Download to read offline




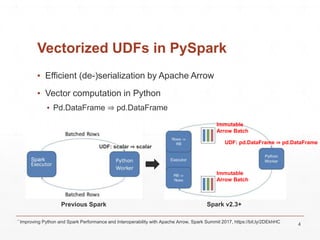
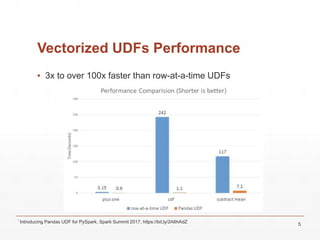


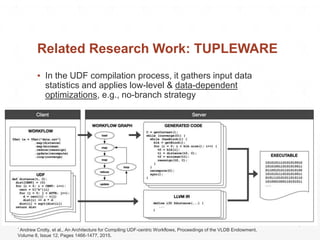






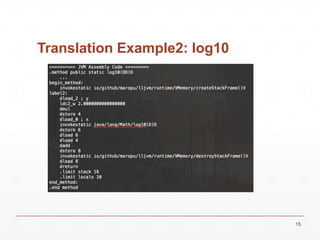


![Address of Java Arrays
18
▪ Super hacky calculation in OpenJDK 8 (64bit)
▪ Java object address in OpenJDK is compressed internally:
Ordinary Object Pointer (OOP)
▪ OOP decompression depends on shift and base values
[address of Java object] := base + ([OOP address] << shift)
▪ These values cannot be referenced on runtime, so LLJVM infers
the two values by comparing OOP/raw addresses
See: https://github.com/maropu/lljvm-translator/blob/master/core/src/main/java/io/github/maropu/lljvm/util/ArrayUtils.java](https://image.slidesharecdn.com/lljvm-181119073402/85/LLJVM-LLVM-bitcode-to-JVM-bytecode-18-320.jpg)



LLJVM is a library that translates LLVM bitcode to JVM bytecode. It was originally created to optimize Python UDFs in PySpark by compiling them to bitcode using Numba and then translating that to run on JVMs. However, LLJVM currently only supports a limited set of LLVM instructions and data types. It focuses on translating simple Numba-generated bitcode and providing runtime support functions. Translating more complex UDFs could improve PySpark performance significantly by avoiding serialization overhead and allowing whole-stage codegen.










































































