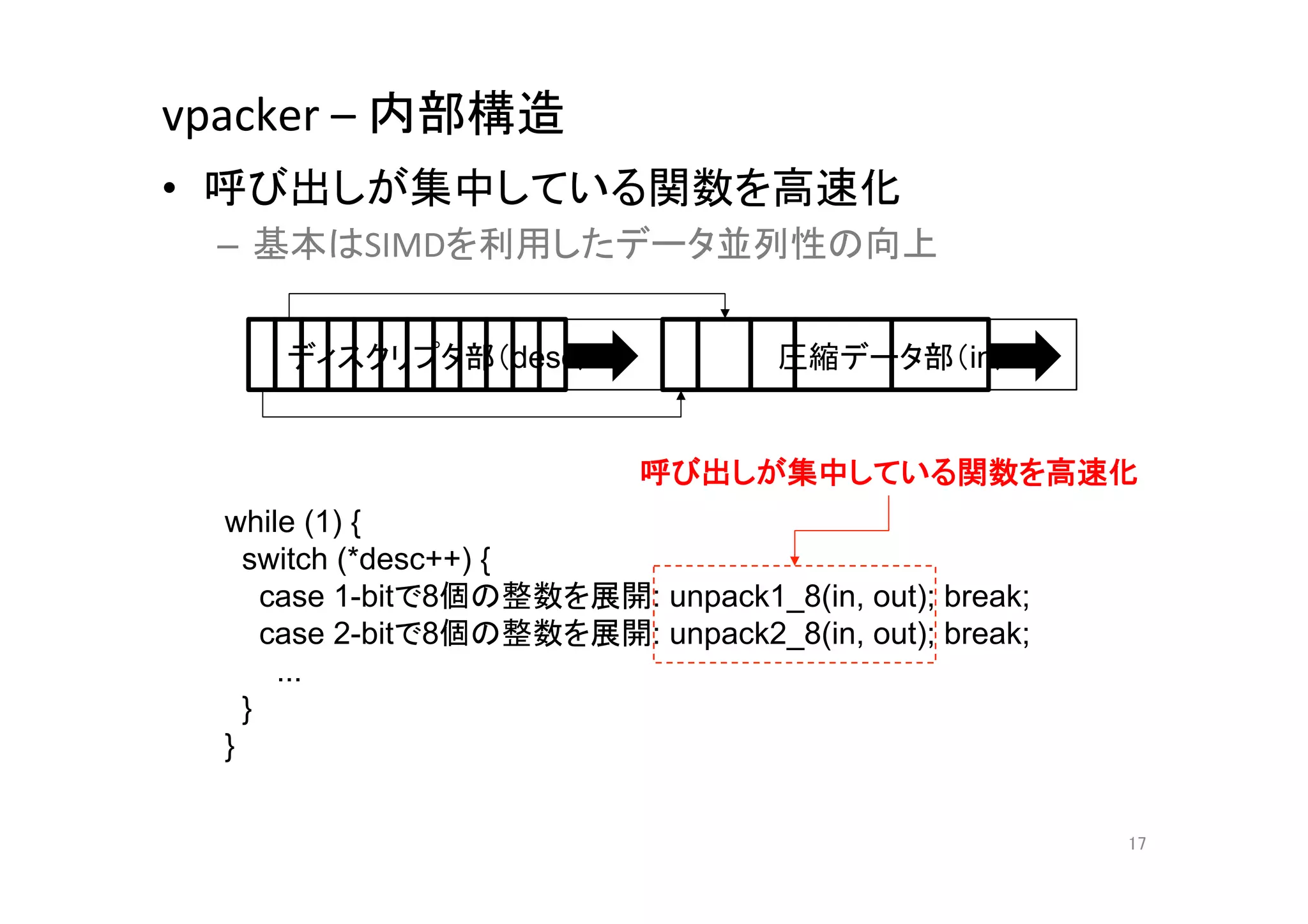
17. vpacker
–
内部構造
• 呼び出しが集中している関数を高速化
– 基本はSIMDを利用したデータ並列性の向上
ディスクリプタ部(desc)
圧縮データ部(in)
呼び出しが集中している関数を高速化
while (1) {
switch (*desc++) {
case 1-bitで8個の整数を展開: unpack1_8(in, out); break;
case 2-bitで8個の整数を展開: unpack2_8(in, out); break;
...
}
}
17
18. gcc(v4.8)の自動ベクトル化
• この関数*1ってどんな機械語に変換されるの?
– 処理に依存関係が無く,ベクトル化しやすそうな印象
void unpack1(const char *in, uint32_t *out, int n) {
for (int i = 0; i < n; i++) {
*out++ = in[0] & 0x01;
*out++ = (in[0] >> 1) & 0x01;
*out++ = (in[0] >> 2) & 0x01;
...
*out++ = (in[0] >> 7) & 0x01;
}
}
*1 現実に即して,ループ回数(n)を指定できるように変更しました
18
19. gcc(v4.8)の自動ベクトル化
• この関数ってどんな機械語に変換されるの?
– 処理に依存関係が無く,ベクトル化しやすそうな印象
void unpack1(const char *in, uint32_t *out, int n) {
for (int i = 0; i < n; i++) {
*out++ = in[0] & 0x01;
*out++ = (in[0] >> 1) & 0x01;
*out++ = (in[0] >> 2) & 0x01;
...
*out++ = (in[0] >> 7) & 0x01;
}
}
重要) コンパイルする前に自動ベクトル化されやすいように前処理
19
20. gcc(v4.8)の自動ベクトル化
• この関数ってどんな機械語に変換されるの?
– 処理に依存関係が無く,ベクトル化しやすそうな印象
void unpack1(const char *in, uint32_t *out, int n) {
for (int i = 0; i < n; i++) {
for (int j = 0; j < 8; j++)
*out++ = (*in >> j) & 0x01;
in++;
}
}
gccの場合、SLP(Superword-Level Parallelism)による最適化より
Loop Vectorizerに任せたほうが良いらしいです
20
21. gcc(v4.8)の自動ベクトル化
• この関数ってどんな機械語に変換されるの?
– 処理に依存関係が無く,ベクトル化しやすそうな印象
void unpack1(const char * __restrict__ in,
uint32_t * __restrict__ out, int n) {
for (int i = 0; i < n; i++) {
for (int j = 0; j < 8; j++)
*out++ = (*in >> j) & 0x01;
in++;
}
}
__restrict__を付与してin/outを呼び出し側で16Bにアライメント
21
22. gcc(v4.8)の自動ベクトル化
• 一部だけ抜粋
&
並び替え(’gcc
-‐O3’)
movdqu (%r9), %xmm1 // in - %xmm1
pxor %xmm2, %xmm2
pcmpgtb %xmm1, %xmm2
movdqa %xmm1, %xmm3
punpckhbw %xmm2, %xmm1
punpcklbw %xmm2, %xmm3
pxor %xmm2, %xmm2
movdqa %xmm3, %xmm4
pcmpgtw %xmm3, %xmm2
punpcklwd %xmm2, %xmm4
movdqa %xmm4, %xmm5
pand %xmm0, %xmm5 // %xmm1=[0x01, 0x01, 0x01, 0x01]
....
22
23. gcc(v4.8)の自動ベクトル化
• 一部だけ抜粋
並び替え(’gcc
-‐O3’)
movdqu (%r9), %xmm1 // in - %xmm1
pxor %xmm2, %xmm2
pcmpgtb %xmm1, %xmm2
movdqa %xmm1, %xmm3
punpckhbw %xmm2, %xmm1
punpcklbw %xmm2, %xmm3 バイトからワードに符号拡張
pxor %xmm2, %xmm2
movdqa %xmm3, %xmm4
pcmpgtw %xmm3, %xmm2
punpcklwd %xmm2, %xmm4 ワードからダブルワードに符号拡張
movdqa %xmm4, %xmm5
pand %xmm0, %xmm5 // %xmm1=[0x01, 0x01, 0x01, 0x01]
....
0x01でマスクして展開処理完了
23
24. gcc(v4.8)の自動ベクトル化
• 一部だけ抜粋
並び替え(’gcc
-‐O3’)
movdqu (%r9), %xmm1 // in - %xmm1
pxor %xmm2, %xmm2
pcmpgtb %xmm1, %xmm2
movdqa %xmm1, %xmm3
punpckhbw %xmm2, %xmm1
punpcklbw %xmm2, %xmm3 バイトからワードに符号拡張
pxor %xmm2, %xmm2
movdqa %xmm3, %xmm4
pcmpgtw %xmm3, %xmm2
punpcklwd %xmm2, %xmm4 ワードからダブルワードに符号拡張
‘n 15’で分岐させてLoopを全てinline化するアグレッシブな最適化
movdqa %xmm4, %xmm5
→’n = 15’はベクトル化されていないパスに分岐
pand %xmm0, %xmm5 // %xmm1=[0x01, 0x01, 0x01, 0x01]
....
0x01でマスクして展開処理完了
24
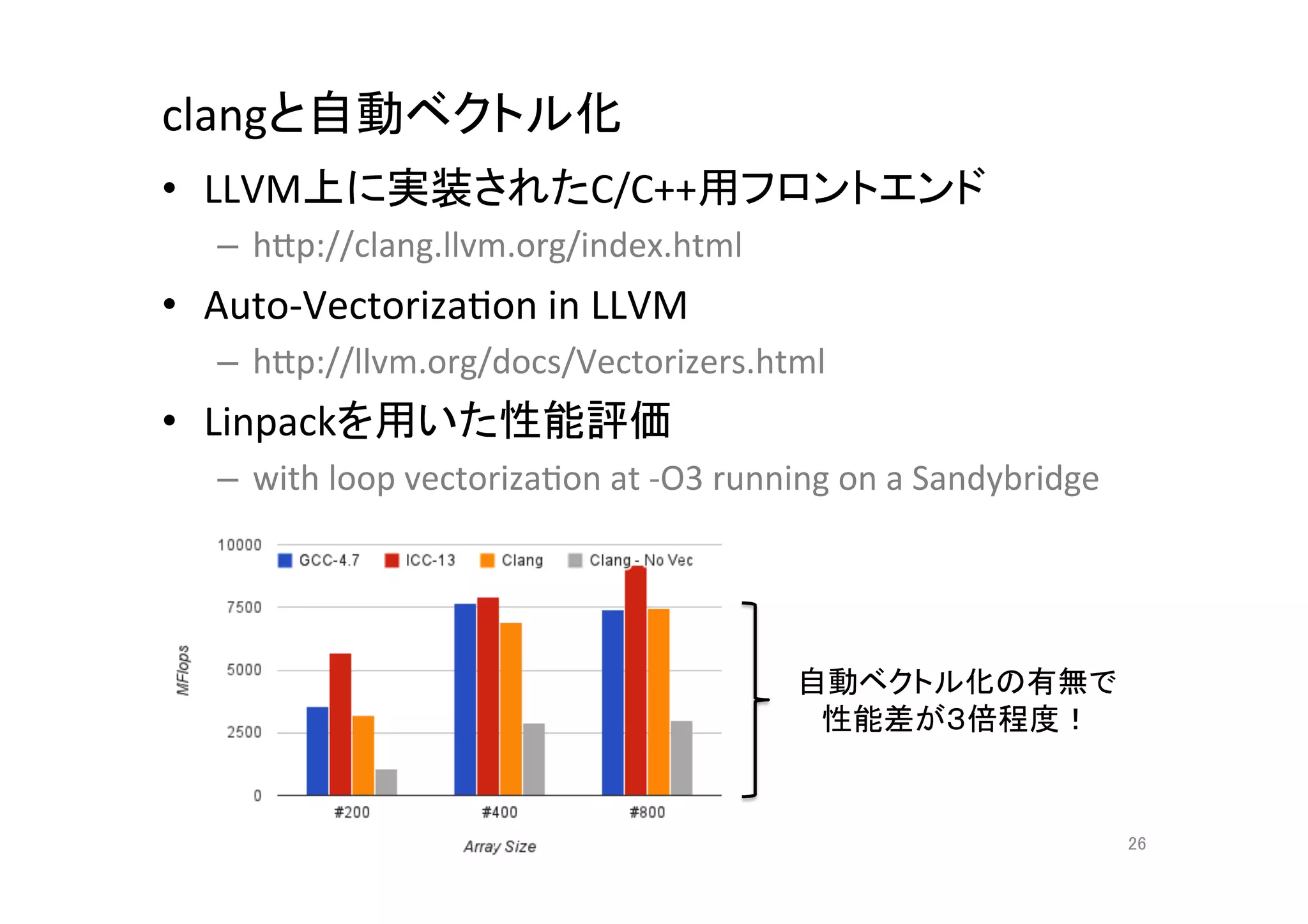
25. 26. clangと自動ベクトル化
• LLVM上に実装されたC/C++用フロントエンド
– hCp://clang.llvm.org/index.html
• Auto-‐VectorizaQon
in
LLVM
– hCp://llvm.org/docs/Vectorizers.html
• Linpackを用いた性能評価
– with
loop
vectorizaQon
at
-‐O3
running
on
a
Sandybridge
自動ベクトル化の有無で
性能差が3倍程度!
26
27. clangにおける2種類のVectorizer
• Basic-‐Block(BB)
Vectorizer
–
SLP
in
gcc
– v3.1で”
-‐mllvm
–vectorize”として導入
– 最適化の対象が「Basic
Block」
– 歴史的に実装されたのはコチラが先
• Loop
Vectorizer
– v3.2でようやく”
-‐mllvm
–vectorize-‐loops”として導入
– 「Unroll+BB
Vectorizer」にLoop間依存解析を加えたもの
– 自動ベクトル化の制約(v3.2のReleaseNotesより)
• Loop枚のカウントは”1”のみ
• InducQon変数は一番内側のLoopのみ使用可能
27
28. clangの自動ベクトル化パラメータ
• clang-‐v3.2を利用(2013/3/30現在最新)
– デフォルトで自動ベクトル化は全てOFF
– v3.3からLoop
Vectorizerはデフォルトに
• -‐mllvm
–vectorize,
-‐mllvm
–vectorize-‐loops
– -‐O2/-‐O3との併用が必要
– -‐Osはコード増加が発生しない場合に適用
• -‐mllvm
–bb-‐vectorize-‐aligned-‐only
– アラインされたstore/loadのみを最適化に使用
• -‐mllvm
–force-‐vector-‐width=X
– 最適化で使用するベクトル要素数をXで指定
28
29. その他の補助パラメータ
• -‐mllvm
–unroll-‐allow-‐parQal
– Loop内の部分的なUnrollを可能に
• -‐mllvm
–unroll-‐runQme
– 実行時にLoopを数えてUnroll可能に
• -‐funsafe-‐math-‐opQmizaQons,
-‐ffast-‐math
– 浮動小数点演算にIEEE/ISO仕様外の最適化を適用
• 他の関連するパラメータは以下の資料が詳しい
– Auto-‐vectorizaQon
with
LLVM
– hCp://llvm.org/devmtg/2012-‐04-‐12/Slides/Hal_Finkel.pdf
29
30. WriQng
Vectorizer-‐Friendly
Code
in
clang
• example.1#
– clang
-‐O3
-‐mllvm
-‐vectorize-‐loops
void test1(float * __restrict__ a,
float * __restrict__ b, int n) {
for (int i = 0; i n; i++)
a[i] += b[i];
}
30
31. WriQng
Vectorizer-‐Friendly
Code
in
clang
• example.1#
– clang
-‐O3
-‐mllvm
-‐vectorize-‐loops
%rdiと%rsiは16Bに揃えてあるのに
.LBB0_2: なぜかmovapsに変換されない?
movups 16(%rdi,%rax,4), %xmm1
movups 16(%rsi,%rax,4), %xmm0
addps %xmm1, %xmm0
movups (%rdi,%rax,4), %xmm1
movups (%rsi,%rax,4), %xmm2
movups %xmm0, 16(%rdi,%rax,4)
addps %xmm1, %xmm2
movups %xmm2, (%rdi,%rax,4)
addq $8, %rax
cmpq %rax, %rcx
jne .LBB0_2
31
32. WriQng
Vectorizer-‐Friendly
Code
in
clang
• example.2#
– clang
-‐O3
-‐mllvm
-‐vectorize-‐loops
void test2(float * __restrict__ a,
float * __restrict__ b, int n) {
for (int i = 0; i n; i += 2)
a[i] += b[i];
}
32
33. WriQng
Vectorizer-‐Friendly
Code
in
clang
• example.2#
– clang
-‐O3
-‐mllvm
-‐vectorize-‐loops
.LBB0_2:
movss (%rsi,%rax,4), %xmm0
addss (%rdi,%rax,4), %xmm0
movss %xmm0, (%rdi,%rax,4)
addq $2, %rax
cmpl %edx, %eax
jl .LBB0_2
33
34. WriQng
Vectorizer-‐Friendly
Code
in
clang
• example.3#
– clang
-‐O3
-‐mllvm
-‐vectorize-‐loops
void test3(float * __restrict__ a,
float * __restrict__ b, int n) {
for (int i = 0; i n; i += 1) {
for (int j = 0; j SIZE; j++)
a[i * SIZE + j] += b[i * SIZE + j];
}
}
34
35. WriQng
Vectorizer-‐Friendly
Code
in
clang
• example.3#
– clang
-‐O3
-‐mllvm
-‐vectorize-‐loops
.LBB1_22: # = The Inner Loop
movups (%rbx), %xmm2
movups 16(%rbx), %xmm1
movups (%rax), %xmm0
movups 16(%rax), %xmm3
addps %xmm2, %xmm0
addps %xmm1, %xmm3
movups %xmm3, 16(%rbx)
movups %xmm0, (%rbx)
addq $32, %rbx
addq $32, %rax
addq $-8, %rdi
jne .LBB1_22
35
36. WriQng
Vectorizer-‐Friendly
Code
in
clang
• example.4#
– clang
-‐O3
-‐mllvm
-‐vectorize-‐loops
float test4(float * __restrict__ a, int n) {
float S = 0.0;
for (int i = 0; i n; i += 1)
S += a[i];
return S;
}
36
37. WriQng
Vectorizer-‐Friendly
Code
in
clang
• example.4#
– clang
-‐O3
-‐mllvm
-‐vectorize-‐loops
.LBB0_1:
addss (%rdi), %xmm0
addq $4, %rdi
decl %esi
jne .LBB0_1
浮動小数点演算は結合則が成り立たないため、こういう命令列に
→clangにも’-ffast-math’があるが、出力する命令は同じだった
37
38. WriQng
Vectorizer-‐Friendly
Code
in
clang
• example.4#
– gcc
-‐O3
-‐ffast-‐math
.L33:
addps (%rax), %xmm0
addq $16, %rax
cmpq %rdx, %rax
jne .L33
movaps %xmm0, %xmm1
movhlps %xmm0, %xmm1
addps %xmm0, %xmm1
movaps %xmm1, %xmm0
shufps $85, %xmm1, %xmm0
addps %xmm1, %xmm0
unpcklps %xmm0, %xmm0
38
39. WriQng
Vectorizer-‐Friendly
Code
in
clang
• example.4#
– gcc
-‐O3
-‐ffast-‐math
ベクトル加算して
.L33:
addps (%rax), %xmm0
addq $16, %rax
cmpq %rdx, %rax
jne .L33 水平加算
movaps %xmm0, %xmm1
movhlps %xmm0, %xmm1
addps %xmm0, %xmm1
movaps %xmm1, %xmm0
shufps $85, %xmm1, %xmm0
addps %xmm1, %xmm0
unpcklps %xmm0, %xmm0
39
40. 41. clangが出力する「unpack1」
• 一部だけ抜粋(’
clang
-‐S
-‐O3
-‐mllvm
-‐vectorize’)
movsbl (%rdi), %eax # *in - %eax
movd %eax, %xmm0
pshufd $0, %xmm0, %xmm4
pshufd $68, %xmm4, %xmm3
pand %xmm8, %xmm4
movl %eax, %ecx
...
shrq $2, %r10
movd %r10, %xmm0
punpcklqdq %xmm7, %xmm0
pand 人類には早すぎる難解なアセンブリが出力された・・・
%xmm1, %xmm0
pshufd →nの値でunrollはしないgccに比べてコンサバな最適化
$-128, %xmm0, %xmm7
movss %xmm6, %xmm7
movlhps %xmm7, %xmm5
shufps $-30, %xmm7, %xmm5
movups %xmm5, (%rsi) # %xmm5 - dst
41
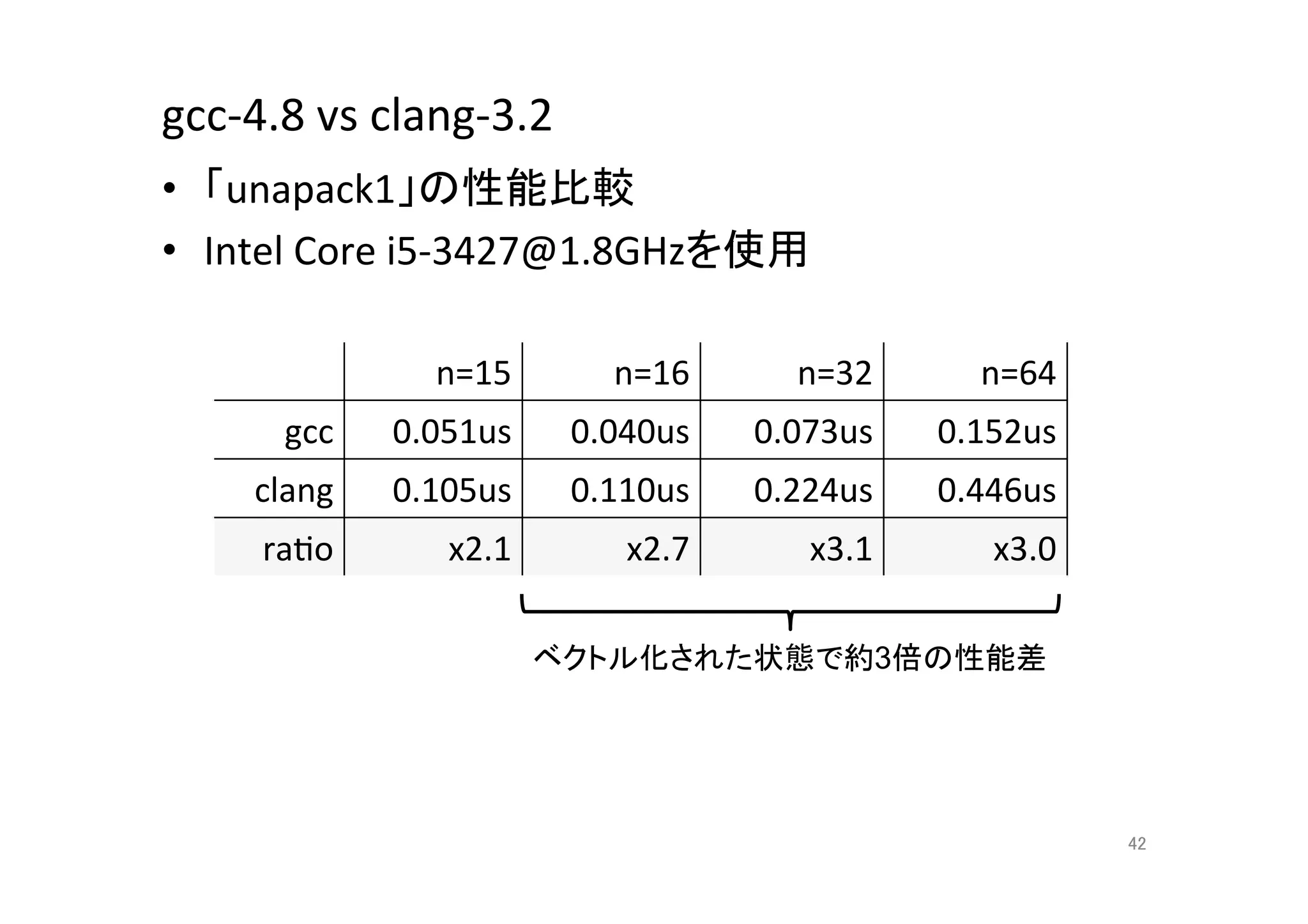
42. gcc-‐4.8
vs
clang-‐3.2
• 「unapack1」の性能比較
• Intel
Core
i5-‐3427@1.8GHzを使用
n=15
n=16
n=32
n=64
gcc
0.051us
0.040us
0.073us
0.152us
clang
0.105us
0.110us
0.224us
0.446us
raQo
x2.1
x2.7
x3.1
x3.0
ベクトル化された状態で約3倍の性能差
42
43. 44. 本日のまとめ
• clang-‐v3.2の自動ベクトル化の性能調査
– 基本的なものは自動的にベクトル化される
– 処理が複雑になるとgccに対して2~3倍程度の性能差も
• ‘Vectorizer-‐Friendly’はまだまだ重要
– 完全にコンパイラ任せ,というわけには現在いかない
– 256-‐bit,
512-‐bit,
...とベクトル長が増えると性能差は拡大
44
45. 本日のまとめ
• 自動ベクトル化のためのコード規約
1.
ポインタのエイリアスは避ける
・必要な個所では__restrict__を付ける
2.
ベクトル長の境界に合わせる
・__builQn_assume_aligned(X),
__aCribute__((aligned(X))の活用
3.
Loop内の手作業のinline化は避ける
・Loop
Vectorizerに任せたほうが賢い
45









![vpacker
–
内部構造
• 圧縮データのバイナリフォーマット
ディスクリプタ部(desc)
圧縮データ部(in)
1-byteのデータに固定長1-bitで8個の整数が格納
void unpack1_8(const char *in, uint32_t *out) {
*out++ = in[0] & 0x01;
*out++ = (in[0] >> 1) & 0x01;
*out++ = (in[0] >> 2) & 0x01;
...
*out++ = (in[0] >> 7) & 0x01;
}
13](https://image.slidesharecdn.com/20130330x86-study-130329232150-phpapp01/75/LLVM-x86-13-2048.jpg)
![vpacker
–
内部構造
• 圧縮データのバイナリフォーマット
2-byteのデータに固定長2-bitで8個の整数が格納
ディスクリプタ部(desc)
圧縮データ部(in)
1-byteのデータに固定長1-bitで8個の整数が格納
void unpack2_8(const char *in, uint32_t *out) {
*out++ = in[0] & 0x03;
*out++ = (in[0] >> 2) & 0x03;
*out++ = (in[0] >> 4) & 0x03;
...
*out++ = (in[1] >> 6) & 0x03;
}
14](https://image.slidesharecdn.com/20130330x86-study-130329232150-phpapp01/75/LLVM-x86-14-2048.jpg)
![gcc(v4.8)の自動ベクトル化
• この関数*1ってどんな機械語に変換されるの?
– 処理に依存関係が無く,ベクトル化しやすそうな印象
void unpack1(const char *in, uint32_t *out, int n) {
for (int i = 0; i < n; i++) {
*out++ = in[0] & 0x01;
*out++ = (in[0] >> 1) & 0x01;
*out++ = (in[0] >> 2) & 0x01;
...
*out++ = (in[0] >> 7) & 0x01;
}
}
*1 現実に即して,ループ回数(n)を指定できるように変更しました
18](https://image.slidesharecdn.com/20130330x86-study-130329232150-phpapp01/75/LLVM-x86-18-2048.jpg)
![gcc(v4.8)の自動ベクトル化
• この関数ってどんな機械語に変換されるの?
– 処理に依存関係が無く,ベクトル化しやすそうな印象
void unpack1(const char *in, uint32_t *out, int n) {
for (int i = 0; i < n; i++) {
*out++ = in[0] & 0x01;
*out++ = (in[0] >> 1) & 0x01;
*out++ = (in[0] >> 2) & 0x01;
...
*out++ = (in[0] >> 7) & 0x01;
}
}
重要) コンパイルする前に自動ベクトル化されやすいように前処理
19](https://image.slidesharecdn.com/20130330x86-study-130329232150-phpapp01/75/LLVM-x86-19-2048.jpg)


![gcc(v4.8)の自動ベクトル化
• 一部だけ抜粋
&
並び替え(’gcc
-‐O3’)
movdqu (%r9), %xmm1 // in - %xmm1
pxor %xmm2, %xmm2
pcmpgtb %xmm1, %xmm2
movdqa %xmm1, %xmm3
punpckhbw %xmm2, %xmm1
punpcklbw %xmm2, %xmm3
pxor %xmm2, %xmm2
movdqa %xmm3, %xmm4
pcmpgtw %xmm3, %xmm2
punpcklwd %xmm2, %xmm4
movdqa %xmm4, %xmm5
pand %xmm0, %xmm5 // %xmm1=[0x01, 0x01, 0x01, 0x01]
....
22](https://image.slidesharecdn.com/20130330x86-study-130329232150-phpapp01/75/LLVM-x86-22-2048.jpg)
![gcc(v4.8)の自動ベクトル化
• 一部だけ抜粋
並び替え(’gcc
-‐O3’)
movdqu (%r9), %xmm1 // in - %xmm1
pxor %xmm2, %xmm2
pcmpgtb %xmm1, %xmm2
movdqa %xmm1, %xmm3
punpckhbw %xmm2, %xmm1
punpcklbw %xmm2, %xmm3 バイトからワードに符号拡張
pxor %xmm2, %xmm2
movdqa %xmm3, %xmm4
pcmpgtw %xmm3, %xmm2
punpcklwd %xmm2, %xmm4 ワードからダブルワードに符号拡張
movdqa %xmm4, %xmm5
pand %xmm0, %xmm5 // %xmm1=[0x01, 0x01, 0x01, 0x01]
....
0x01でマスクして展開処理完了
23](https://image.slidesharecdn.com/20130330x86-study-130329232150-phpapp01/75/LLVM-x86-23-2048.jpg)
![gcc(v4.8)の自動ベクトル化
• 一部だけ抜粋
並び替え(’gcc
-‐O3’)
movdqu (%r9), %xmm1 // in - %xmm1
pxor %xmm2, %xmm2
pcmpgtb %xmm1, %xmm2
movdqa %xmm1, %xmm3
punpckhbw %xmm2, %xmm1
punpcklbw %xmm2, %xmm3 バイトからワードに符号拡張
pxor %xmm2, %xmm2
movdqa %xmm3, %xmm4
pcmpgtw %xmm3, %xmm2
punpcklwd %xmm2, %xmm4 ワードからダブルワードに符号拡張
‘n 15’で分岐させてLoopを全てinline化するアグレッシブな最適化
movdqa %xmm4, %xmm5
→’n = 15’はベクトル化されていないパスに分岐
pand %xmm0, %xmm5 // %xmm1=[0x01, 0x01, 0x01, 0x01]
....
0x01でマスクして展開処理完了
24](https://image.slidesharecdn.com/20130330x86-study-130329232150-phpapp01/75/LLVM-x86-24-2048.jpg)




![WriQng
Vectorizer-‐Friendly
Code
in
clang
• example.1#
– clang
-‐O3
-‐mllvm
-‐vectorize-‐loops
void test1(float * __restrict__ a,
float * __restrict__ b, int n) {
for (int i = 0; i n; i++)
a[i] += b[i];
}
30](https://image.slidesharecdn.com/20130330x86-study-130329232150-phpapp01/75/LLVM-x86-30-2048.jpg)

![WriQng
Vectorizer-‐Friendly
Code
in
clang
• example.2#
– clang
-‐O3
-‐mllvm
-‐vectorize-‐loops
void test2(float * __restrict__ a,
float * __restrict__ b, int n) {
for (int i = 0; i n; i += 2)
a[i] += b[i];
}
32](https://image.slidesharecdn.com/20130330x86-study-130329232150-phpapp01/75/LLVM-x86-32-2048.jpg)

![WriQng
Vectorizer-‐Friendly
Code
in
clang
• example.3#
– clang
-‐O3
-‐mllvm
-‐vectorize-‐loops
void test3(float * __restrict__ a,
float * __restrict__ b, int n) {
for (int i = 0; i n; i += 1) {
for (int j = 0; j SIZE; j++)
a[i * SIZE + j] += b[i * SIZE + j];
}
}
34](https://image.slidesharecdn.com/20130330x86-study-130329232150-phpapp01/75/LLVM-x86-34-2048.jpg)

![WriQng
Vectorizer-‐Friendly
Code
in
clang
• example.4#
– clang
-‐O3
-‐mllvm
-‐vectorize-‐loops
float test4(float * __restrict__ a, int n) {
float S = 0.0;
for (int i = 0; i n; i += 1)
S += a[i];
return S;
}
36](https://image.slidesharecdn.com/20130330x86-study-130329232150-phpapp01/75/LLVM-x86-36-2048.jpg)