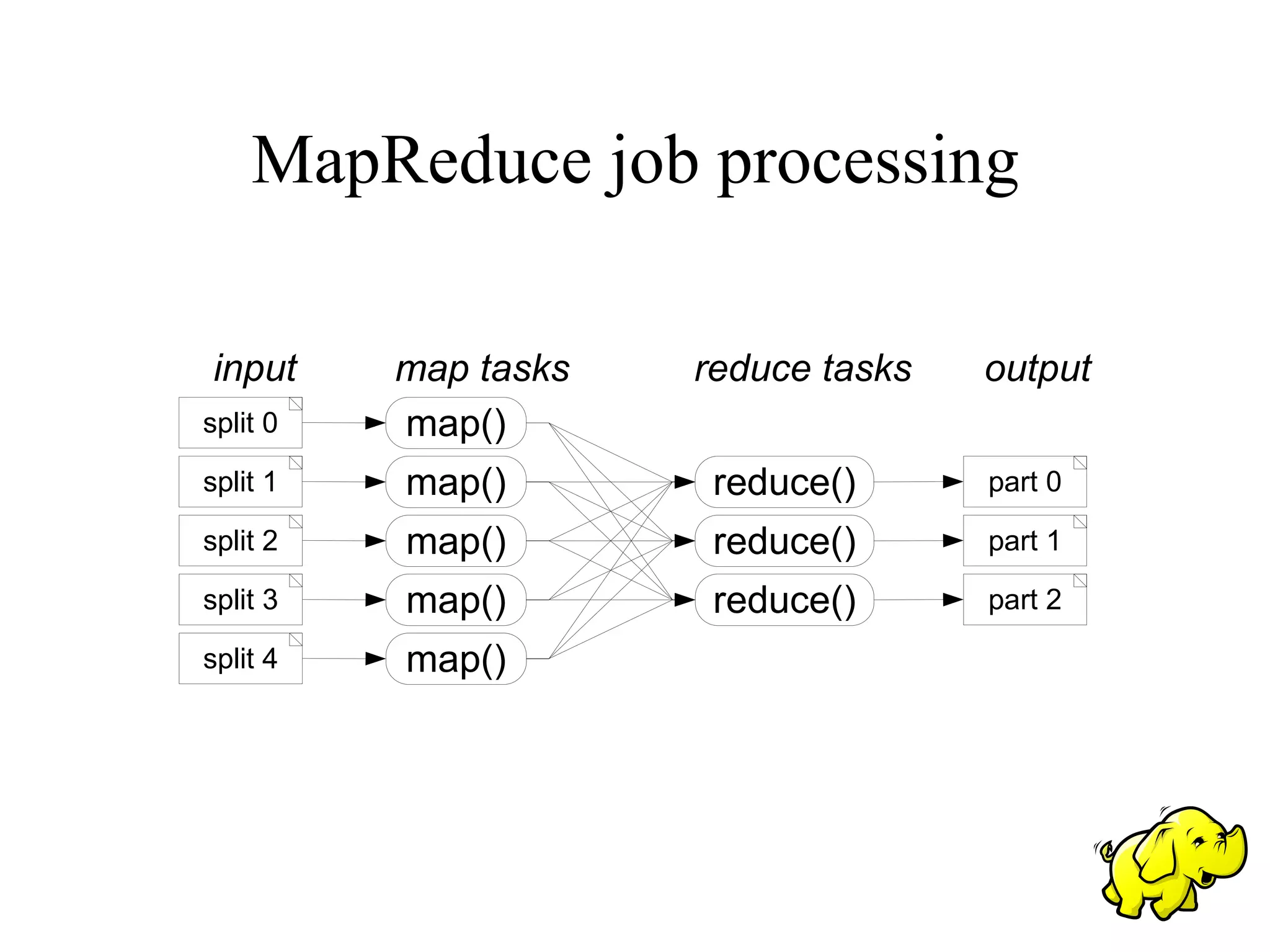
This document summarizes Doug Cutting's presentation on using Hadoop for scalable web crawling and indexing with the Nutch project. It describes how Nutch algorithms like crawling, parsing, link inversion, and indexing were converted to MapReduce jobs that can scale to billions of web pages. The document outlines the key Nutch algorithms and how they were adapted to the Hadoop framework using MapReduce.







![Example: main()
public static void main(String[] args) throws IOException {
NutchConf defaults = NutchConf.get();
JobConf job = new JobConf(defaults);
job.setInputDir(new File(args[0]));
job.setMapperClass(RegexMapper.class);
job.set("mapred.mapper.regex", args[2]);
job.set("mapred.mapper.regex.group", args[3]);
job.setReducerClass(LongSumReducer.class);
job.setOutputDir(args[1]);
job.setOutputKeyClass(UTF8.class);
job.setOutputValueClass(LongWritable.class);
JobClient.runJob(job);
}](https://image.slidesharecdn.com/10345-090803094023-phpapp02/75/hadoop-9-2048.jpg)
















































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)

















