Downloaded 160 times









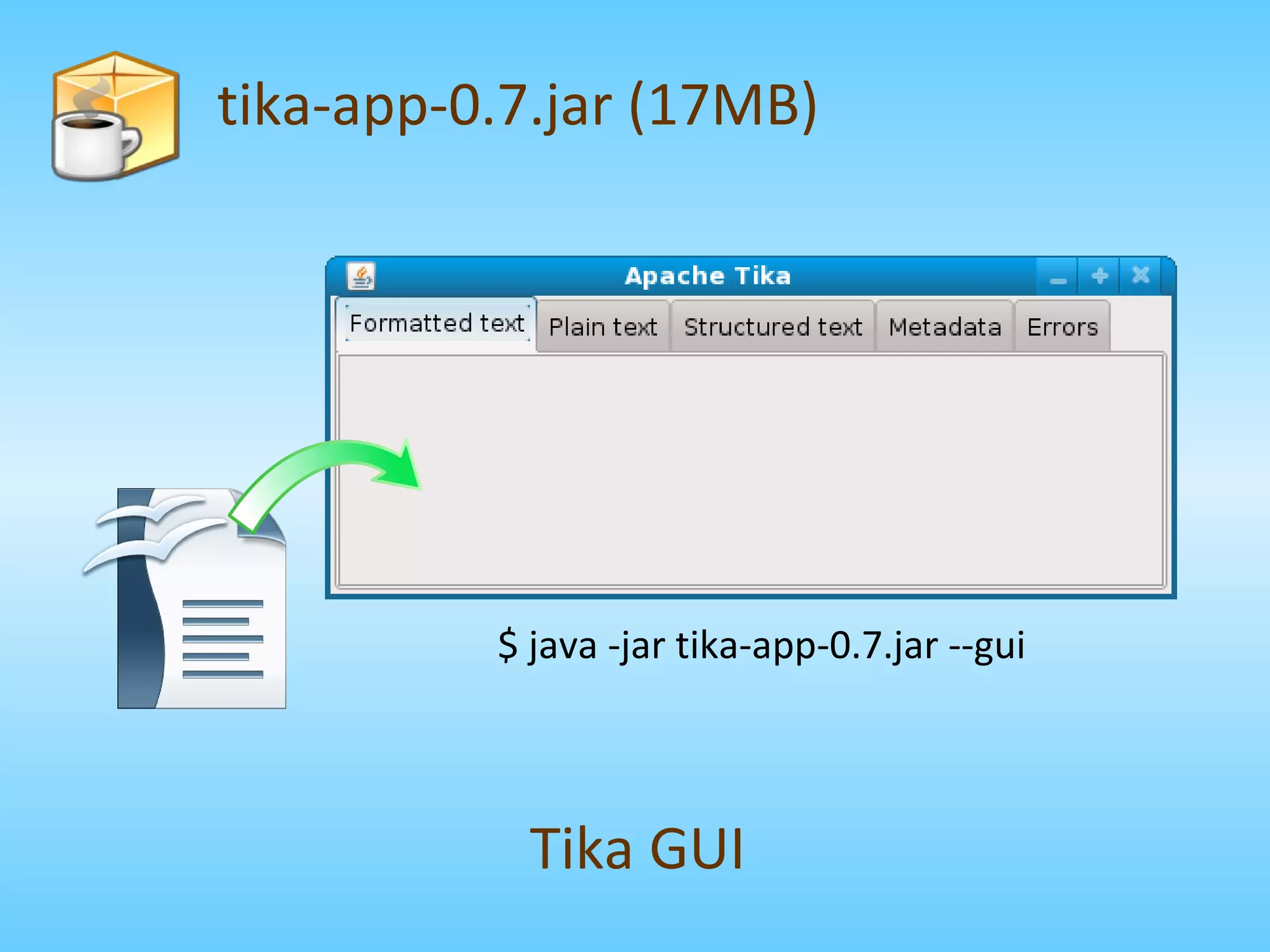
























The document provides an overview of Apache Tika, an open-source content analysis toolkit. It discusses Tika's history and basics, including its architecture, parsers, metadata extraction, and common use cases. The document also outlines how Tika can be integrated into applications and addresses some frequently asked questions.




































































































