



































![51
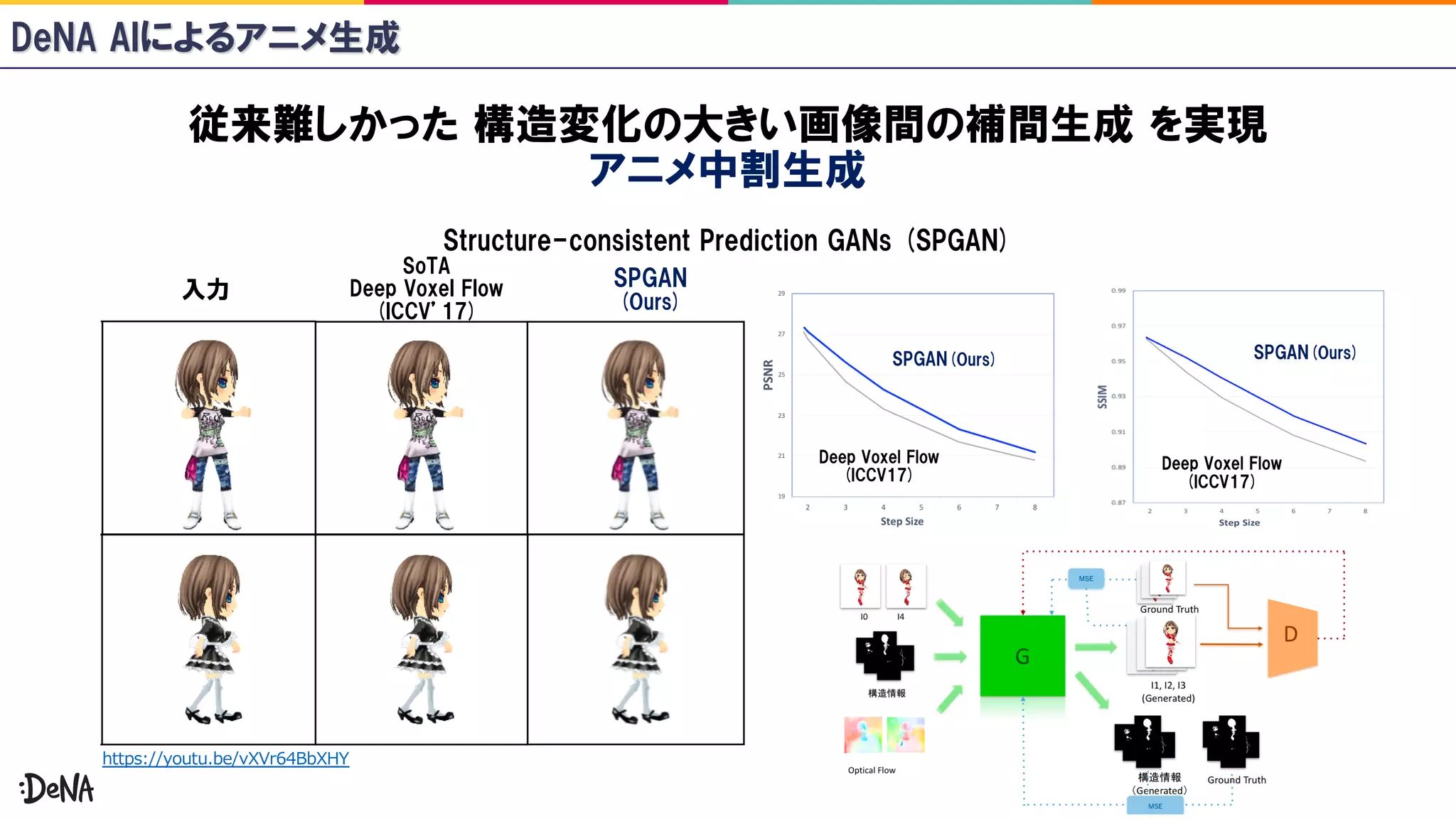
Progressive Structure-conditional GANs (PSGAN)
Full-body High-resolution Anime Generation with Progressive Structure-conditional
Generative Adversarial Networks.
Koichi Hamada, Kentaro Tachibana, Tianqi Li, Hiroto Honda, and Yusuke Uchida.
arXiv:1809.01890. In ECCV Workshop 2018.
// . 0/0 https://youtu.be/MXWm6w4E5q0
Semantic Image Synthesis with Spatially-Adaptive Normalization.
Taesung Park, Ming-Yu Liu, Ting-Chun Wang, Jun-Yan Zhu.
arXiv:1903.07291. In CVPR 2019.
SPatially-Adaptive (DE)normalization (SPADE) [GauGAN]](https://image.slidesharecdn.com/gans-icml19-190721094709/75/Generative-Adversarial-Networks-ICML-2019-51-2048.jpg)






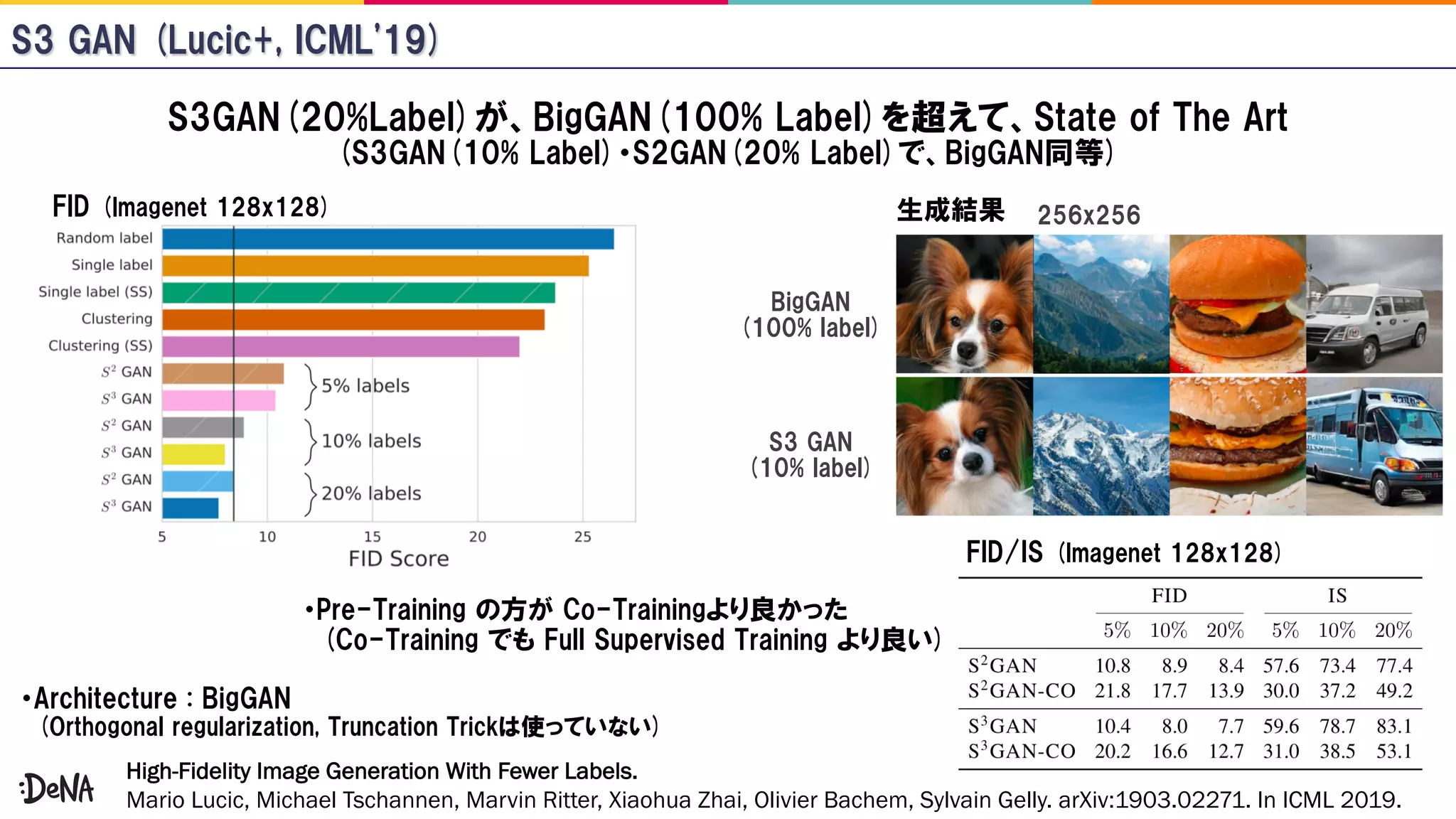



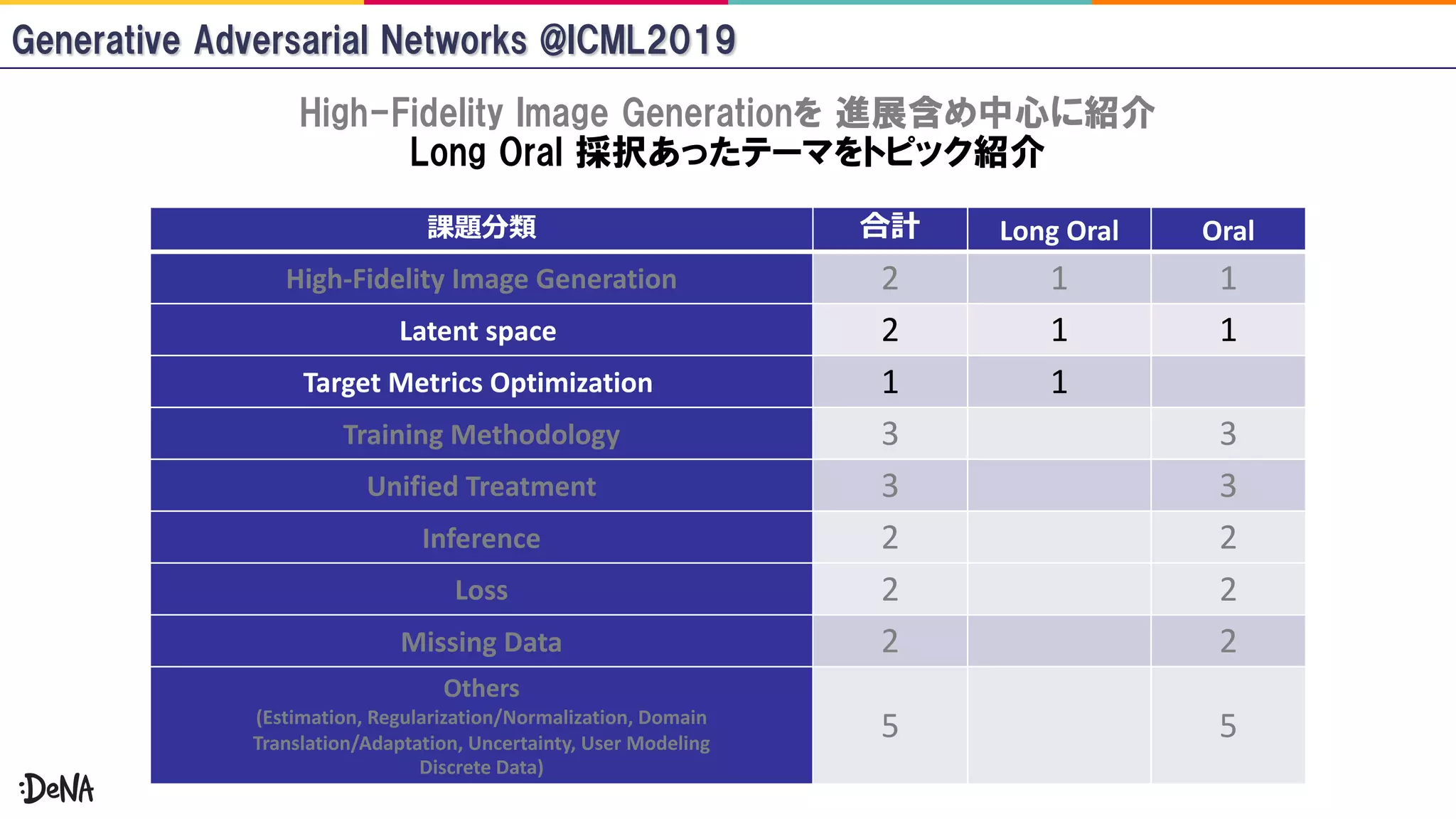
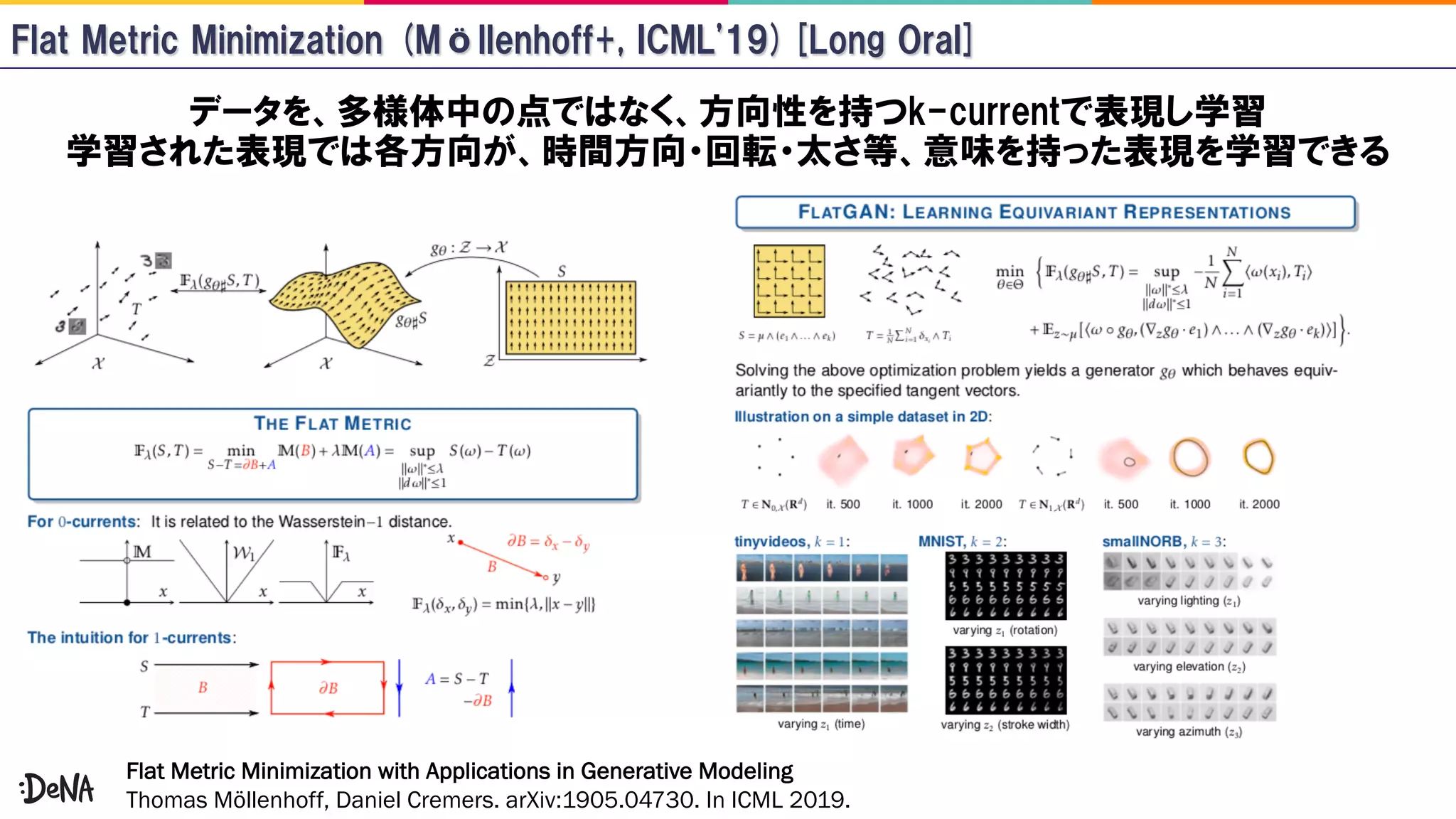
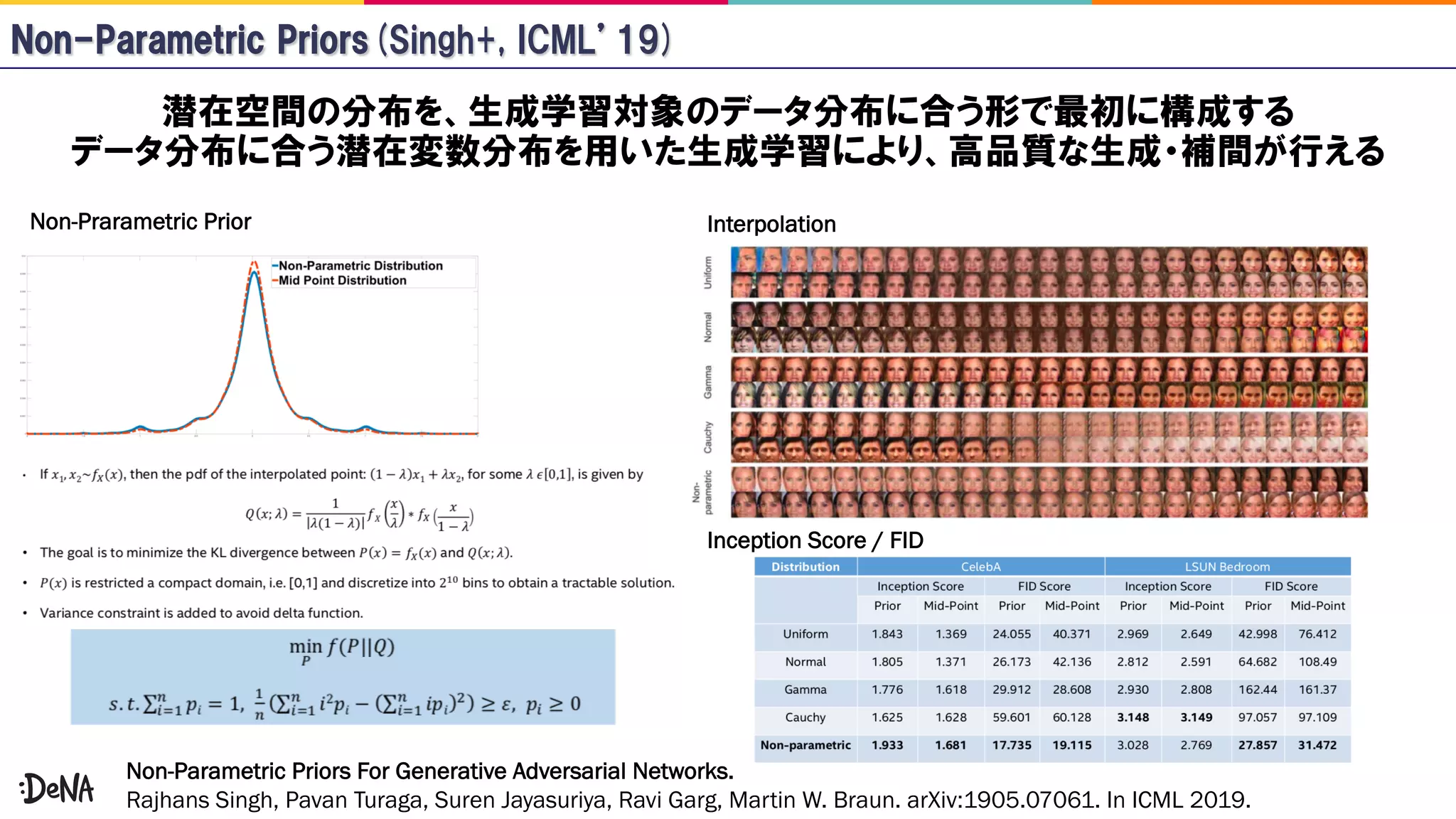
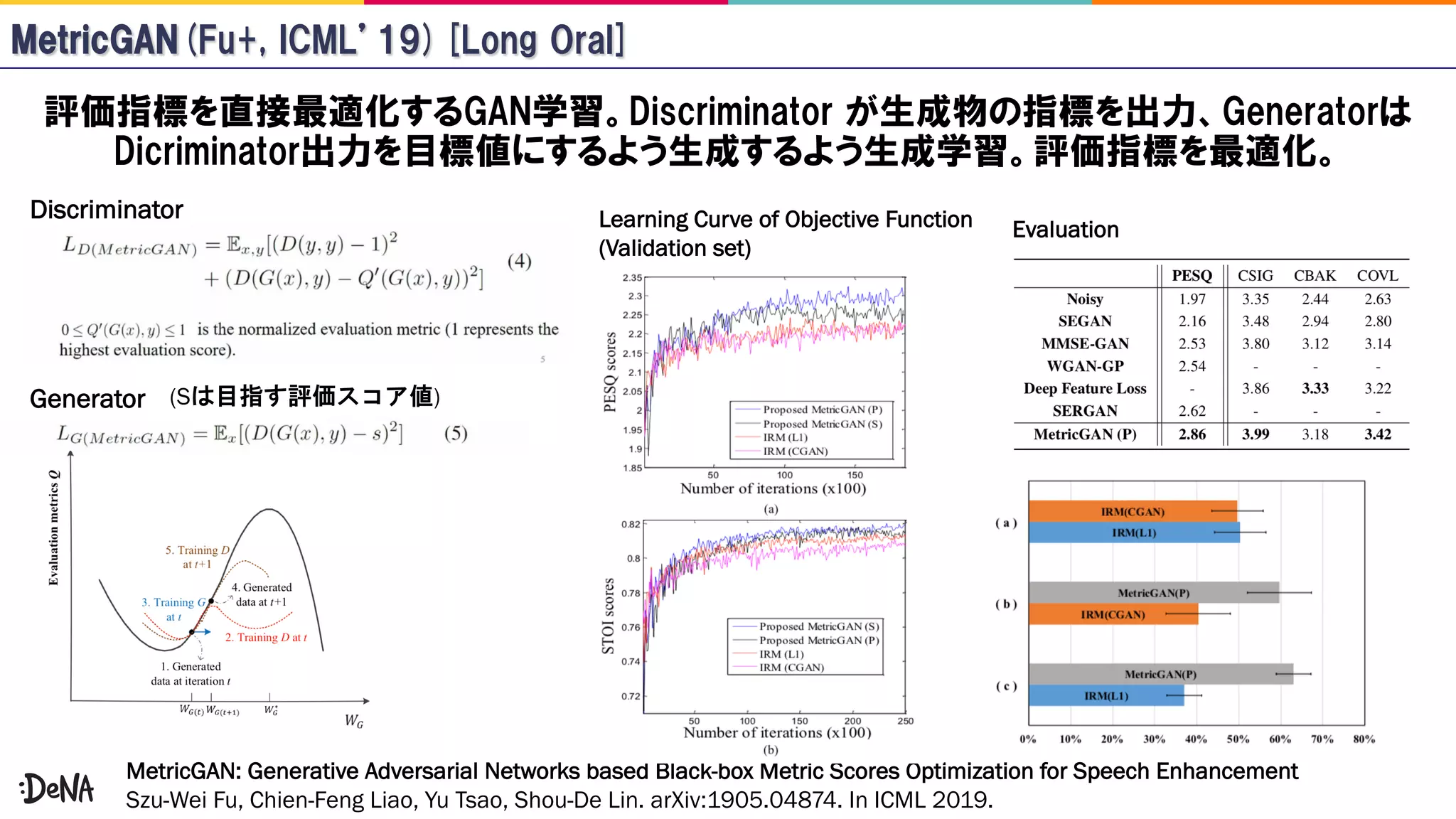
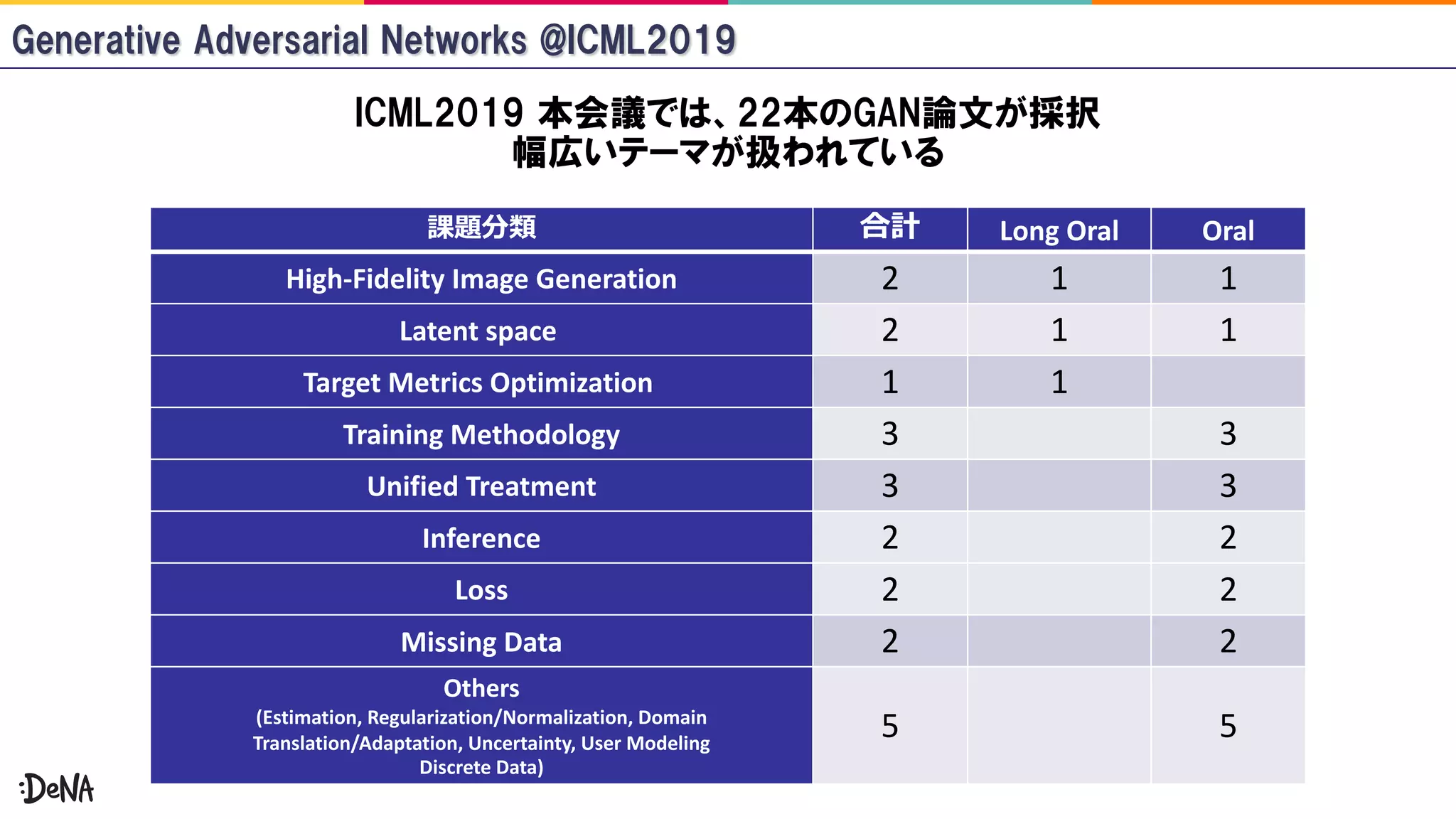
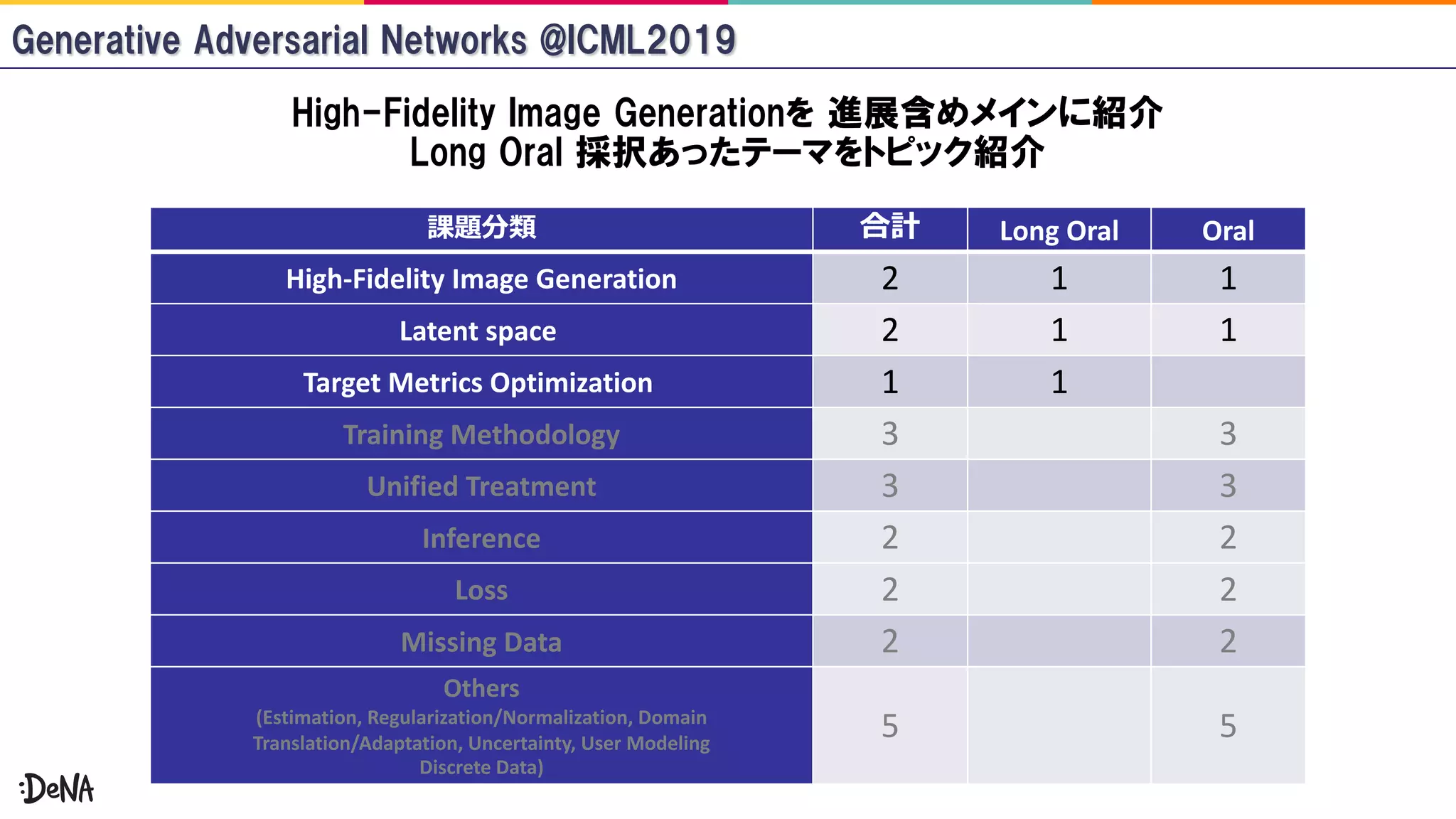




The document reviews advancements in generative adversarial networks (GANs), focusing on models such as Progressive GAN, BigGAN, and StyleGAN. It outlines methodologies for high-fidelity image generation, including various techniques like spectral normalization, self-attention, and hierarchical latent spaces. The contributions of multiple authors and papers within this field are highlighted, emphasizing ongoing improvements and complex architectures that enhance image quality.



































































