Downloaded 5,526 times








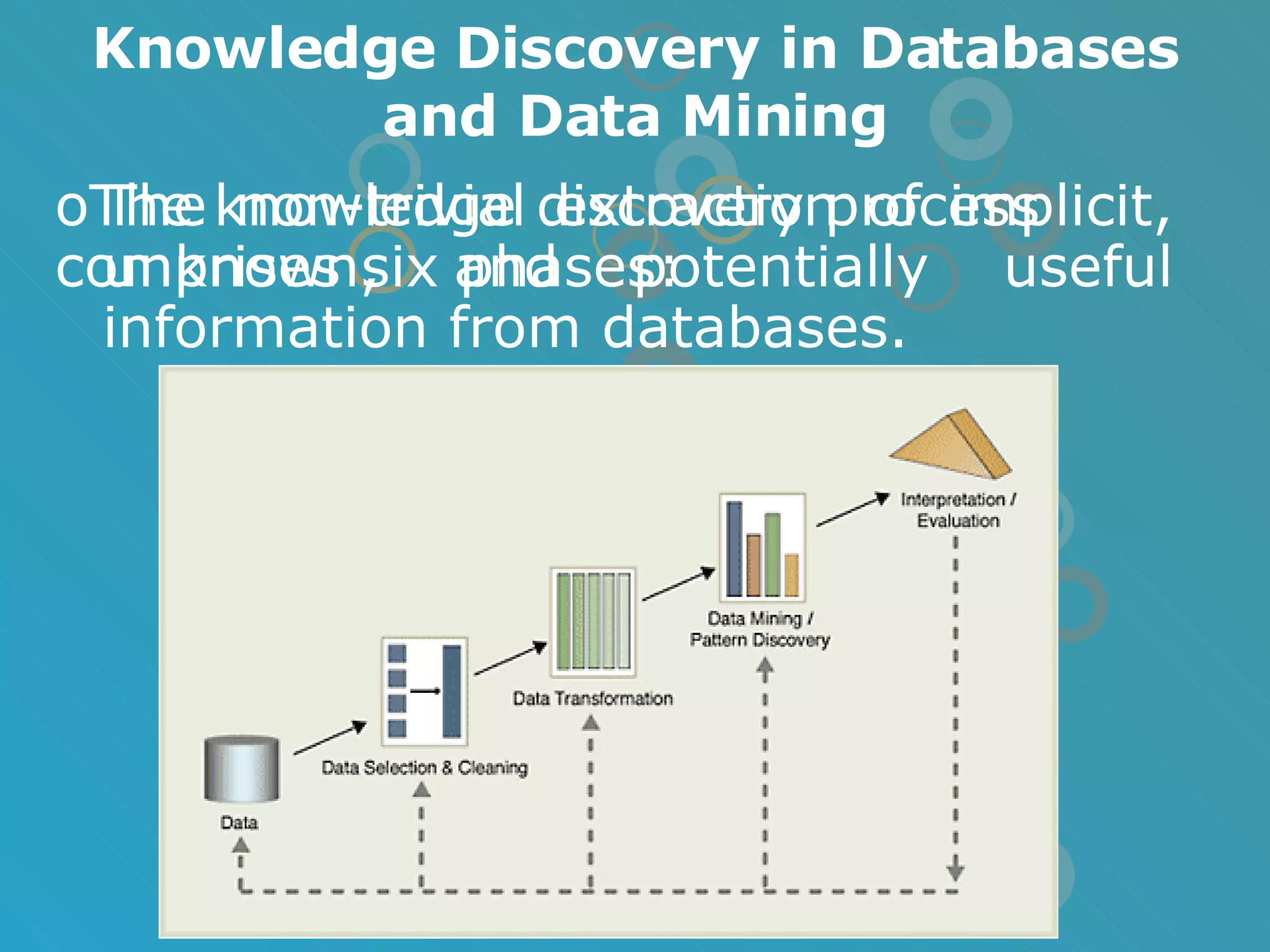





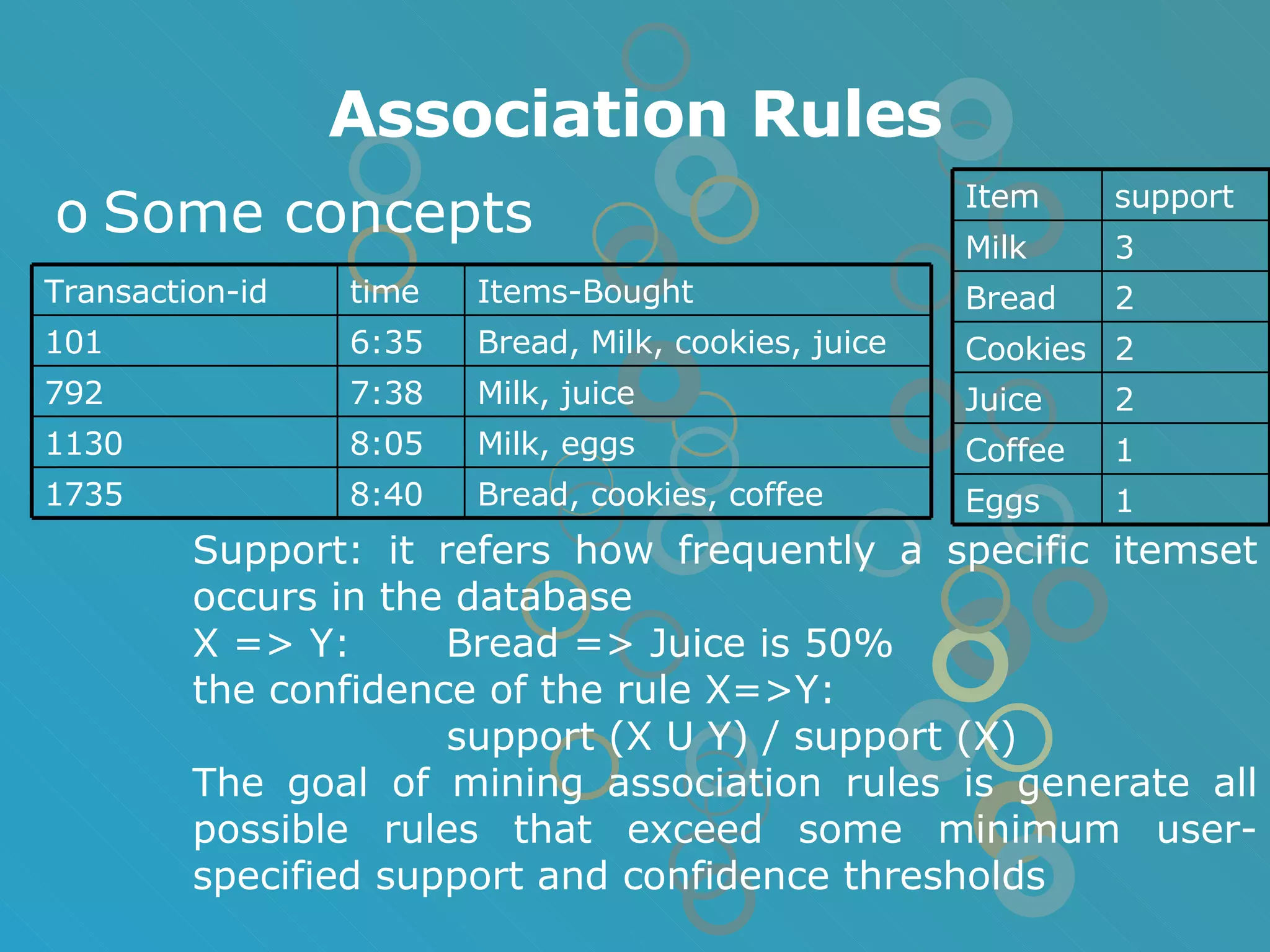

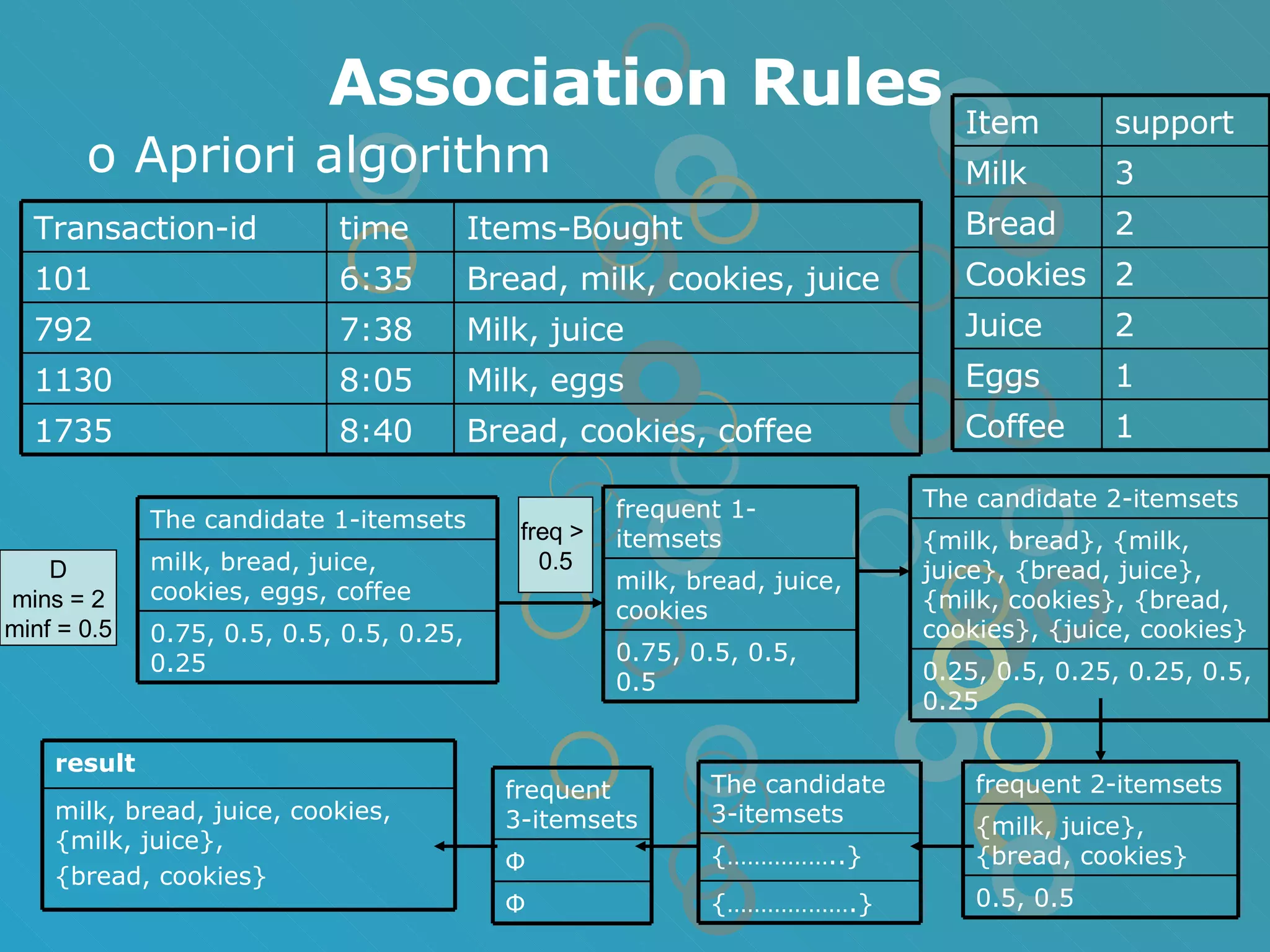




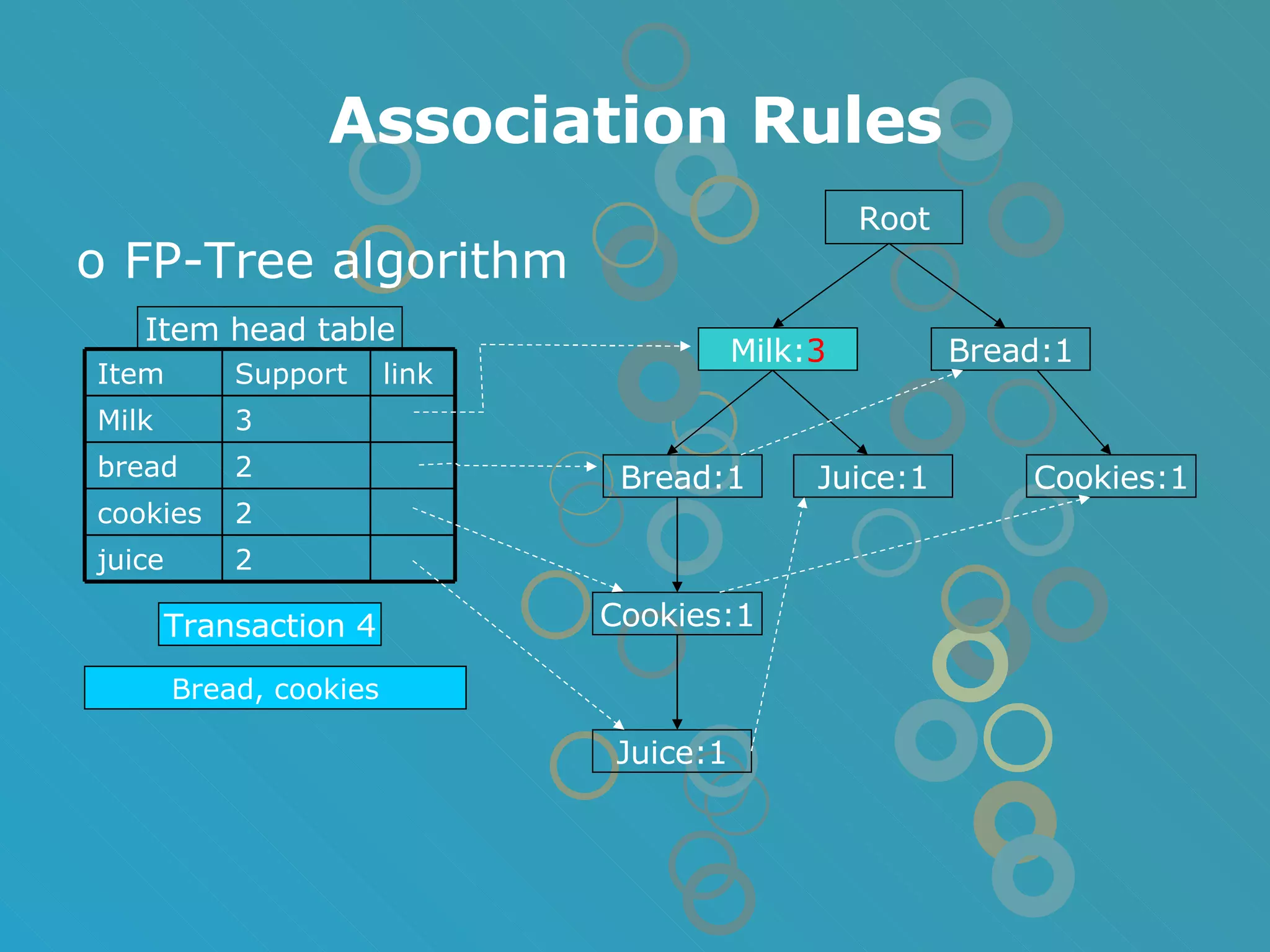
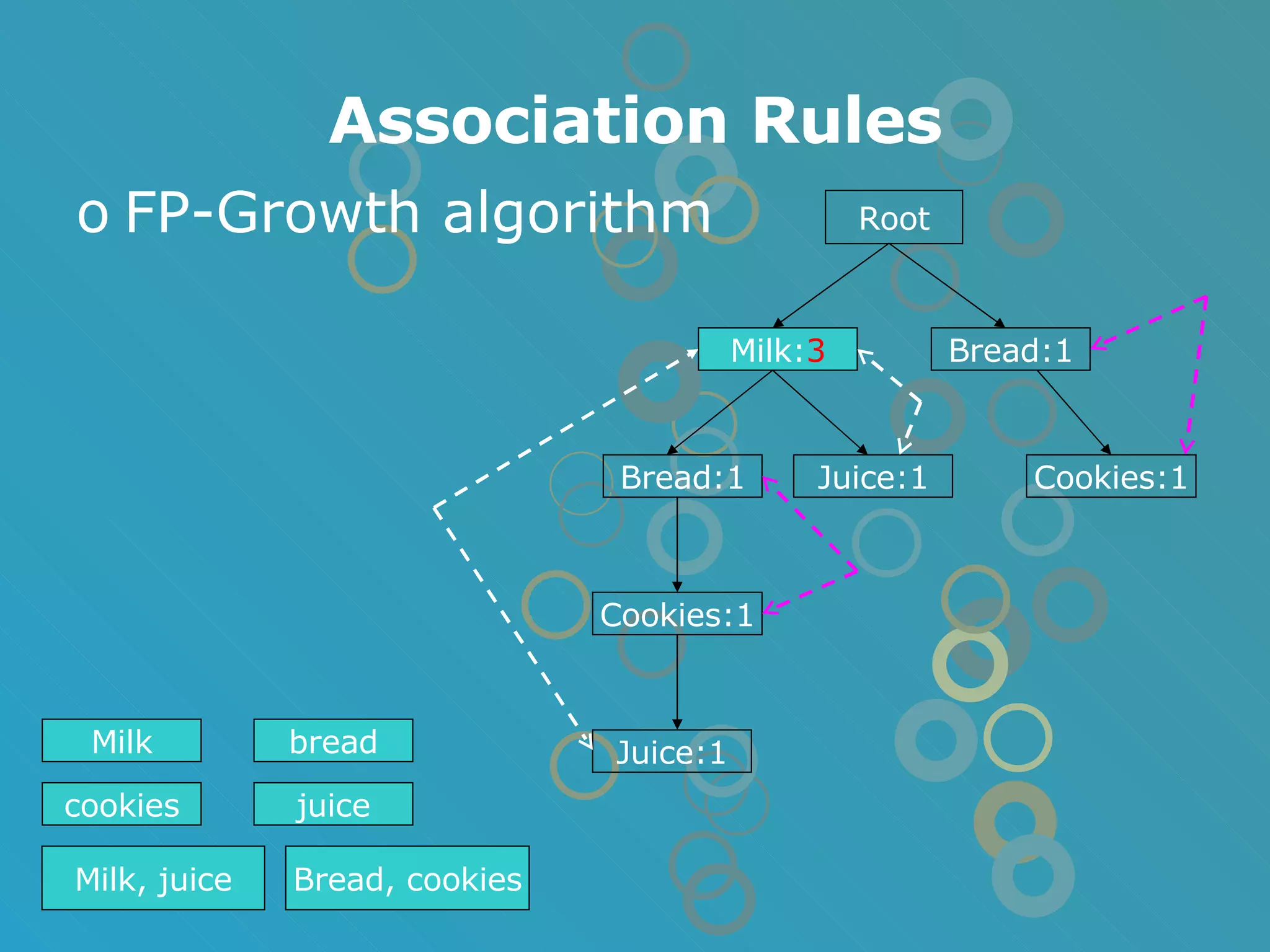


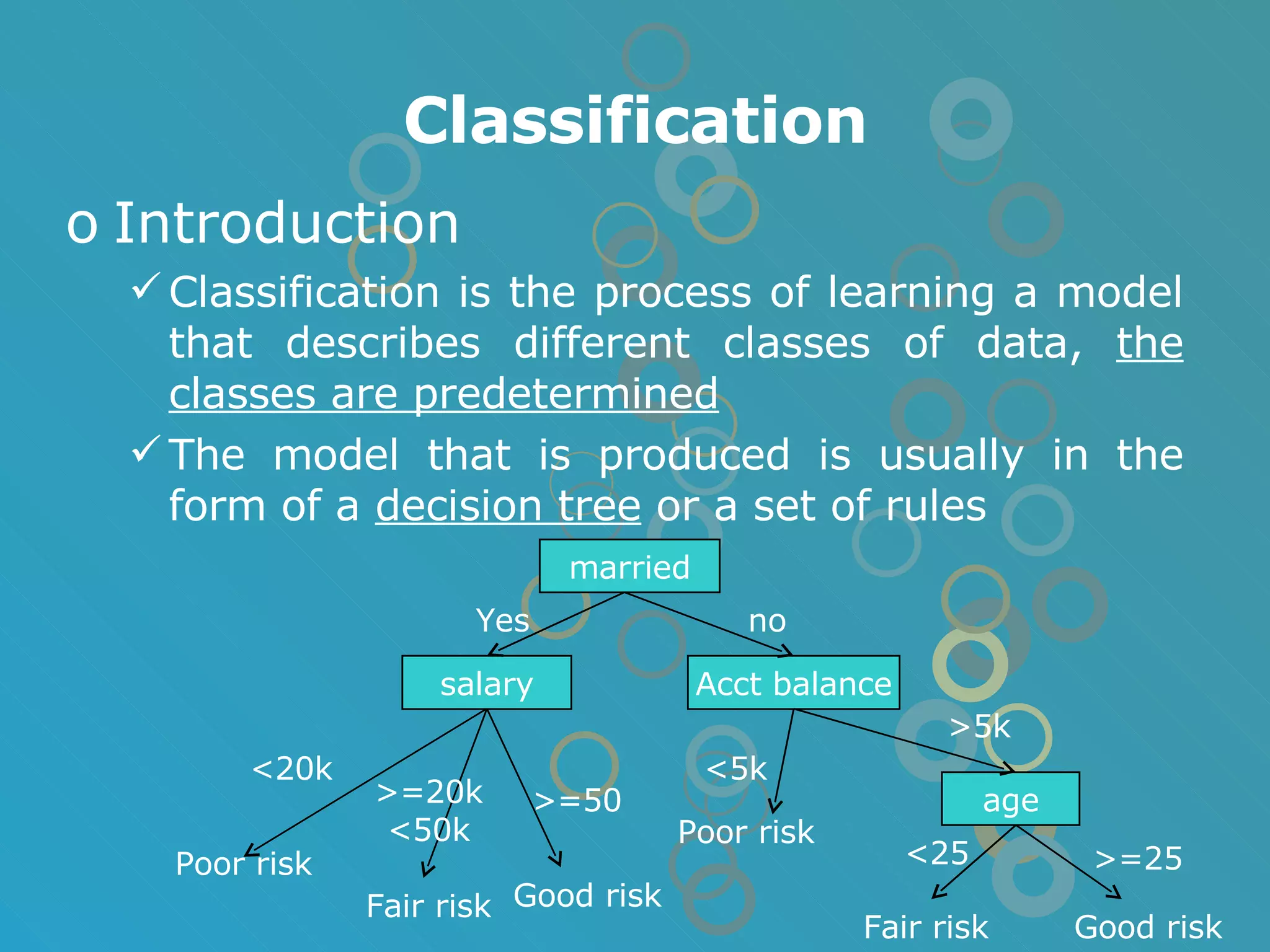









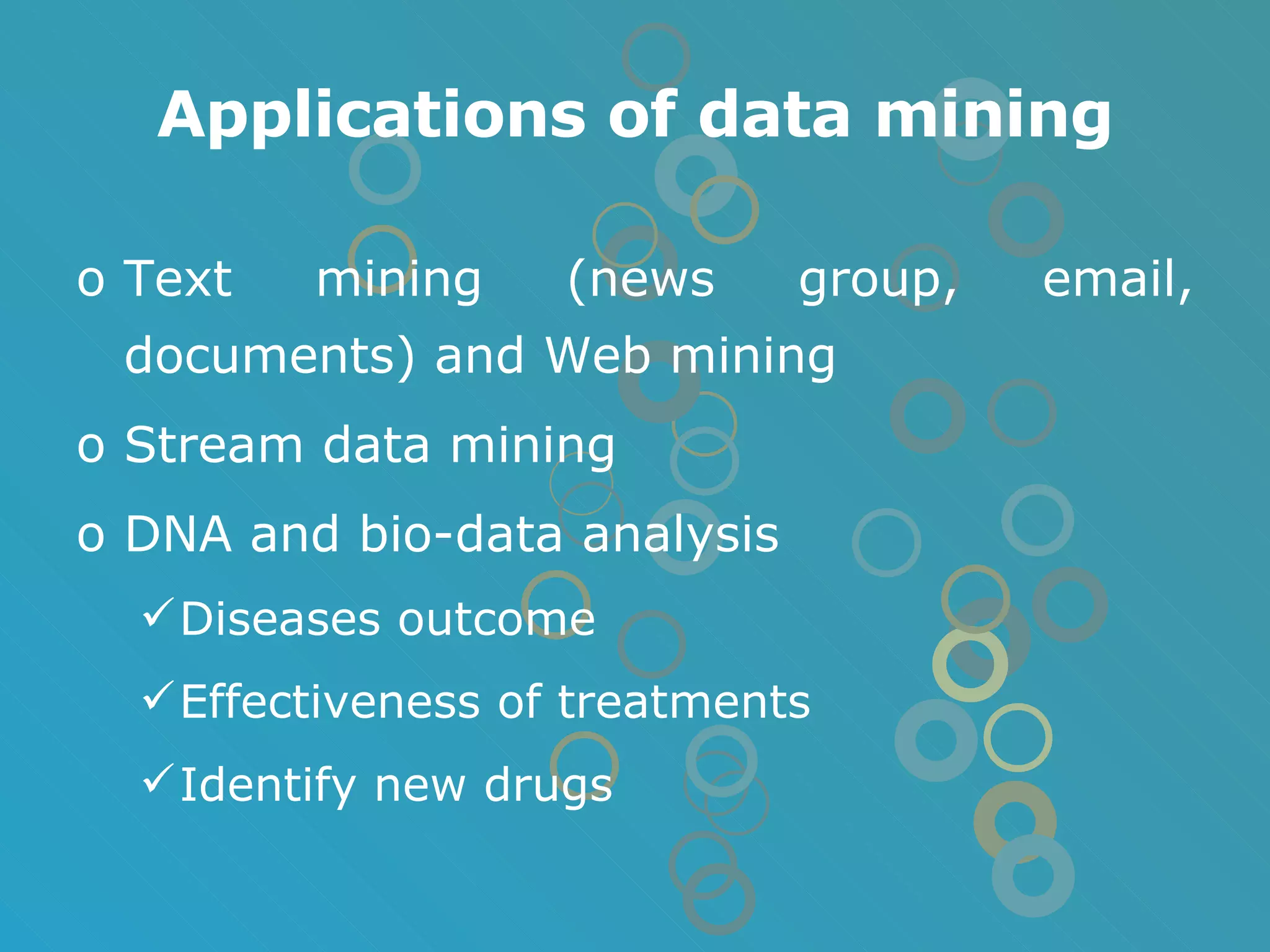





The document provides an overview of data mining concepts including association rules, classification, and clustering algorithms. It introduces data mining and knowledge discovery processes. Association rule mining aims to find relationships between variables in large datasets using the Apriori and FP-growth algorithms. Classification algorithms build a model to predict class membership for new records based on a decision tree. Clustering algorithms group similar records together without predefined classes.















































































