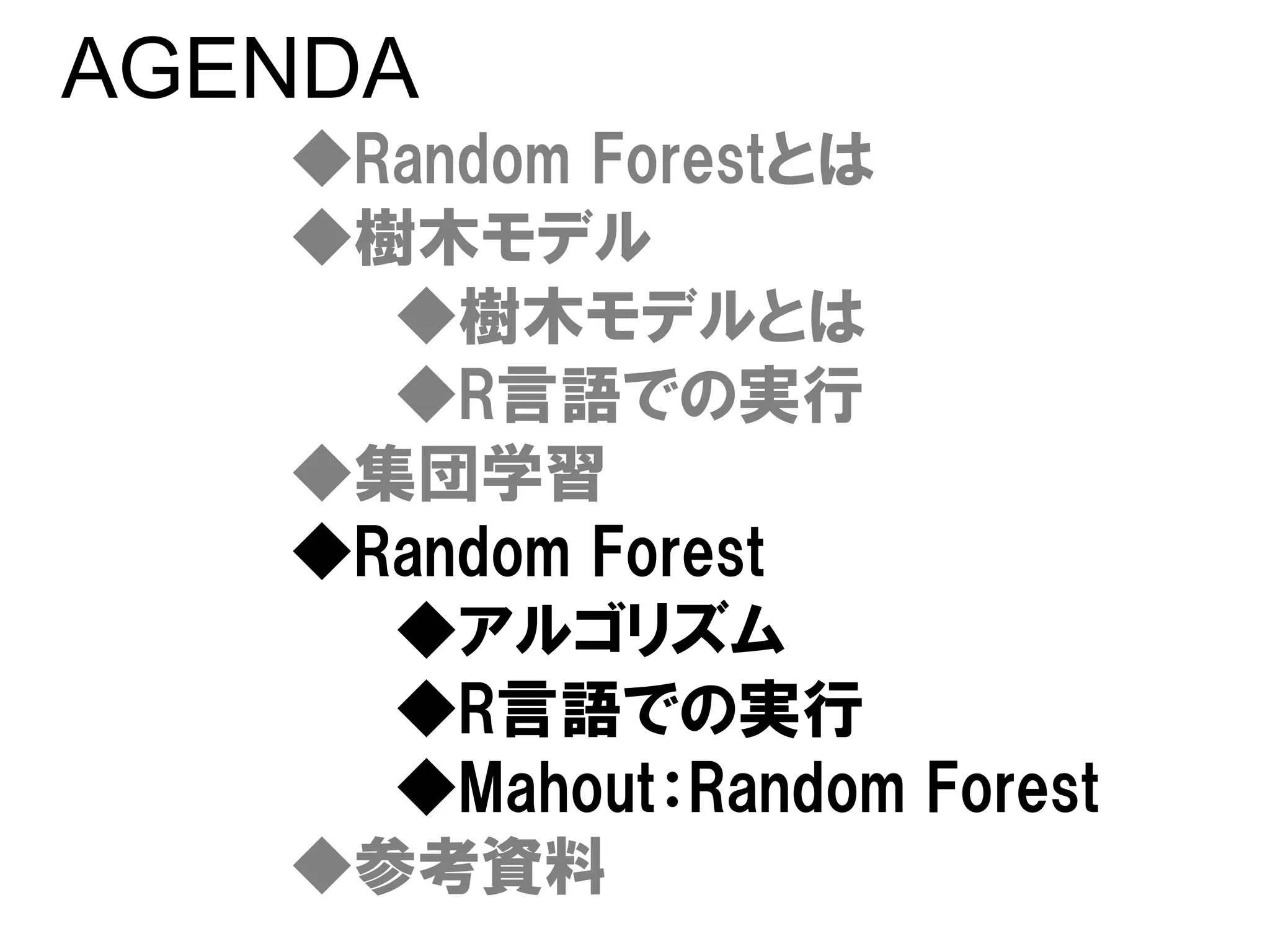
「樹木モデルとランダムフォレスト(Tree-based Models and Random Forest) -機械学習による分類・予測-」。 Tree-based Model, Random Forest の入門的な内容です。機械学習・データマイニングセミナー 2010/10/07 。 hamadakoichi 濱田晃一
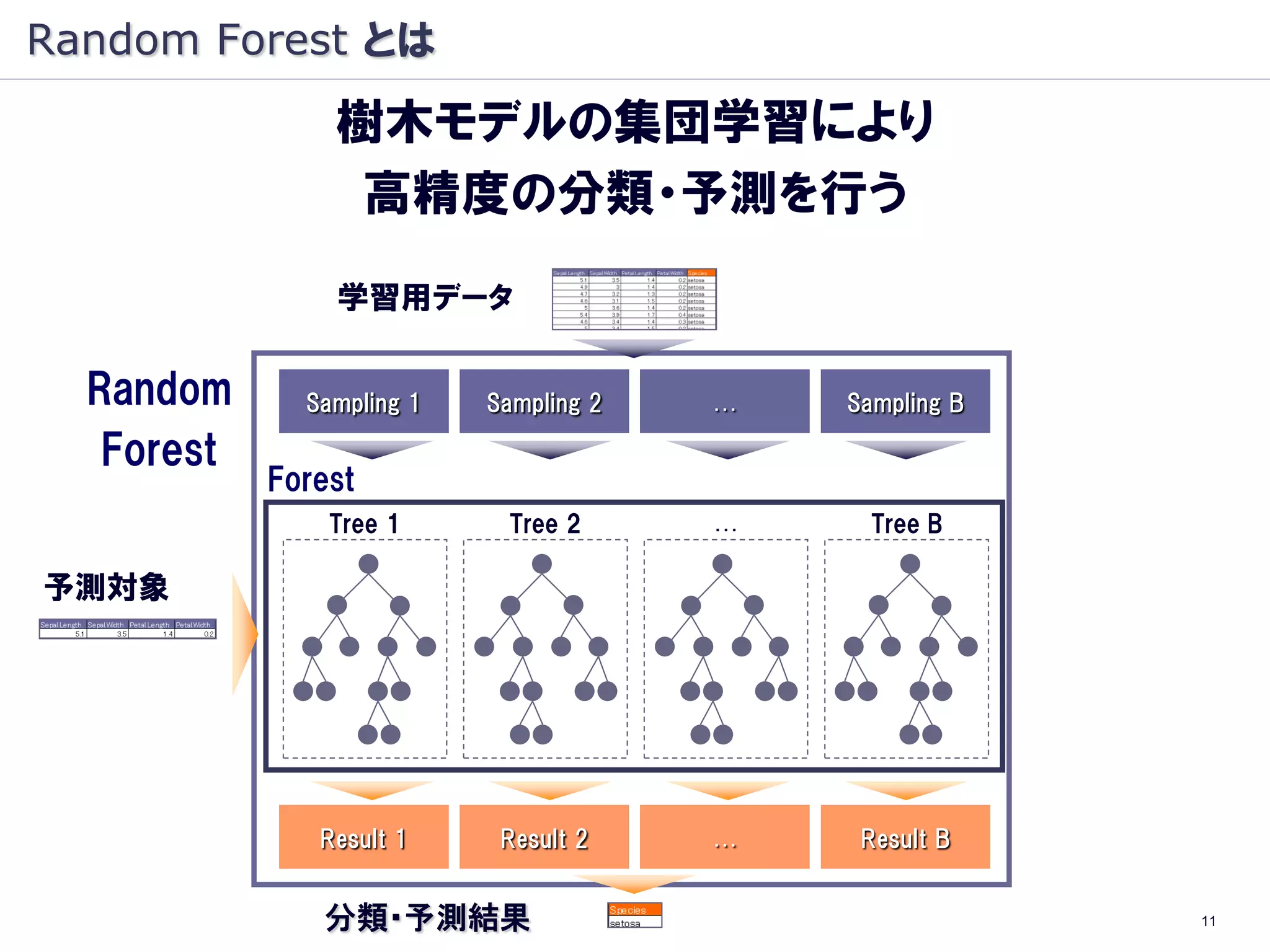
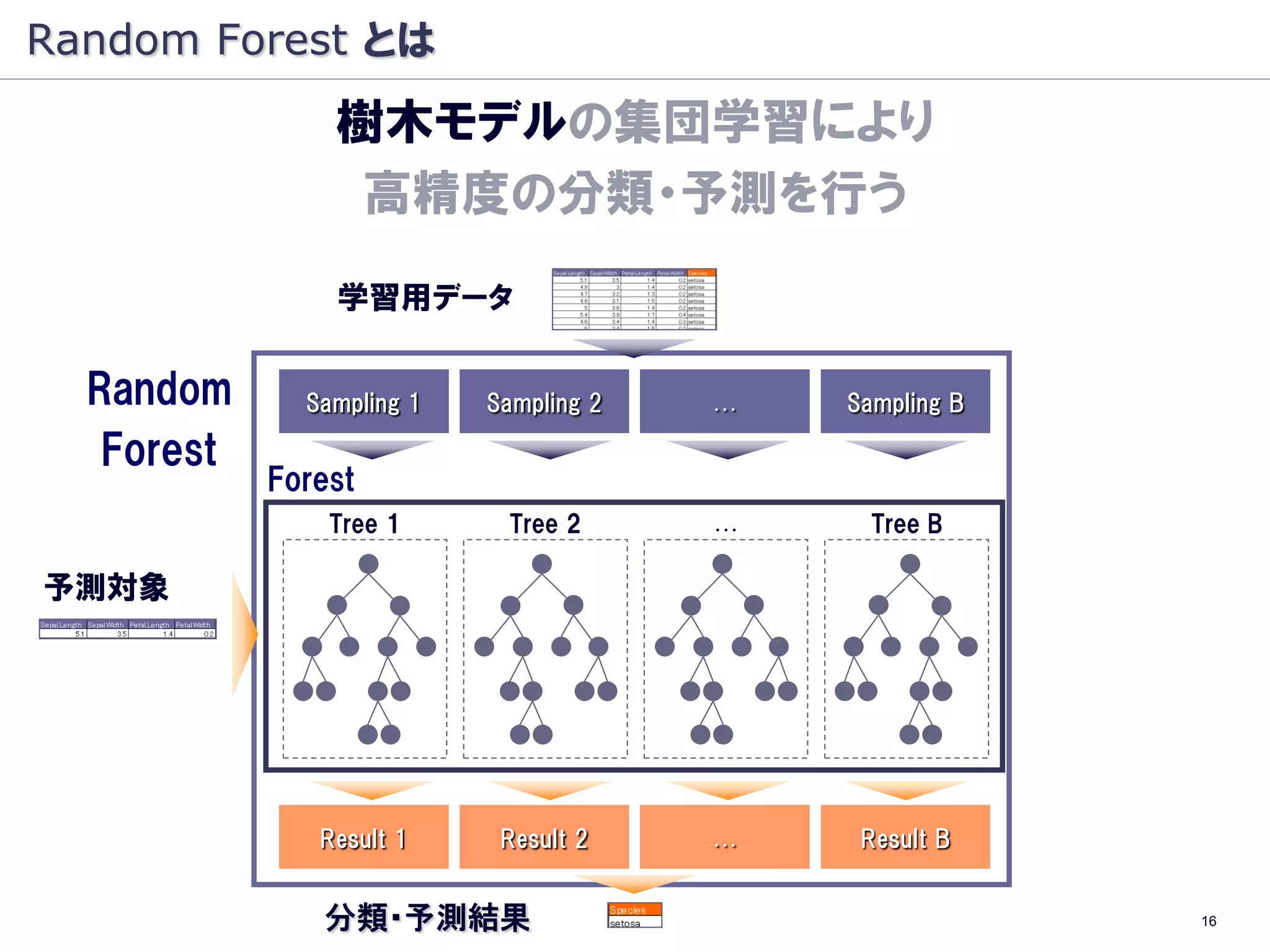
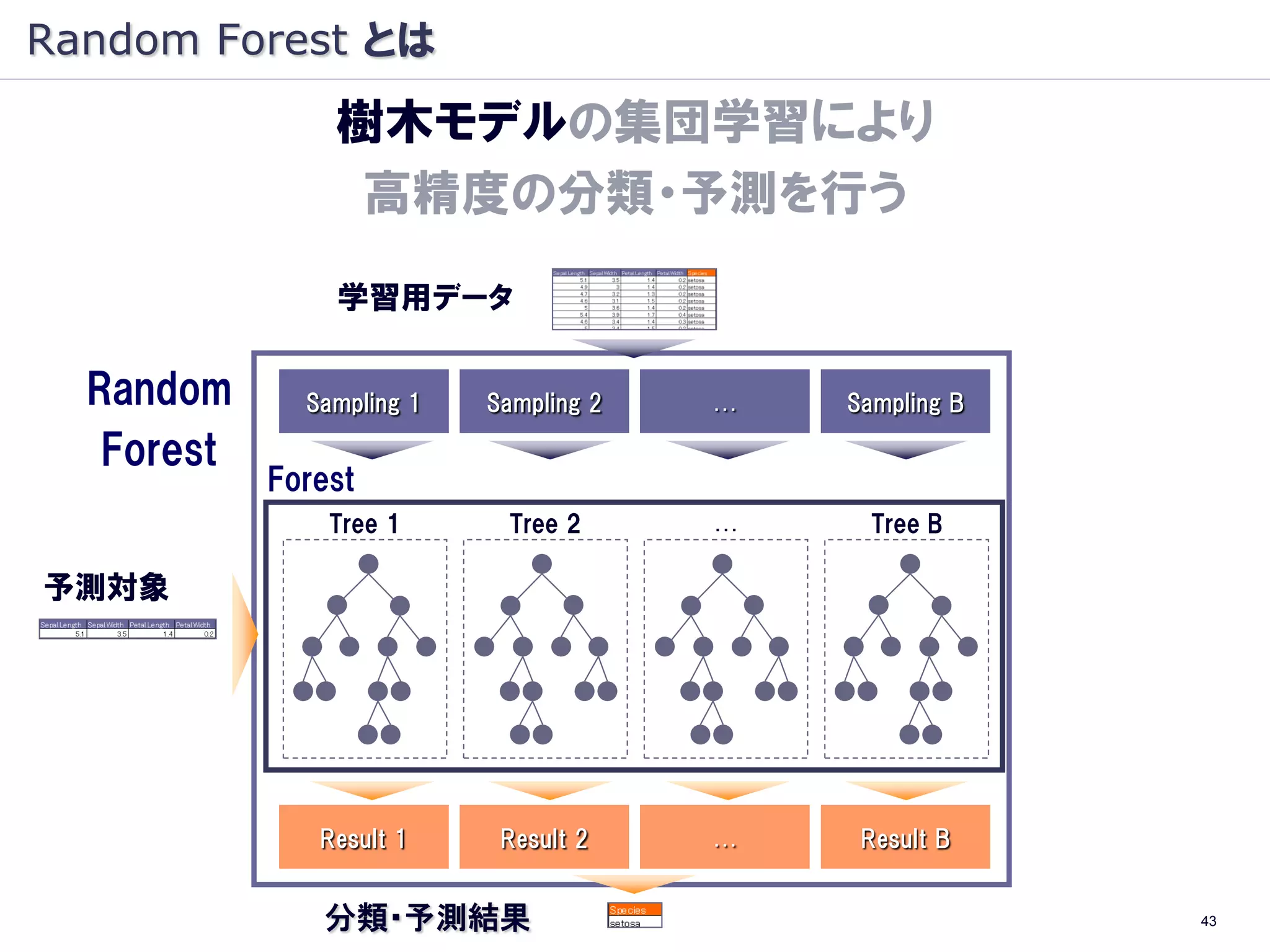
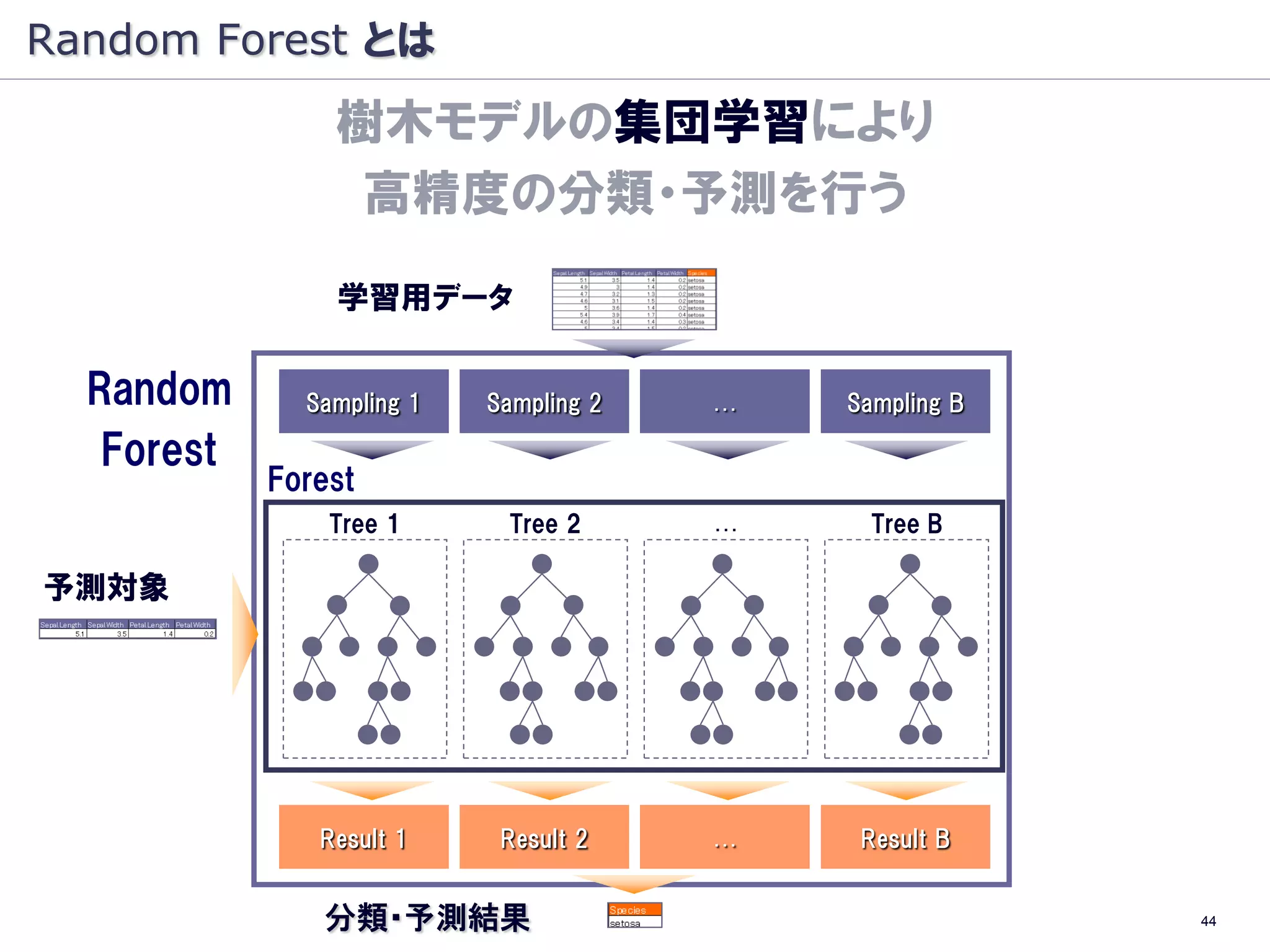
Random Forest とは
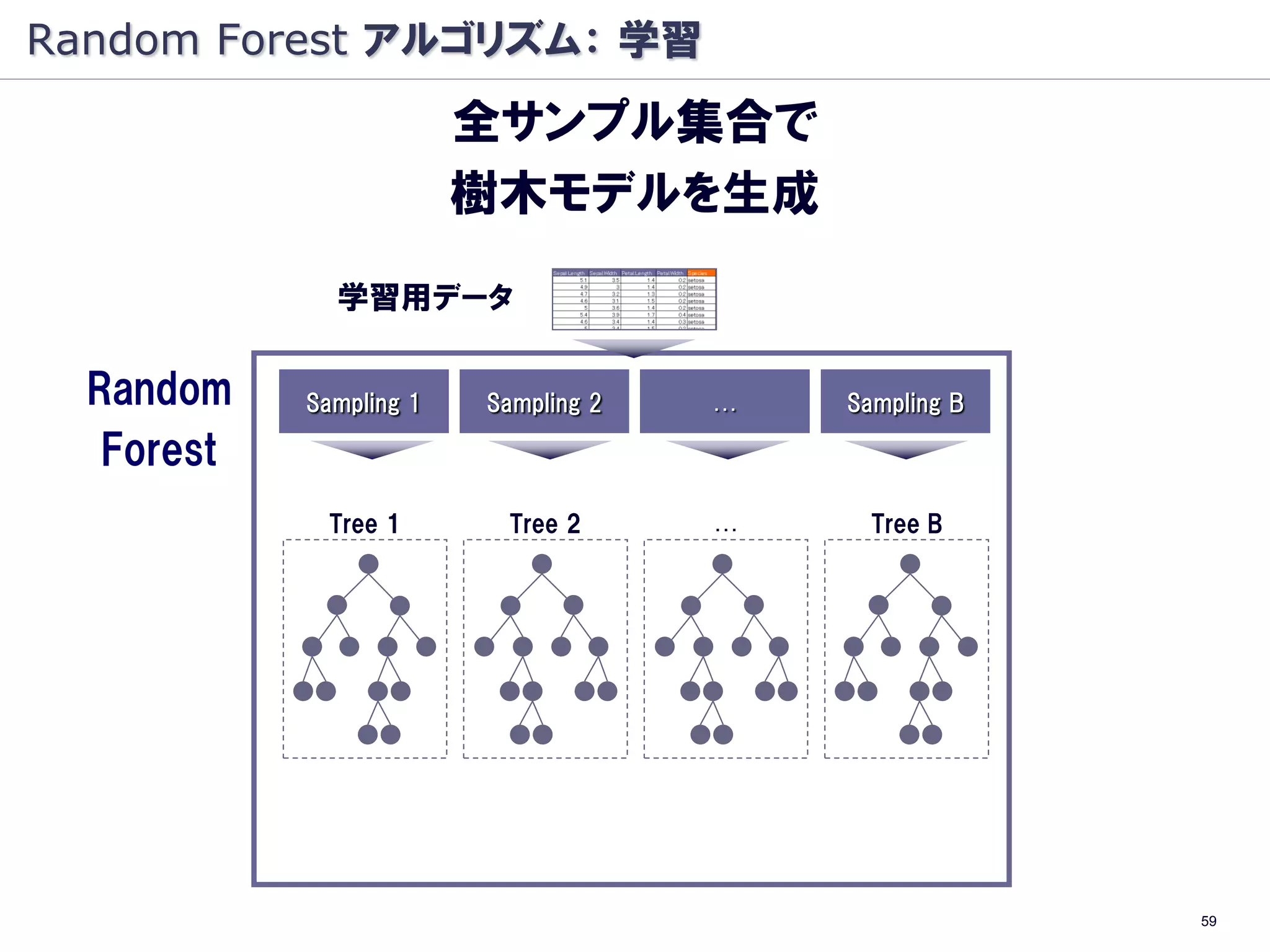
樹木モデルの集団学習により
高精度の分類・予測を行う
学習用データ
Random Sampling 1 Sampling 2 … Sampling B
Forest
Forest
Tree 1 Tree 2 … Tree B
予測対象
Result 1 Result 2 … Result B
分類・予測結果 11
12.
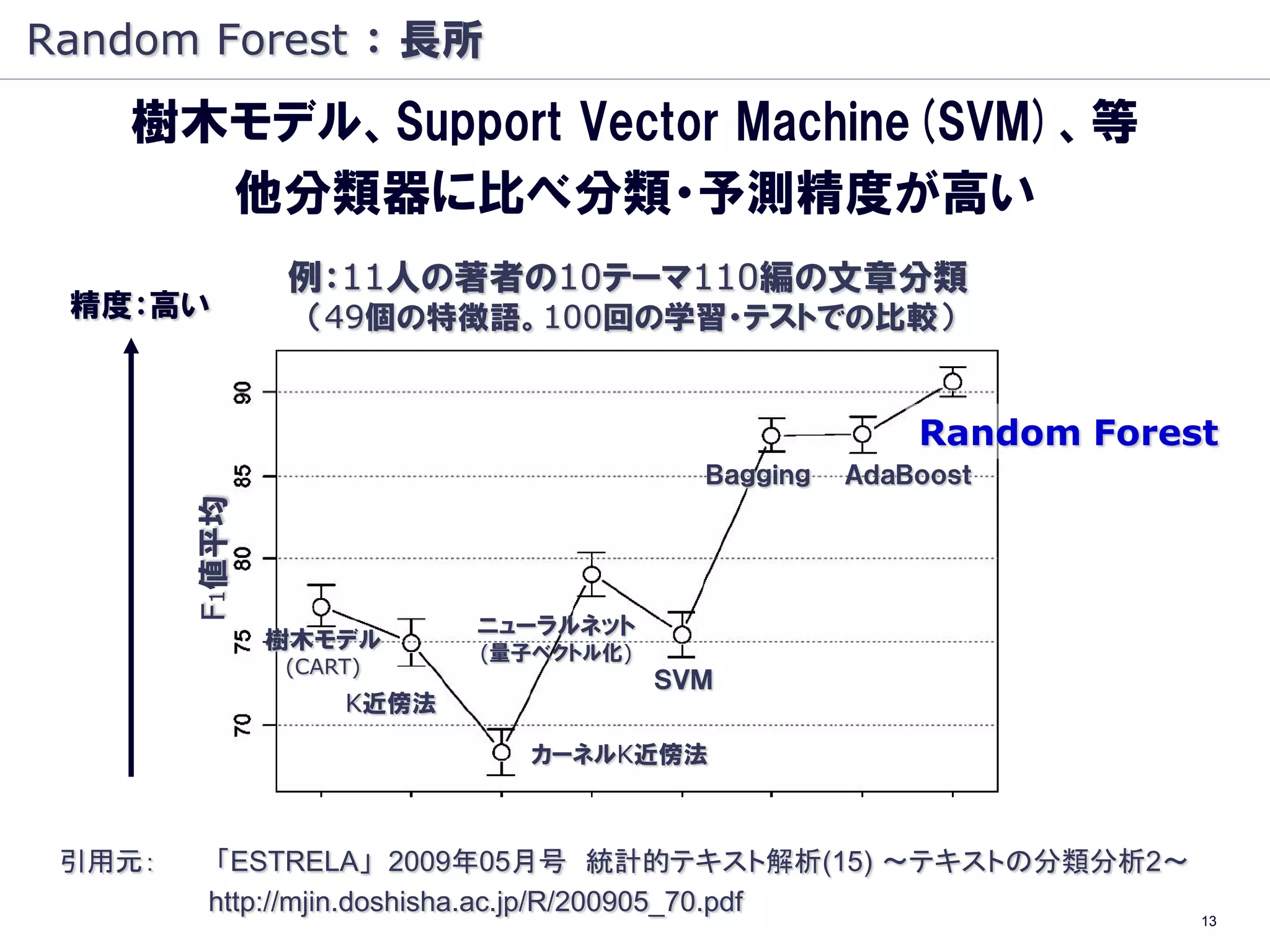
Random Forest :長所
Random Forest の
主な長所
・精度が高い
・説明変数が数百、数千でも効率的に作動
・目的変数に対する説明変数の重要度を推定
・欠損値を持つデータでも有効に動作
・個体数がアンバランスでもエラーバランスが保たれる
12
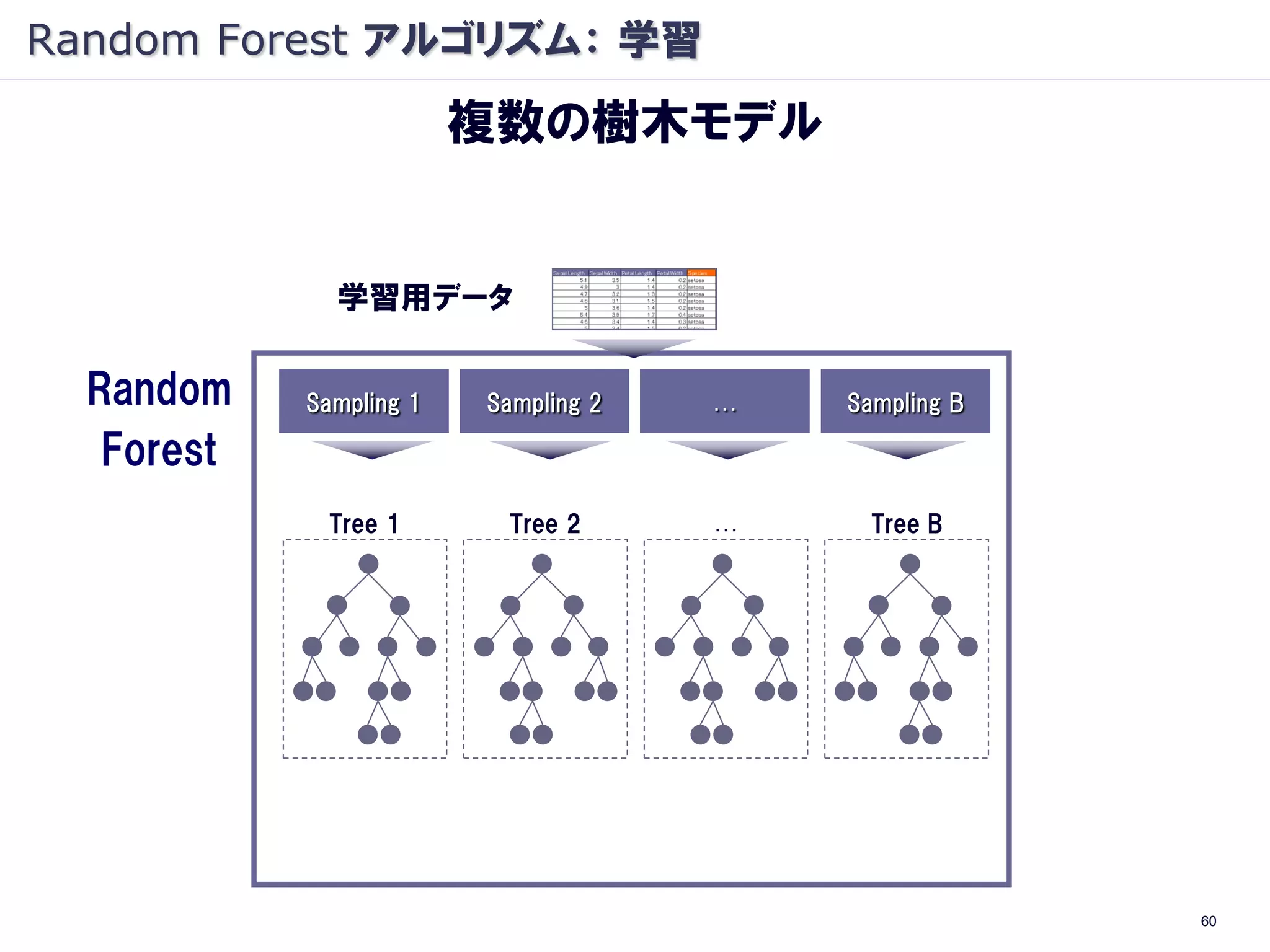
Random Forest とは
樹木モデルの集団学習により
高精度の分類・予測を行う
学習用データ
Random Sampling 1 Sampling 2 … Sampling B
Forest
Forest
Tree 1 Tree 2 … Tree B
予測対象
Result 1 Result 2 … Result B
分類・予測結果 14
15.
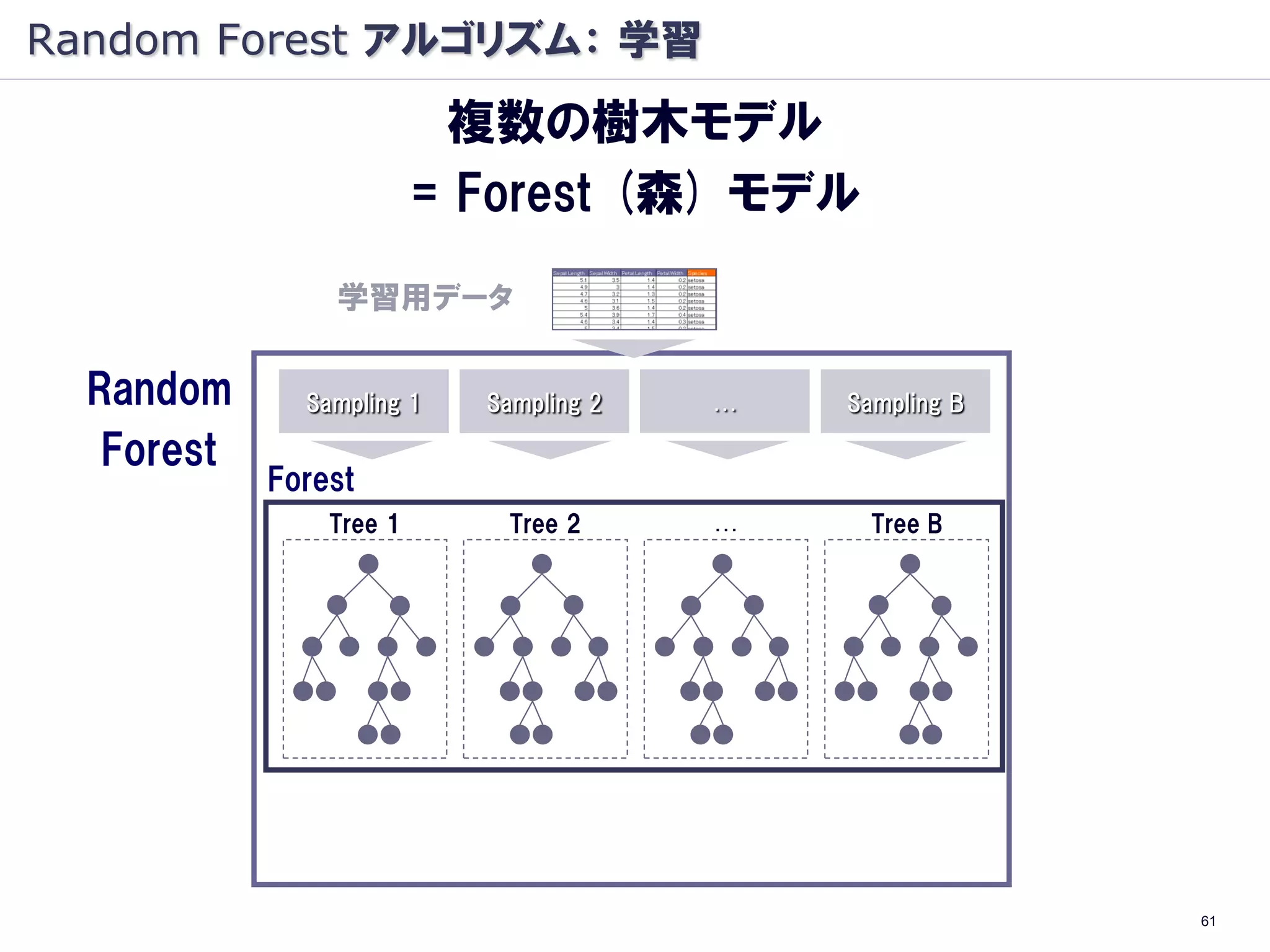
Random Forest とは
樹木モデルの集団学習により
高精度の分類・予測を行う
学習用データ
Random Sampling 1 Sampling 2 … Sampling B
Forest
Forest
Tree 1 Tree 2 … Tree B
予測対象
Result 1 Result 2 … Result B
分類・予測結果 15
16.
Random Forest とは
樹木モデルの集団学習により
高精度の分類・予測を行う
学習用データ
Random Sampling 1 Sampling 2 … Sampling B
Forest
Forest
Tree 1 Tree 2 … Tree B
予測対象
Result 1 Result 2 … Result B
分類・予測結果 16
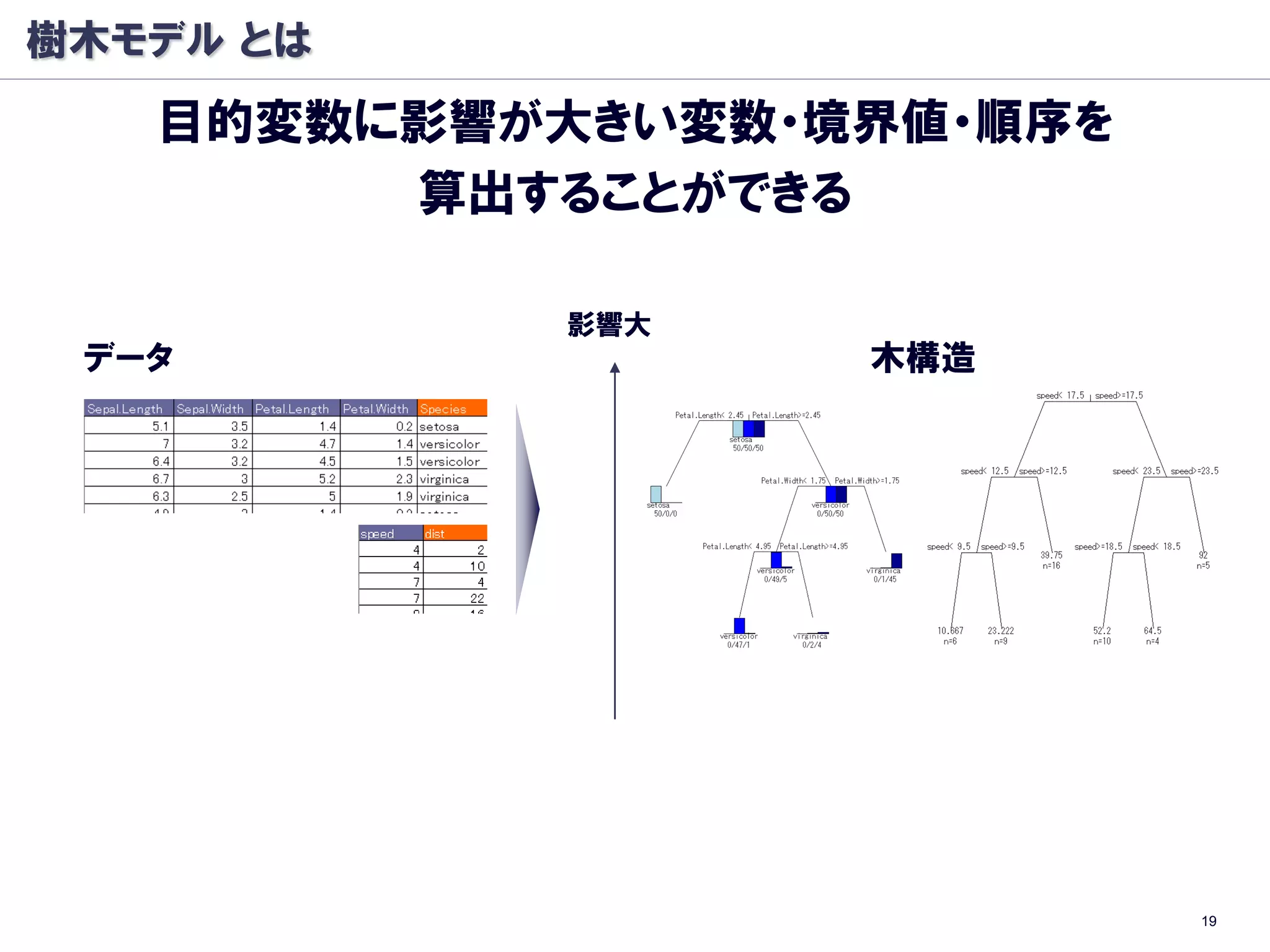
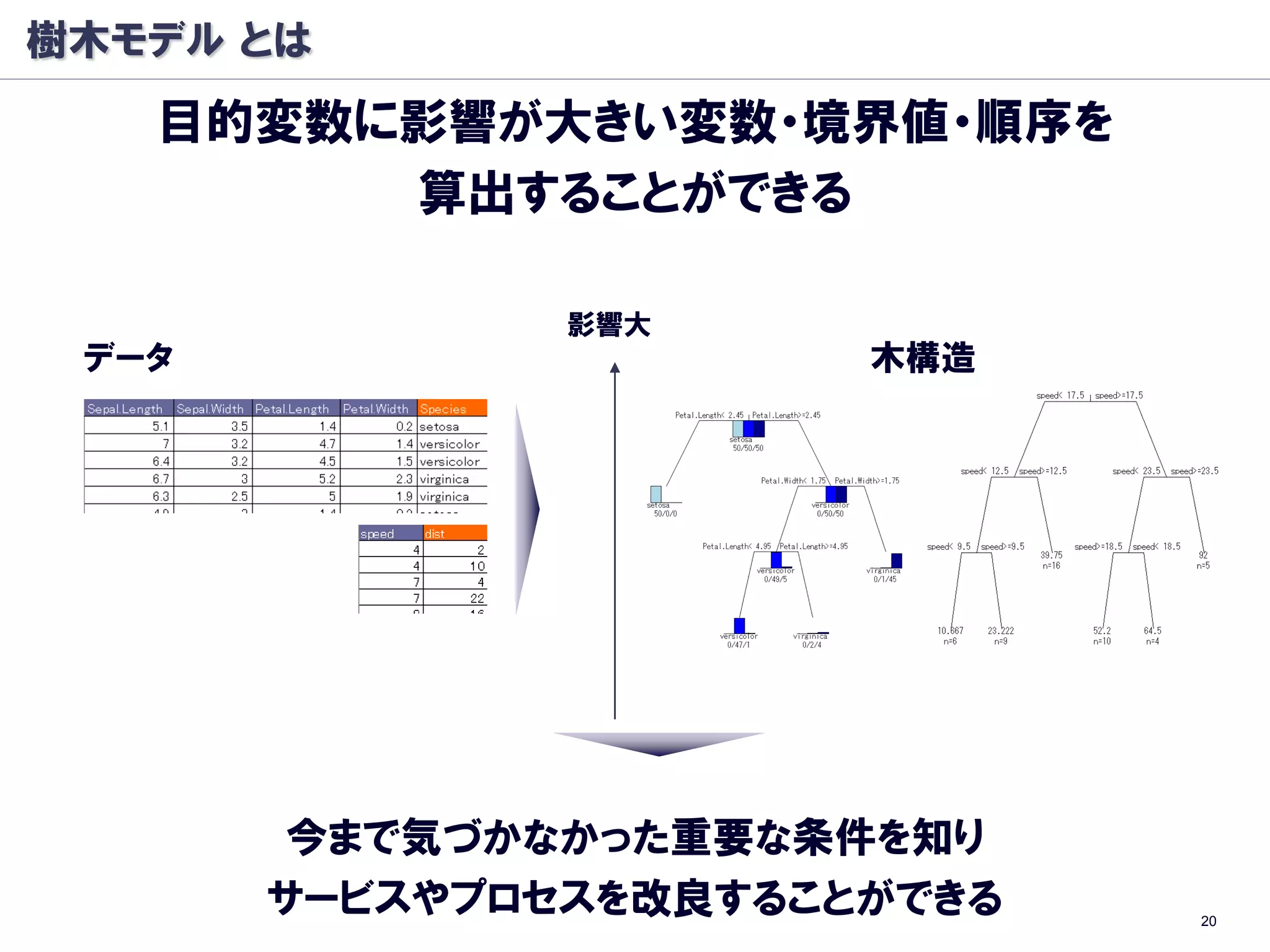
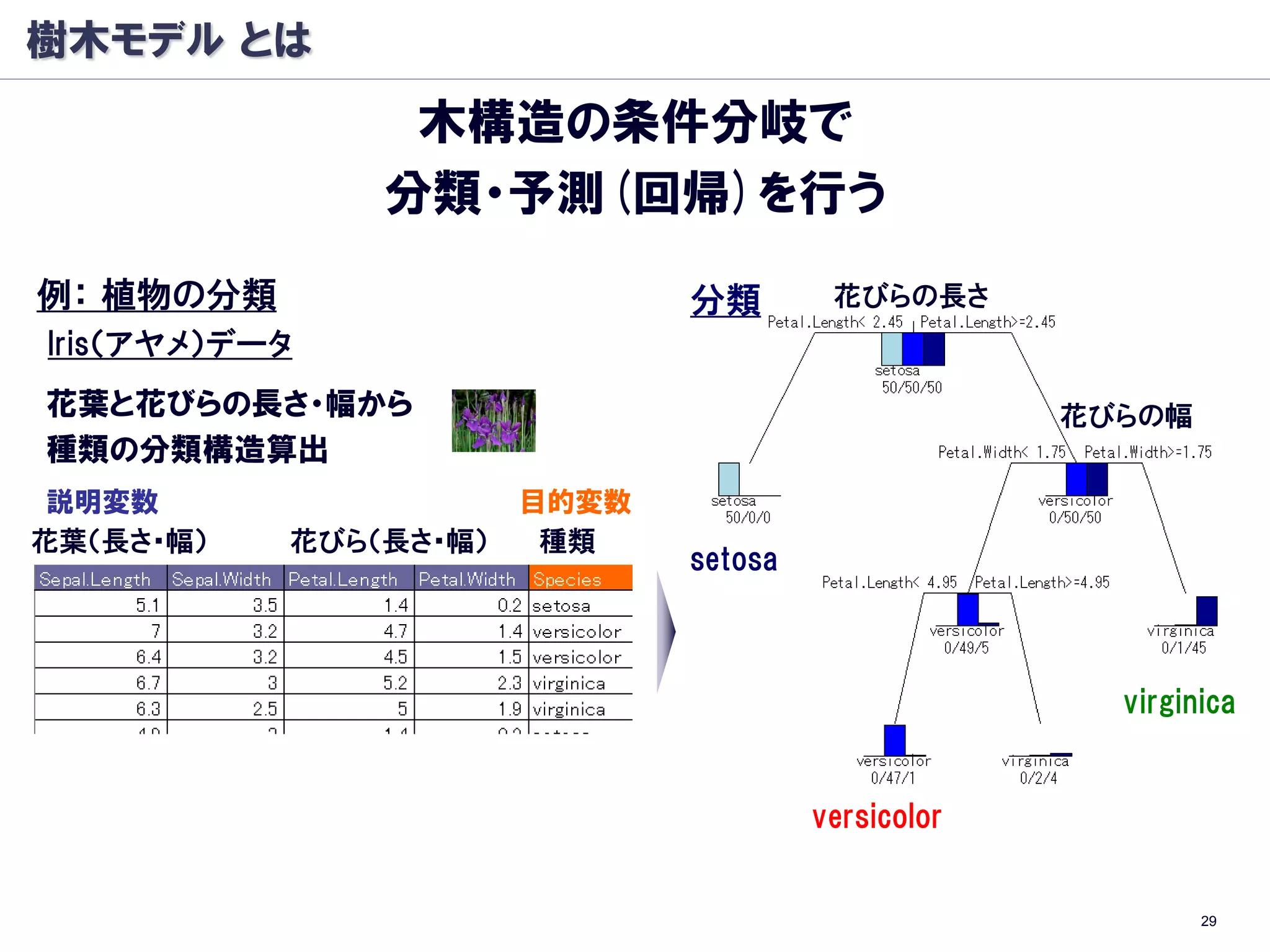
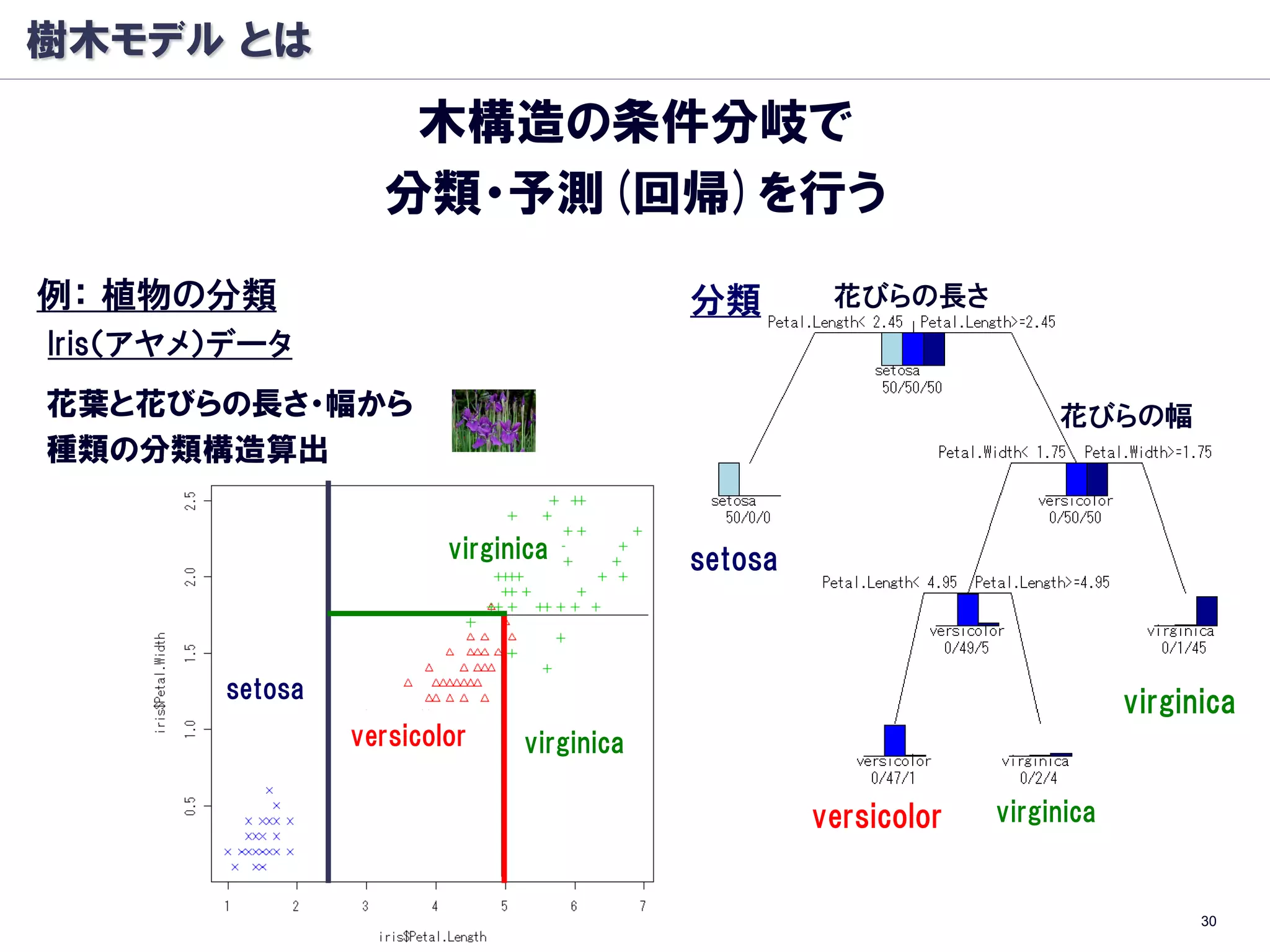
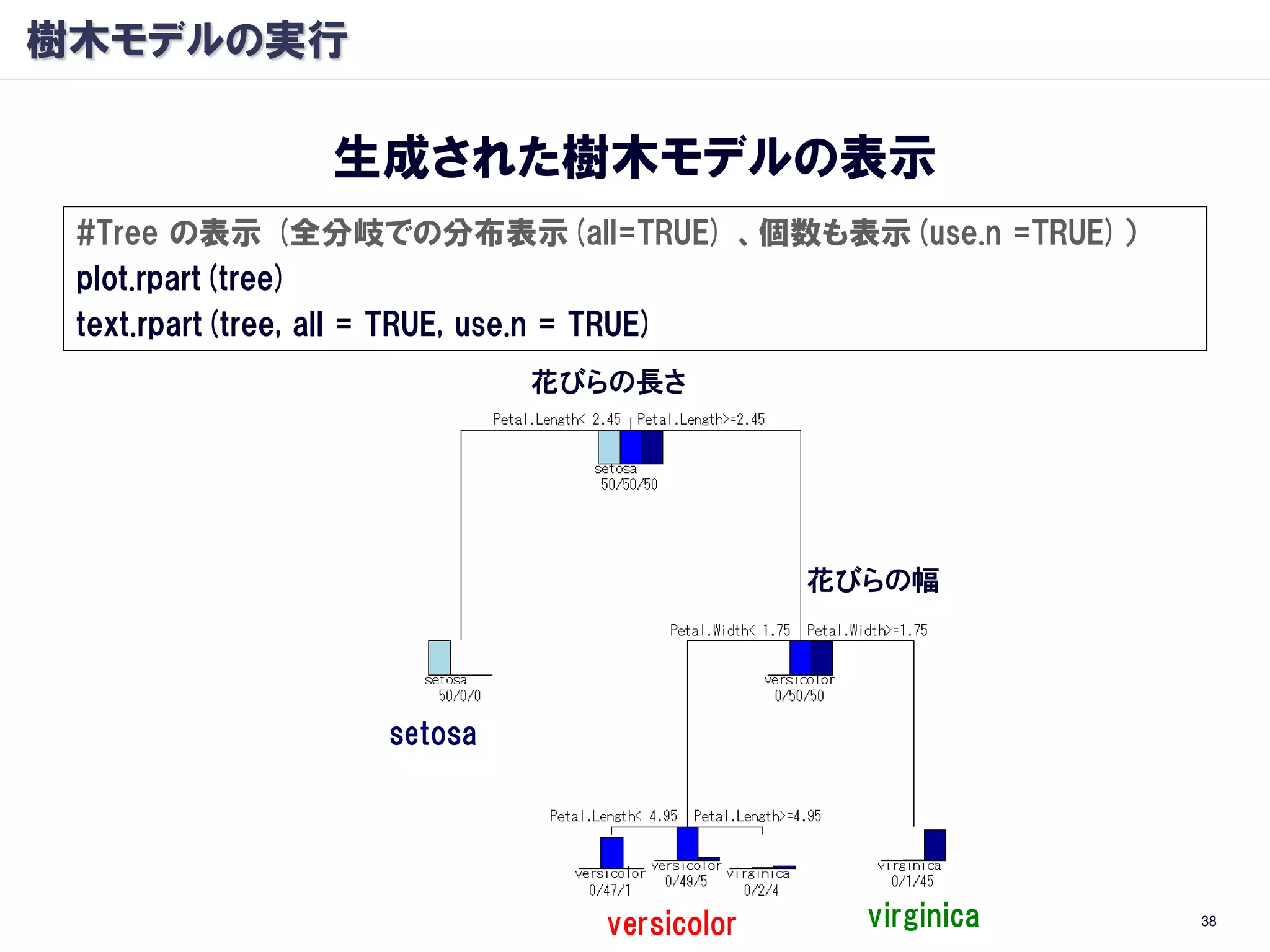
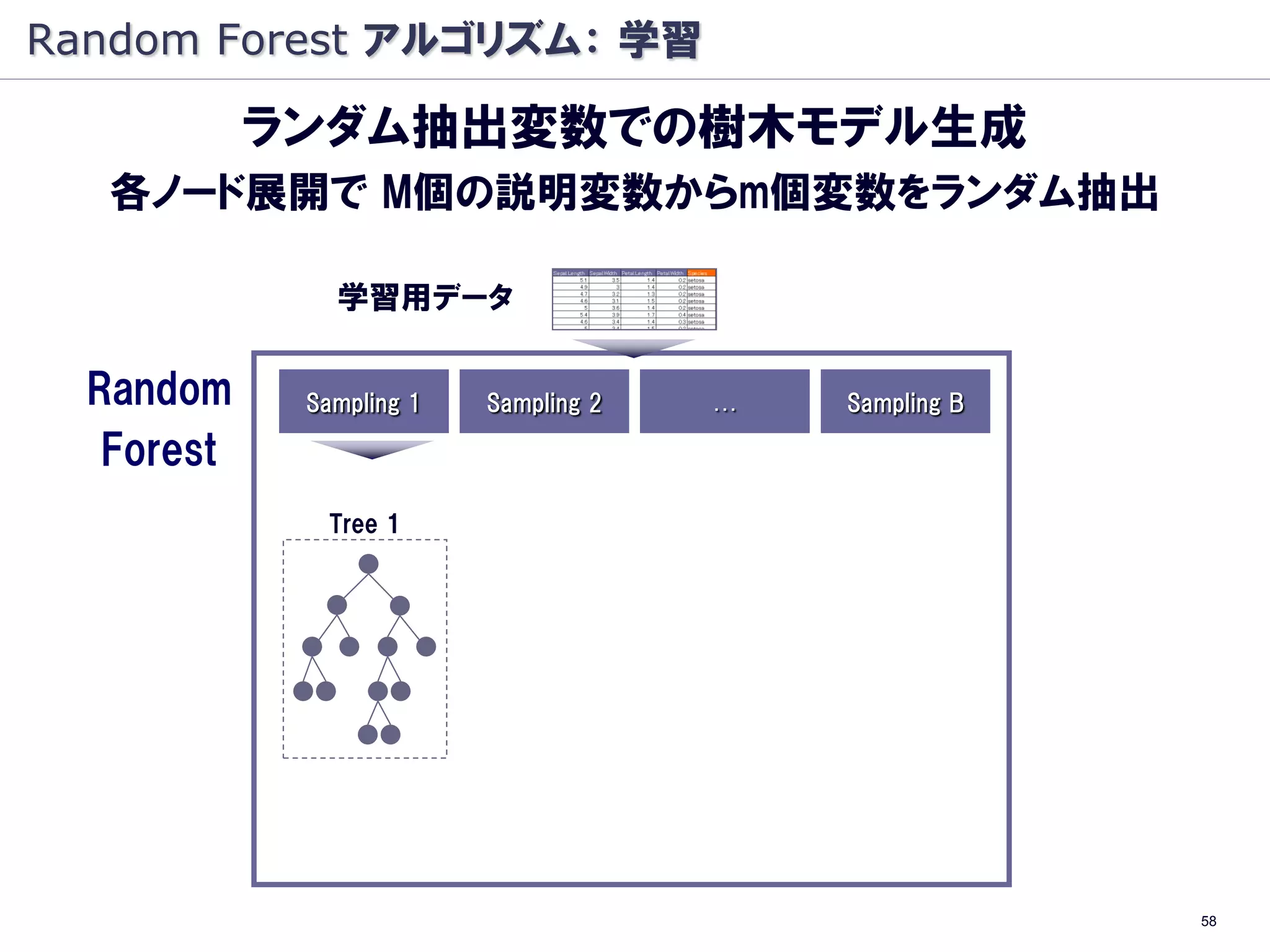
樹木モデル: 分岐基準
条件ノード A を条件ノードALとARに分けるとき
以下のΔIを最大化する分割を行う
Classification And Regression Trees (CART)
(Breiman et al, 1984)
分類木
Entropy
GINI係数
※ :条件ノード A で クラス k をとる確率
回帰木
尤離度(deviance)
※ :条件ノード A での目標変数 t の平均値 34
Random Forest とは
樹木モデルの集団学習により
高精度の分類・予測を行う
学習用データ
Random Sampling 1 Sampling 2 … Sampling B
Forest
Forest
Tree 1 Tree 2 … Tree B
予測対象
Result 1 Result 2 … Result B
分類・予測結果 43
44.
Random Forest とは
樹木モデルの集団学習により
高精度の分類・予測を行う
学習用データ
Random Sampling 1 Sampling 2 … Sampling B
Forest
Forest
Tree 1 Tree 2 … Tree B
予測対象
Result 1 Result 2 … Result B
分類・予測結果 44
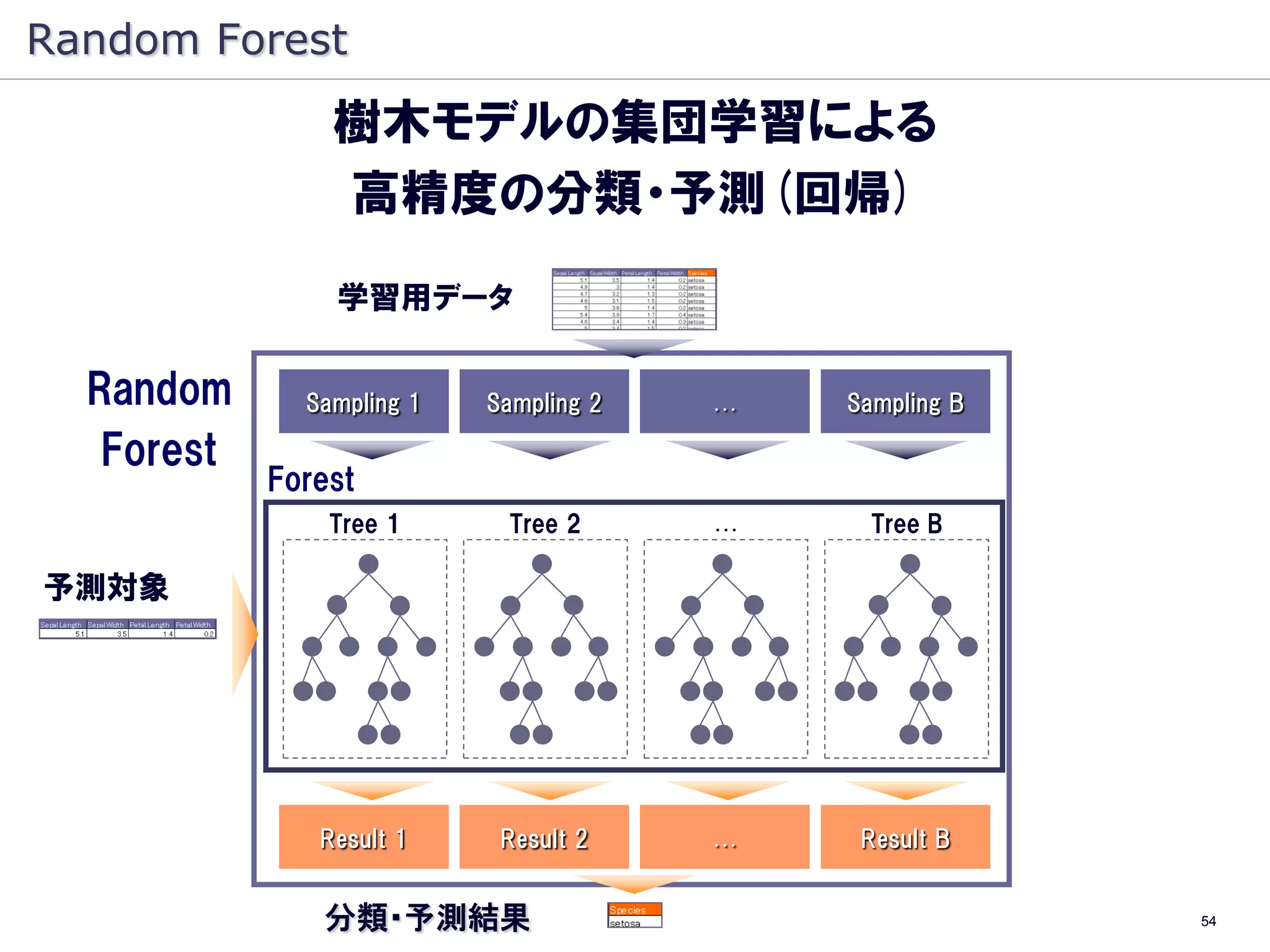
Random Forest
樹木モデルの集団学習による
高精度の分類・予測(回帰)
学習用データ
Random Sampling 1 Sampling 2 … Sampling B
Forest
Forest
Tree 1 Tree 2 … Tree B
予測対象
Result 1 Result 2 … Result B
分類・予測結果 54
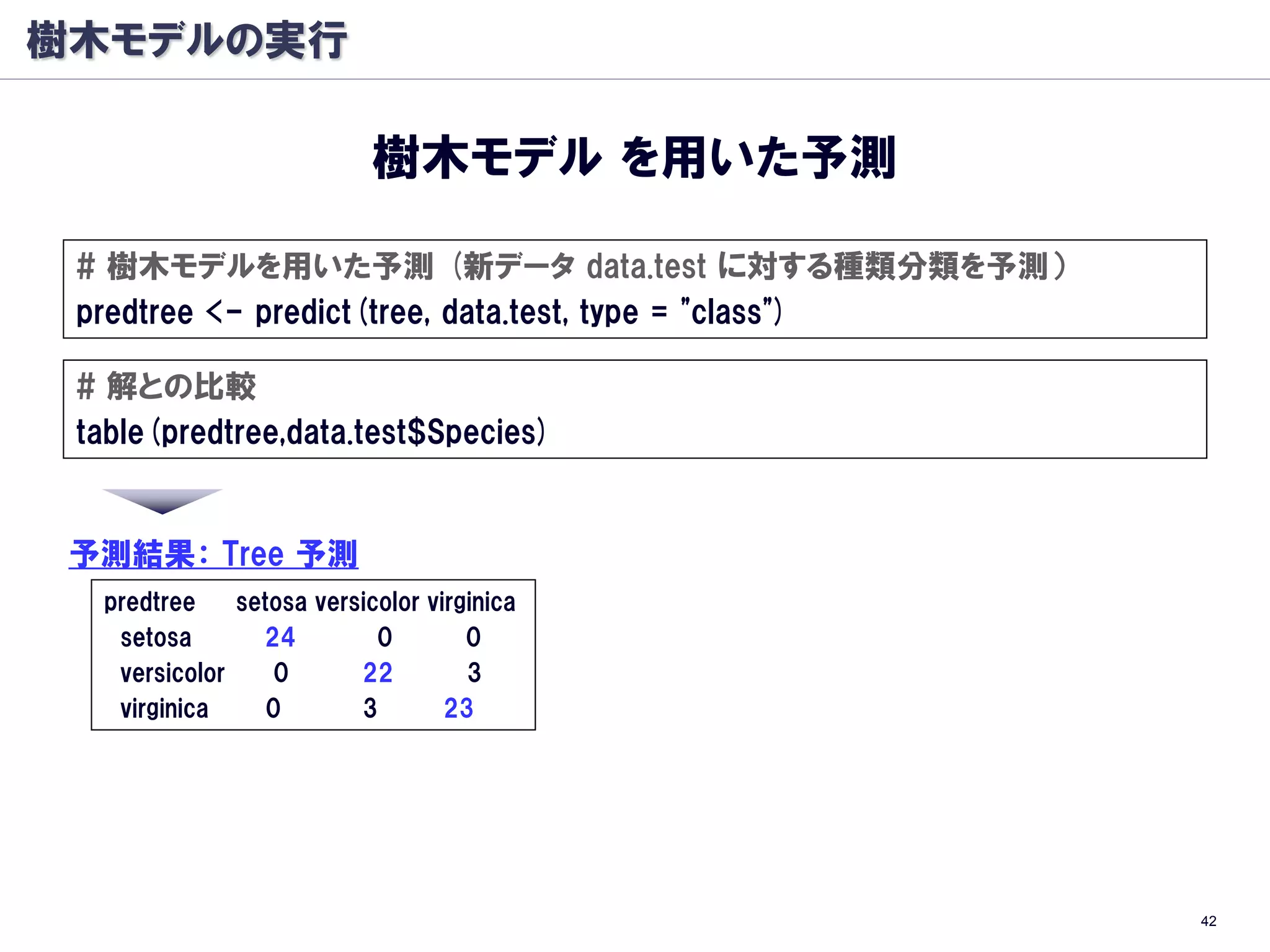
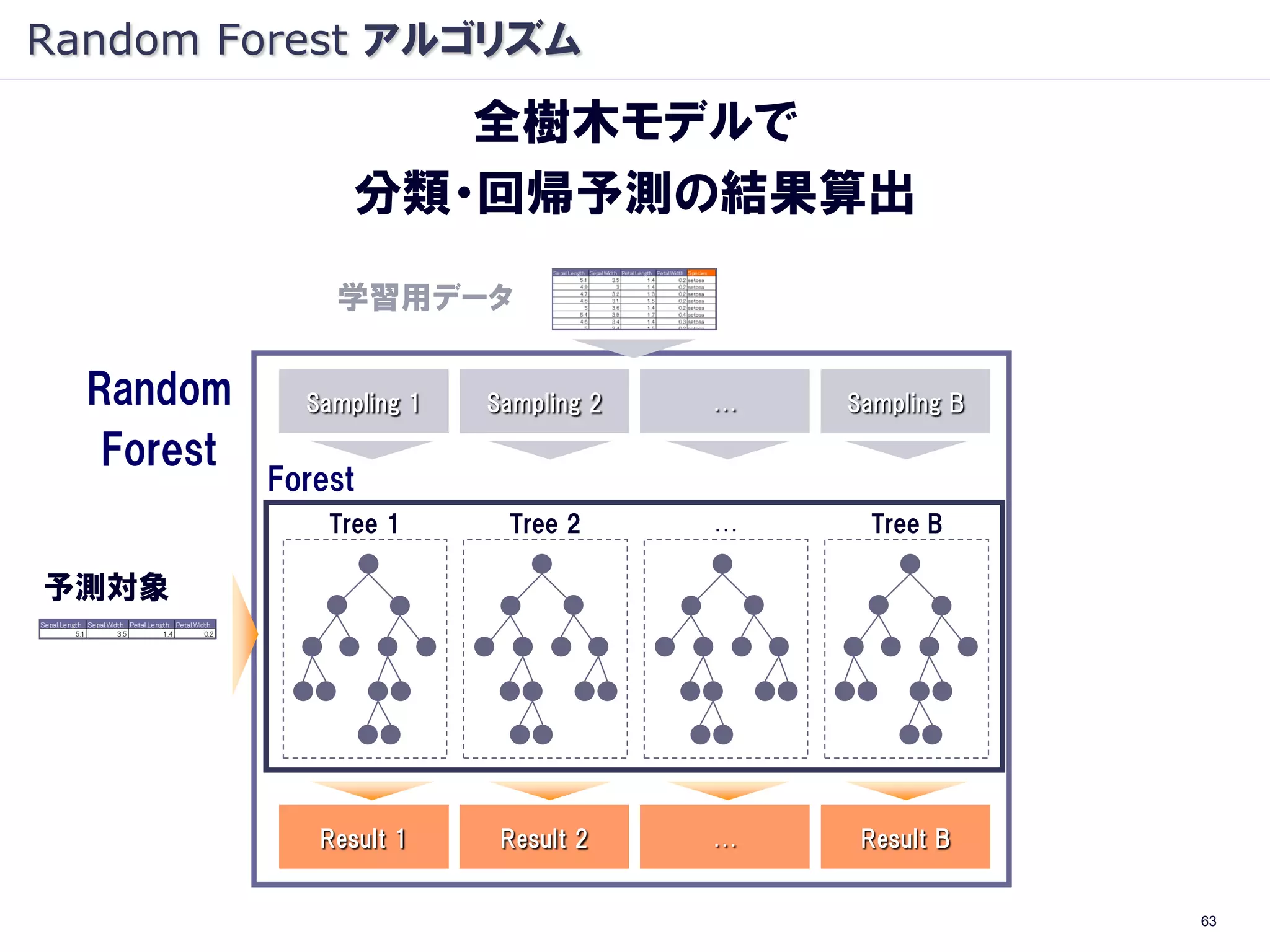
Random Forest アルゴリズム
全樹木モデルで
分類・回帰予測の結果算出
学習用データ
Random Sampling 1 Sampling 2 … Sampling B
Forest
Forest
Tree 1 Tree 2 … Tree B
予測対象
Result 1 Result 2 … Result B
63
64.
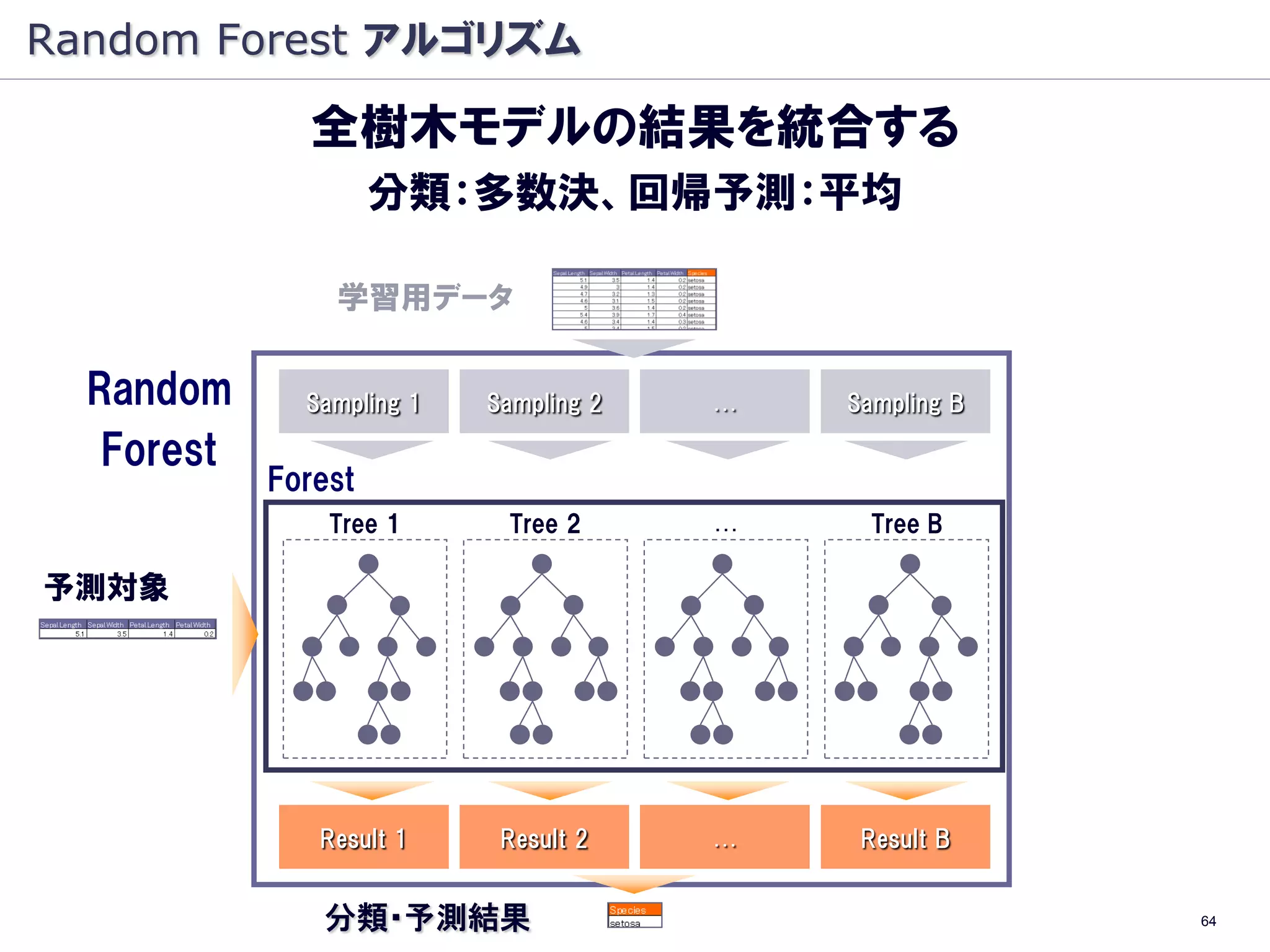
Random Forest アルゴリズム
全樹木モデルの結果を統合する
分類:多数決、回帰予測:平均
学習用データ
Random Sampling 1 Sampling 2 … Sampling B
Forest
Forest
Tree 1 Tree 2 … Tree B
予測対象
Result 1 Result 2 … Result B
分類・予測結果 64
65.
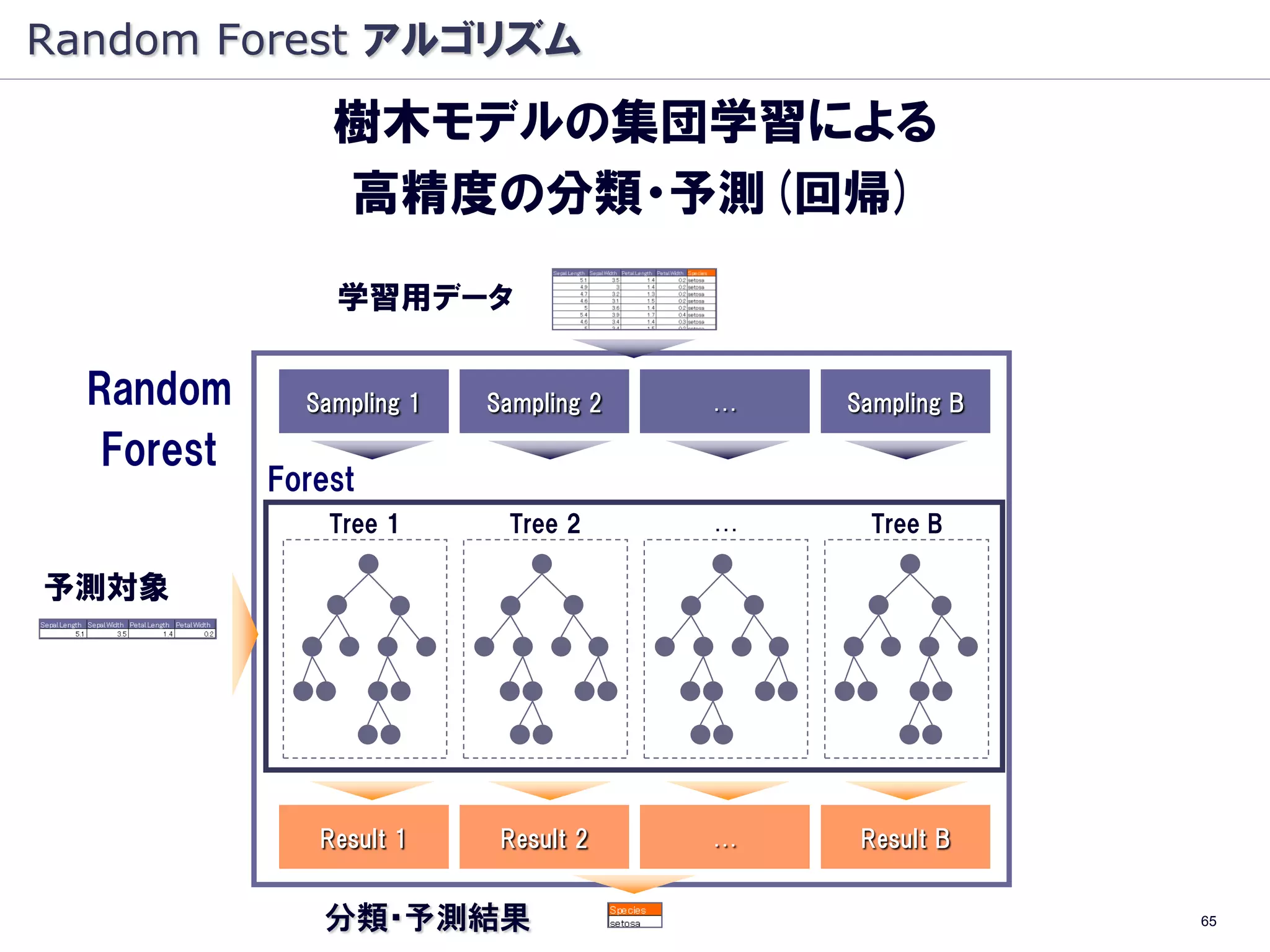
Random Forest アルゴリズム
樹木モデルの集団学習による
高精度の分類・予測(回帰)
学習用データ
Random Sampling 1 Sampling 2 … Sampling B
Forest
Forest
Tree 1 Tree 2 … Tree B
予測対象
Result 1 Result 2 … Result B
分類・予測結果 65
66.
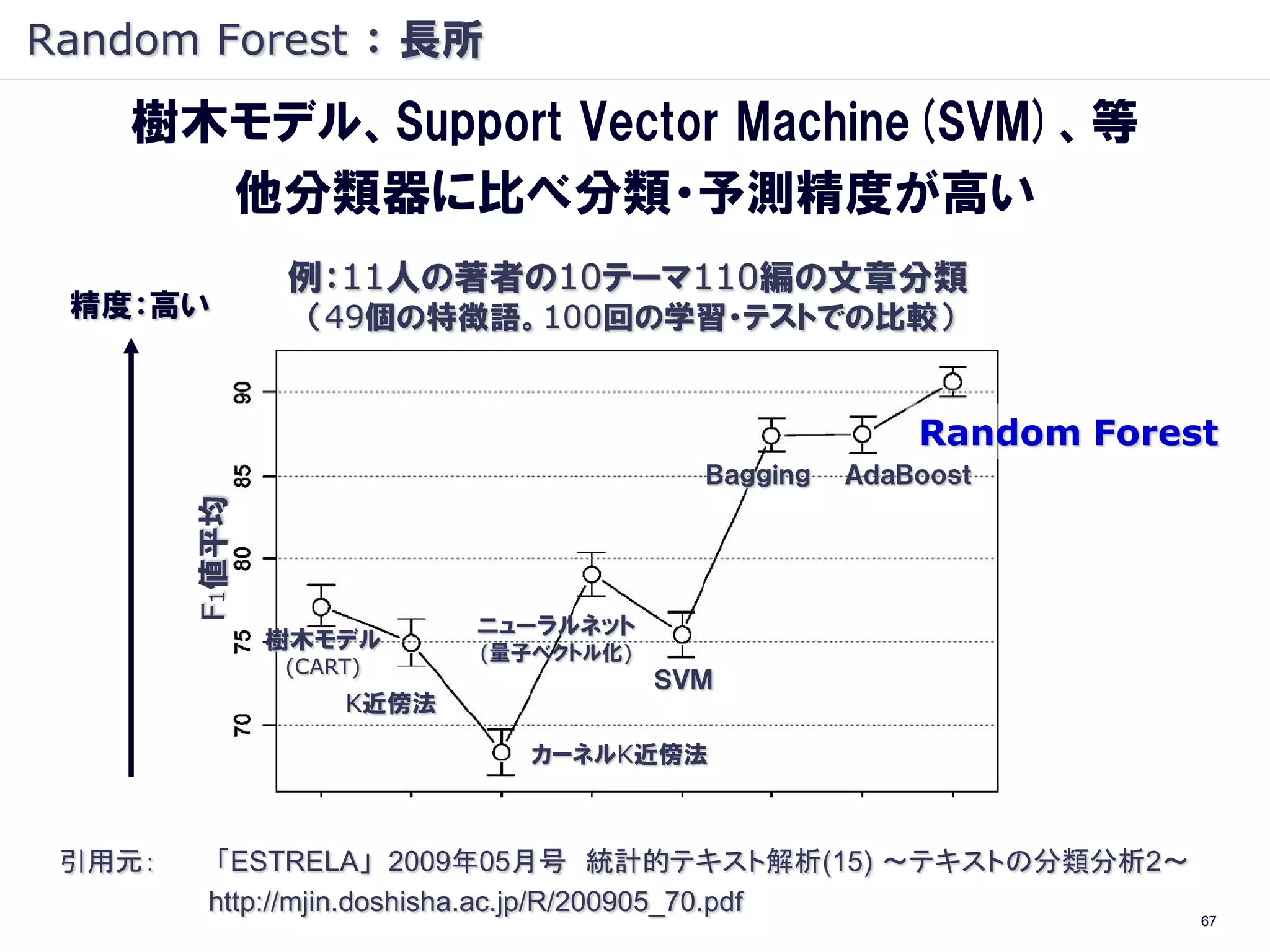
Random Forest :長所
Random Forest の
主な長所
・精度が高い
・説明変数が数百、数千でも効率的に作動
・目的変数に対する説明変数の重要度を推定
・欠損値を持つデータでも有効に動作
・個体数がアンバランスでもエラーバランスが保たれる
66
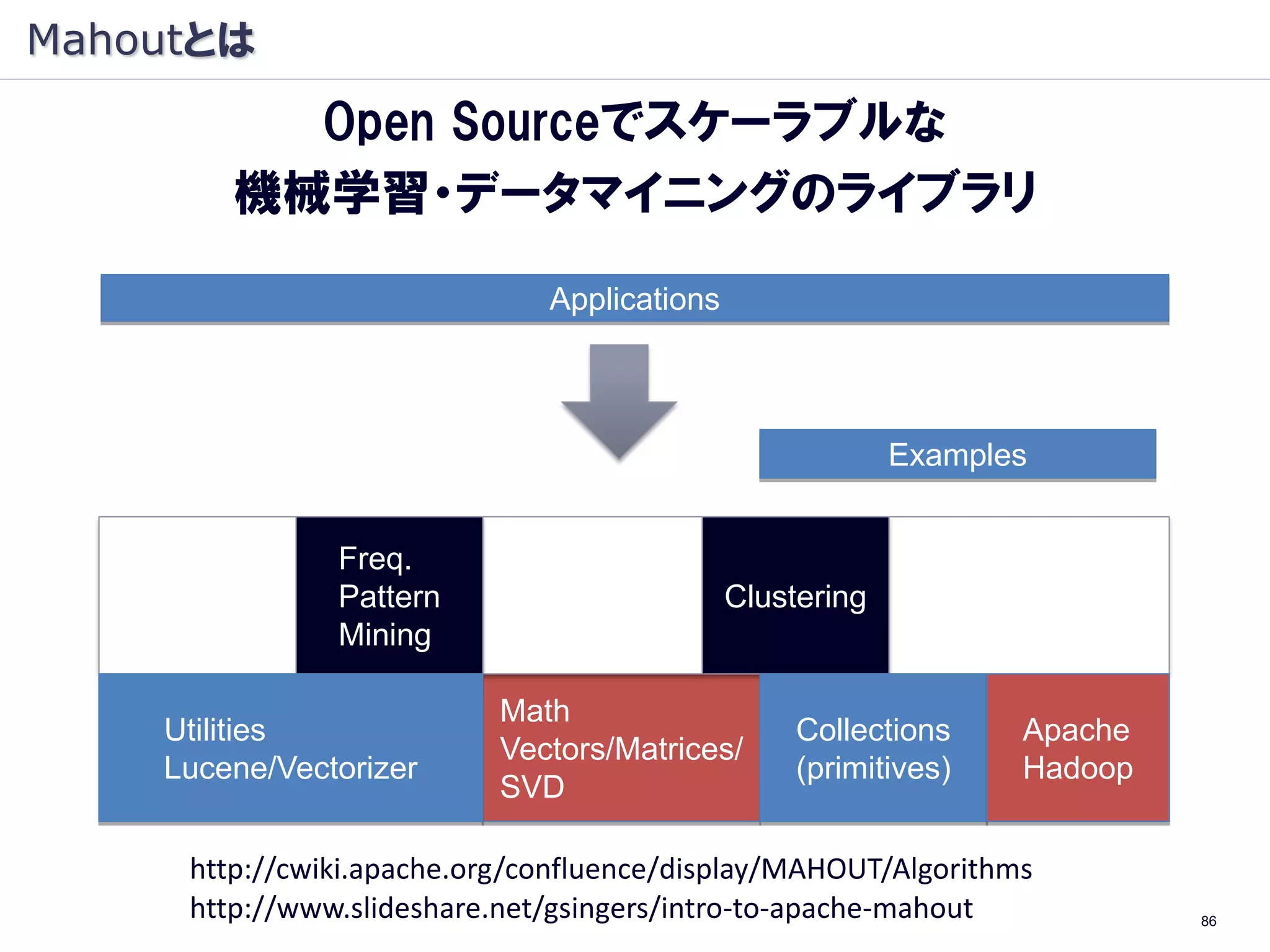
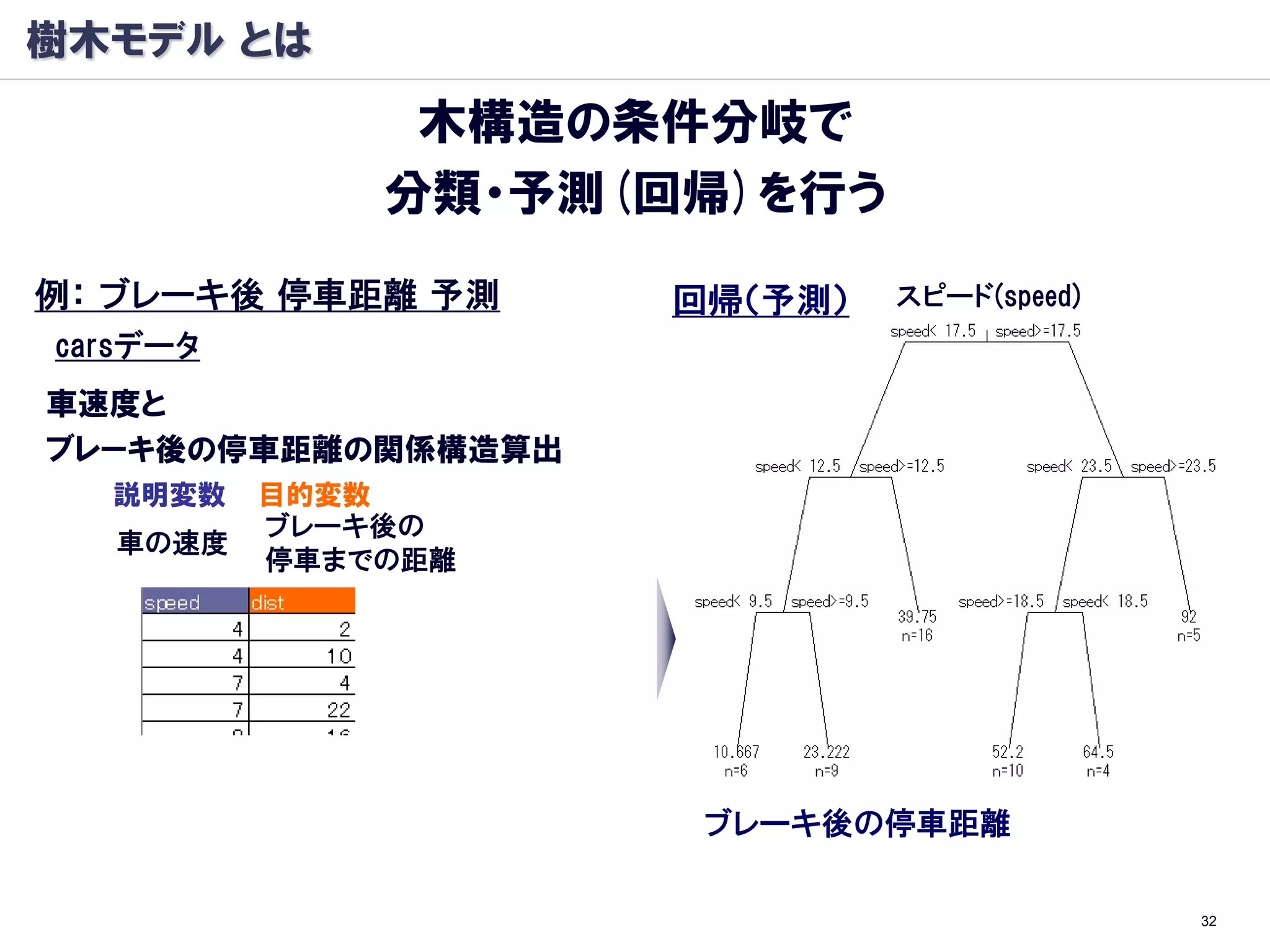
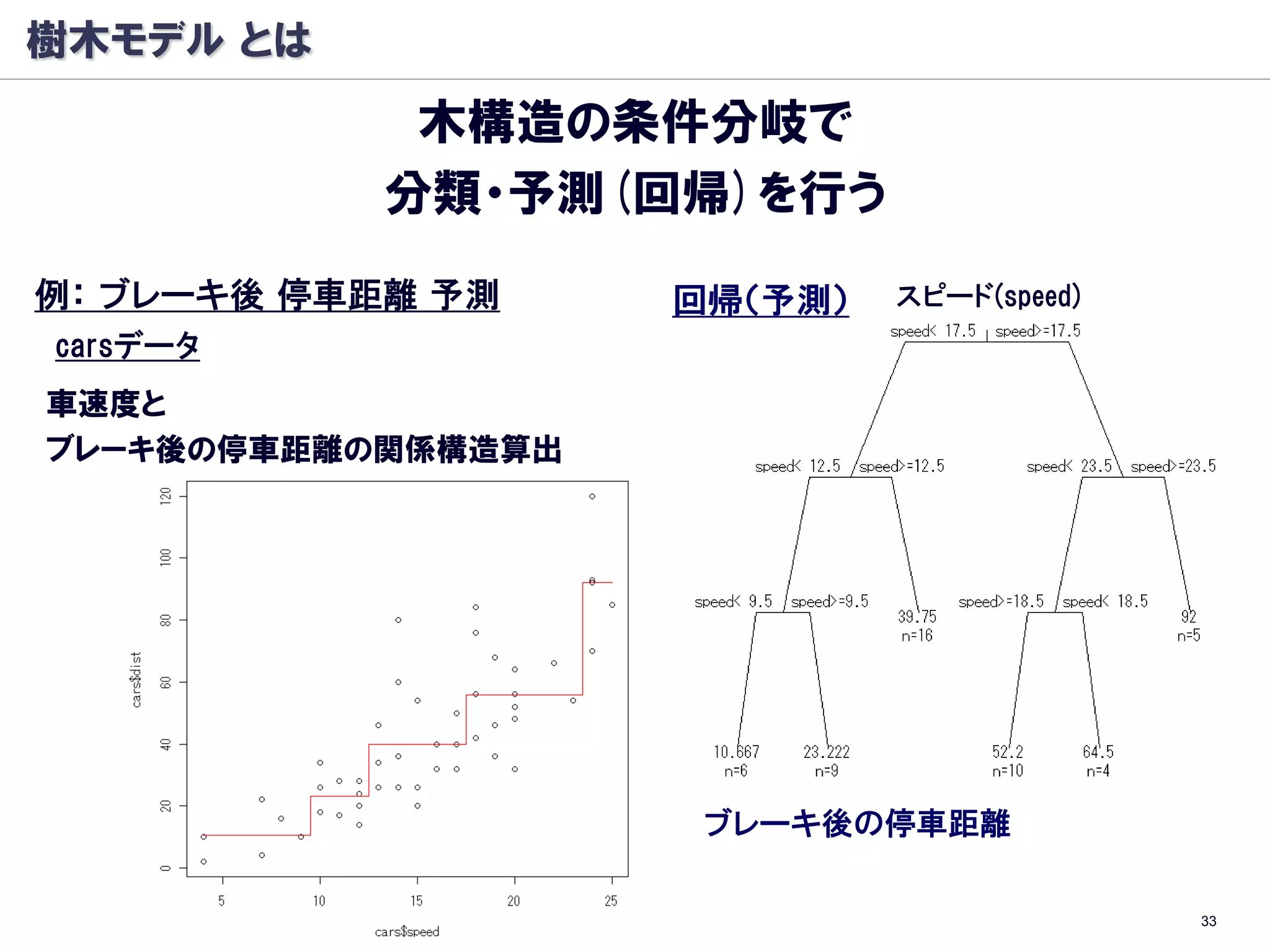
参考資料:R/CART/Random Forest
Rによるデータサイエンス Rによる統計解析
~データ解析の基礎から最新手法まで ~
http://www.slideshare.net/hamadakoichi/r-r-3201648
■CART:
L. Breiman, J. H. Friedman, R. A. Olshen and. C. J. Stone:
“Classification and Regression Trees.”, Wadsworth (1984)
■Random Forest:
L. Breiman. Random forests. Machine Learning, 45, 5–32 (2001)























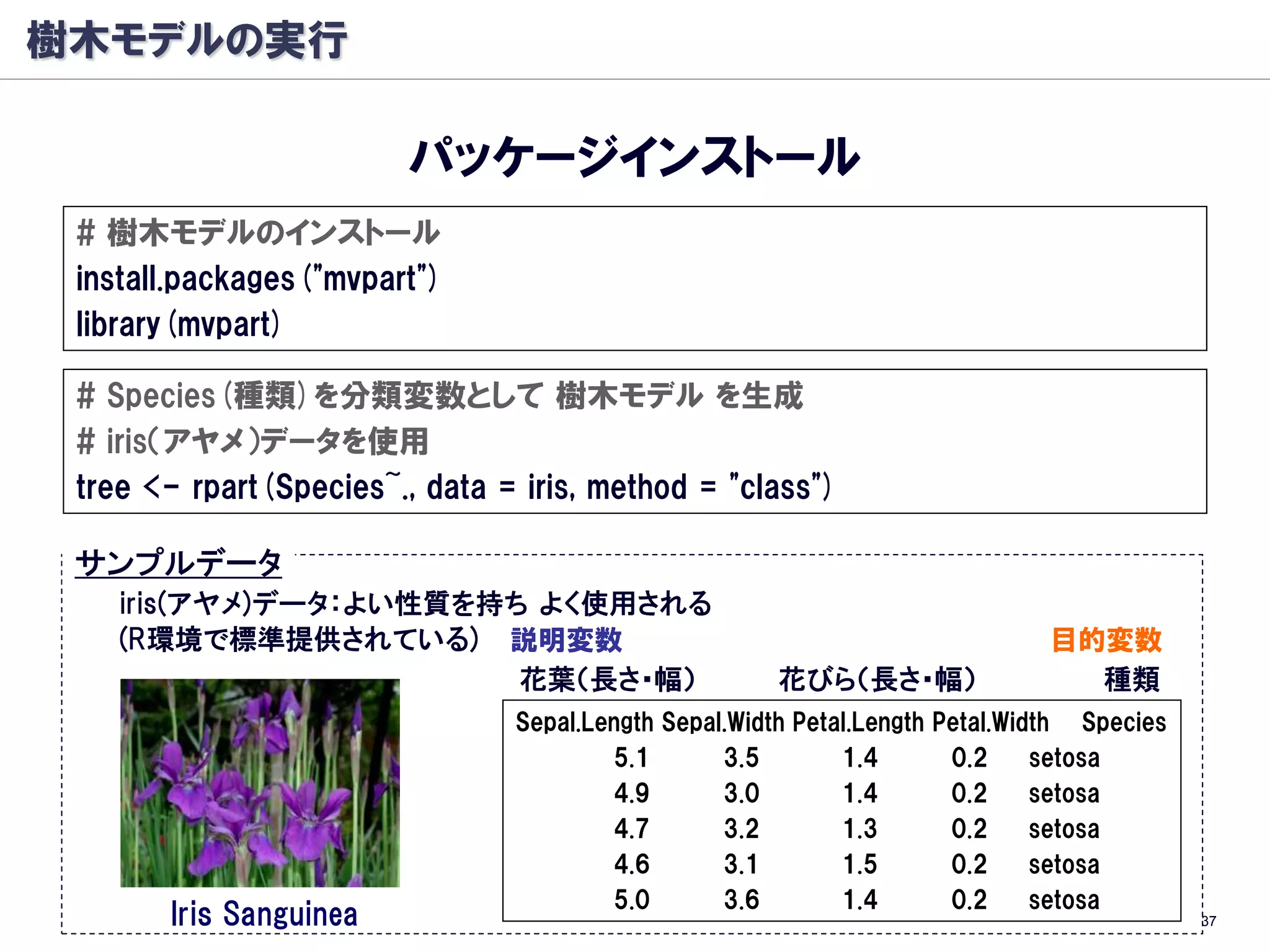

![樹木モデルの実行
学習・予測データに分け
学習用データで樹木モデル作成
# iris(アヤメ)データを使用
data <- iris
# 学習用データとテスト用データをランダムサンプリング
ndata <- nrow(data)#データ行数
ridx <- sample(ndata, ndata*0.5) #50%のランダム抽出で学習・予測データ分割
data.learn <- data[ridx,] #学習用データ作成
data.test <- data[-ridx,] #予測用データ作成
# Species(種類)を分類変数として 樹木モデル を生成
tree <- rpart(Species~., data = data.learn, method = "class")
40](https://image.slidesharecdn.com/treebasedmodelsandrandomforests-101008060919-phpapp01/75/slide-40-2048.jpg)















![Random Forest の実行
学習用・予測用データ作成
# iris(アヤメ)データを使用
data <- iris
# 学習用データとテスト用データをランダムサンプリング
ndata <- nrow(data)#データ行数
ridx <- sample(ndata, ndata*0.5) #50%のランダム抽出で学習・予測データ分割
data.learn <- data[ridx,] #学習用データ作成
data.test <- data[-ridx,] #予測用データ作成
サンプルデータ
iris(アヤメ)データ:よい性質を持ち よく使用される
(R環境で標準提供されている) 説明変数 目的変数
花葉(長さ・幅) 花びら(長さ・幅) 種類
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
5.1 3.5 1.4 0.2 setosa
4.9 3.0 1.4 0.2 setosa
4.7 3.2 1.3 0.2 setosa
4.6 3.1 1.5 0.2 setosa
5.0 3.6 1.4 0.2 setosa
Iris Sanguinea 70](https://image.slidesharecdn.com/treebasedmodelsandrandomforests-101008060919-phpapp01/75/slide-70-2048.jpg)


![Random Forest の実行
生成されたForest を用いた
高精度の予測
# Forestを用いた予測の実行
pred.forest <- predict(forest, newdata = data.test, type = "class")
# 解との比較
table(pred.forest, data.test[,5])
73](https://image.slidesharecdn.com/treebasedmodelsandrandomforests-101008060919-phpapp01/75/slide-73-2048.jpg)
![Random Forest の実行
生成されたForest を用いた
高精度の予測
# Forestを用いた予測の実行
pred.forest <- predict(forest, newdata = data.test, type = "class")
# 解との比較
table(pred.forest, data.test[,5])
予測結果: Random Forest 予測
pred.forest setosa versicolor virginica
setosa 27 0 0
versicolor 0 28 0
virginica 0 0 20
分類間違いなし
74](https://image.slidesharecdn.com/treebasedmodelsandrandomforests-101008060919-phpapp01/75/slide-74-2048.jpg)
![Random Forest の実行
生成されたForest を用いた
高精度の予測
# Forestを用いた予測の実行
pred.forest <- predict(forest, newdata = data.test, type = "class")
# 解との比較
table(pred.forest, data.test[,5])
予測結果: Random Forest 予測 ※比較参照 予測結果:分類木 (rpart)
pred.forest setosa versicolor virginica pred.dt setosa versicolor virginica
setosa 27 0 0 setosa 27 0 0
versicolor 0 28 0 versicolor 0 26 1
virginica 0 0 20 virginica 0 2 19
分類間違いなし
75](https://image.slidesharecdn.com/treebasedmodelsandrandomforests-101008060919-phpapp01/75/slide-75-2048.jpg)