



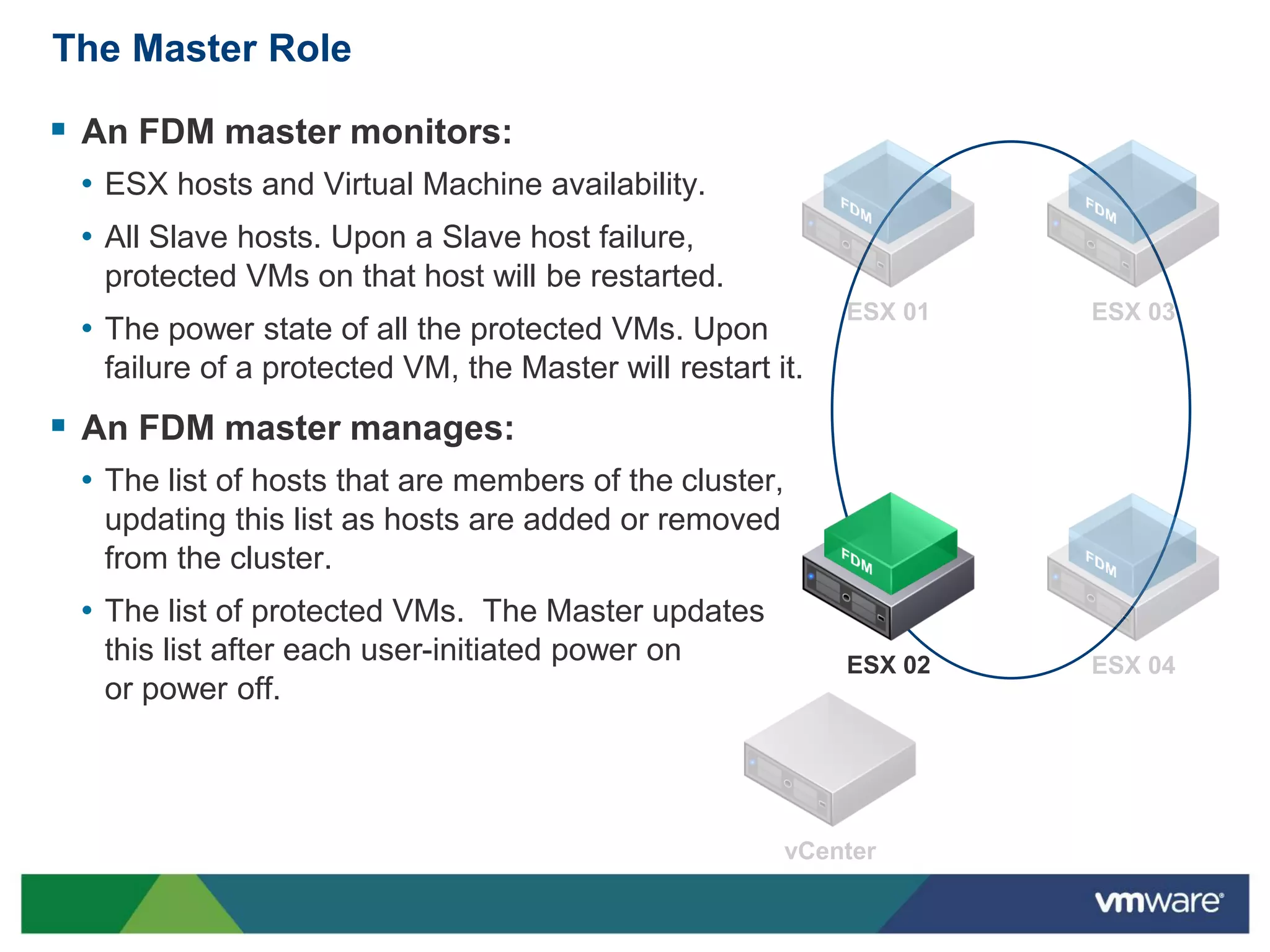
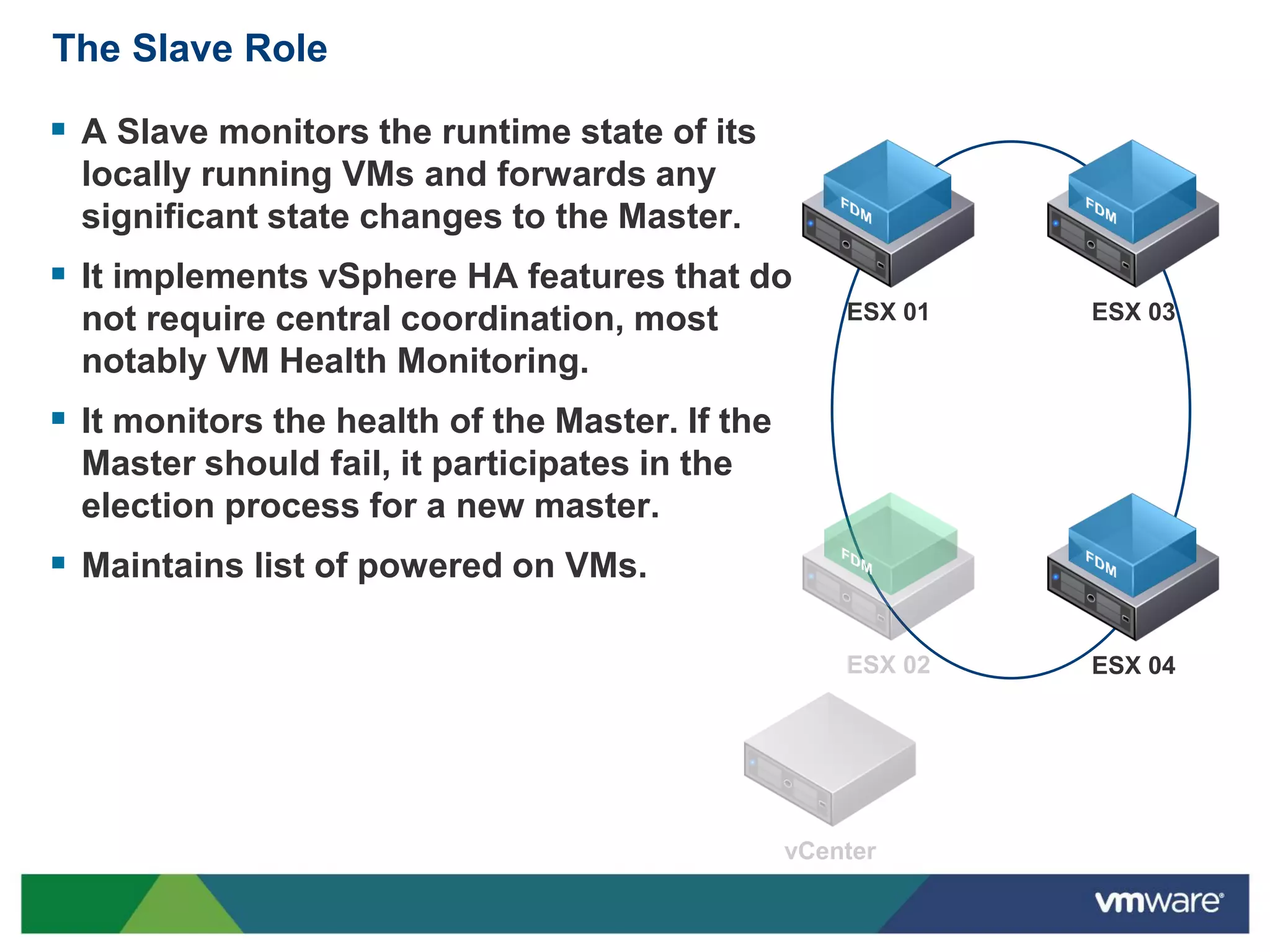
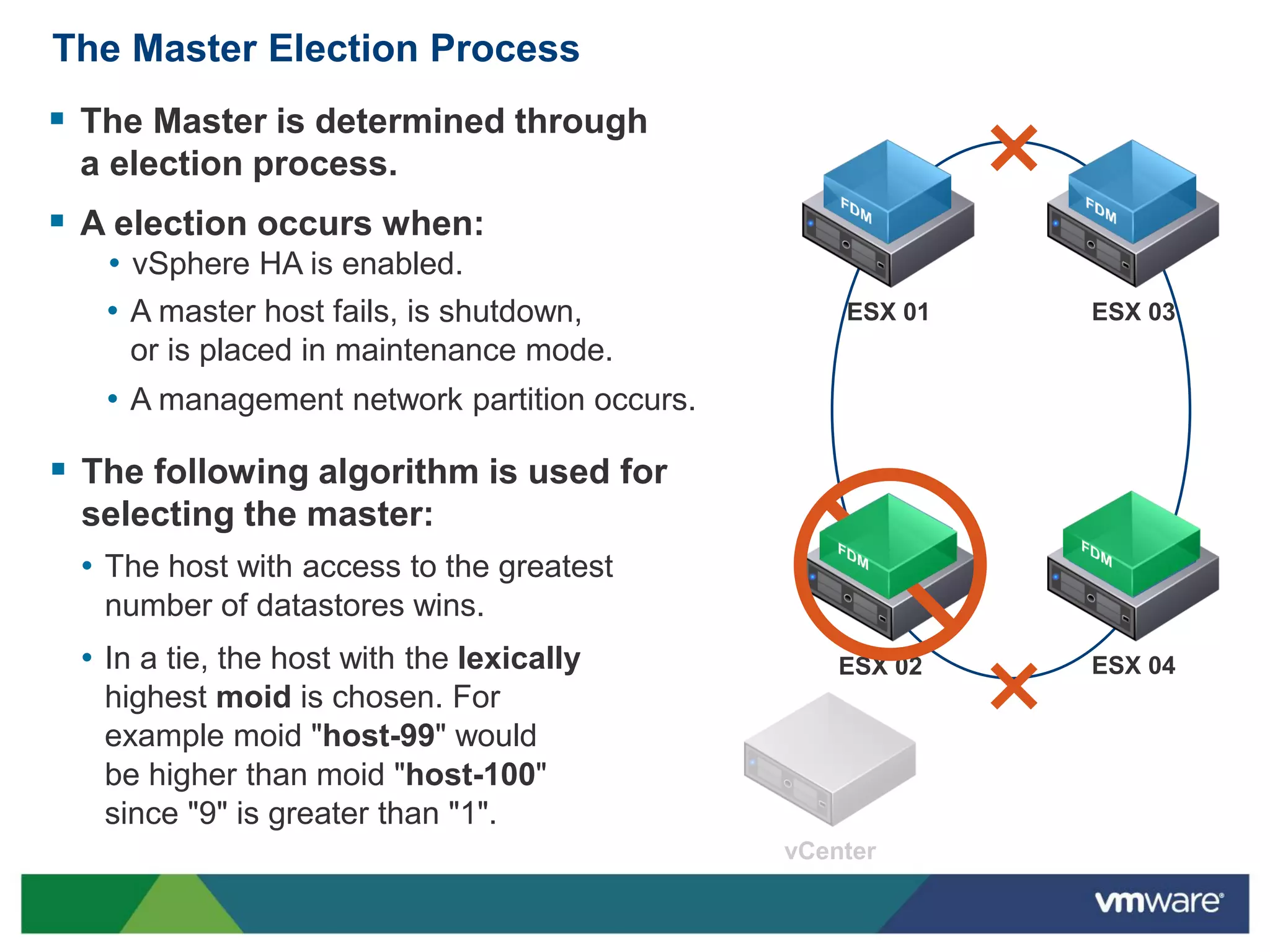
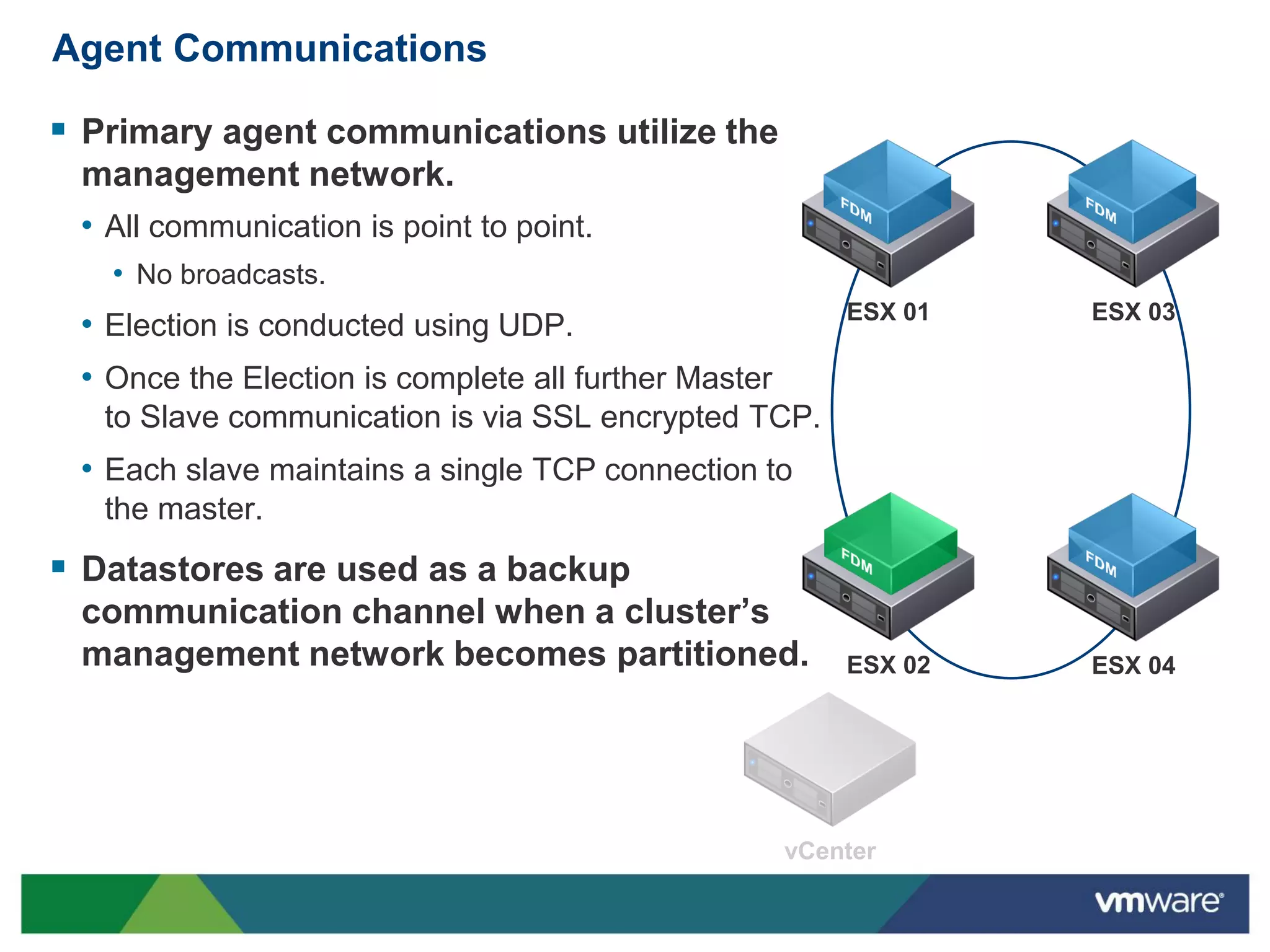
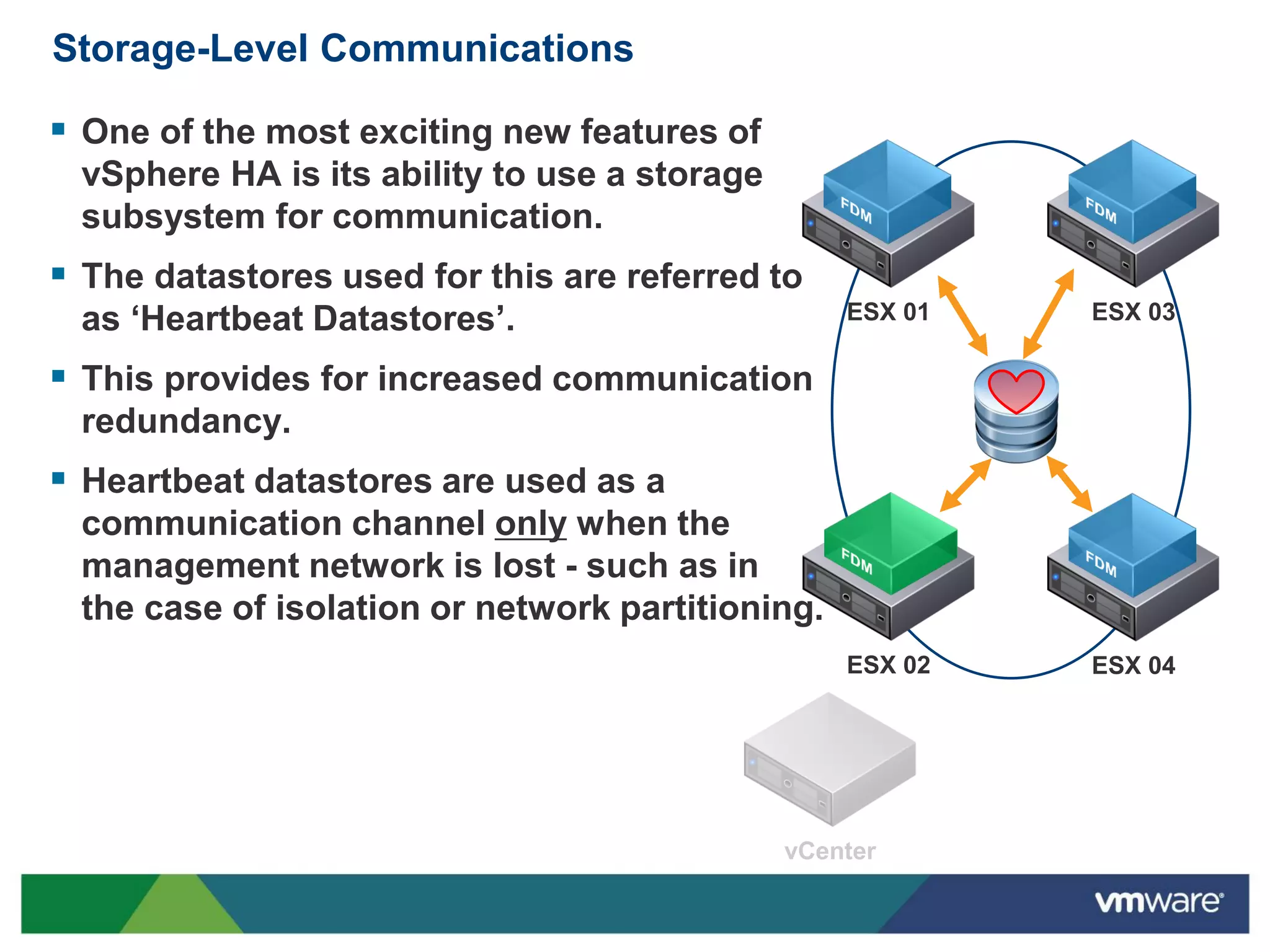
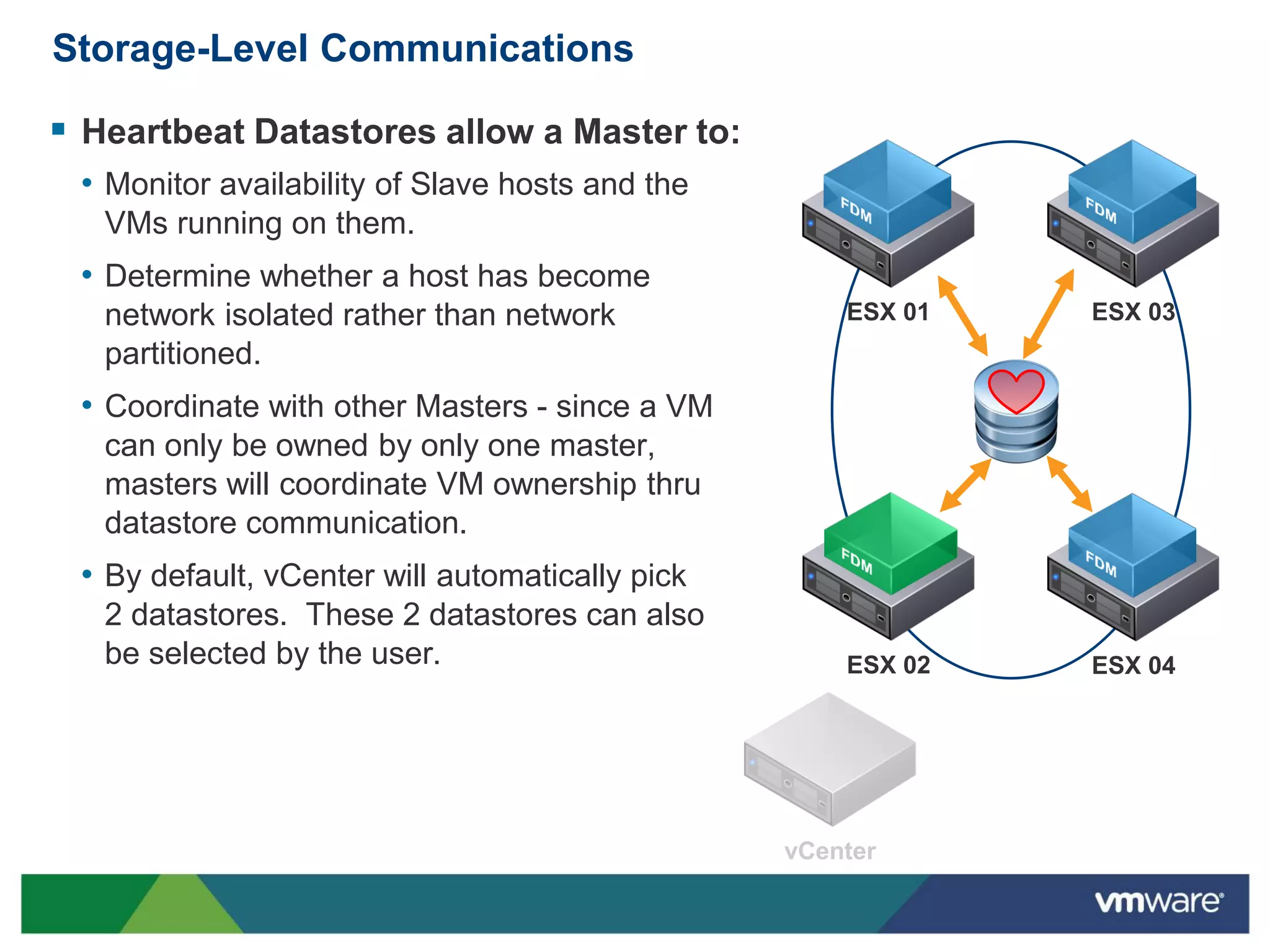
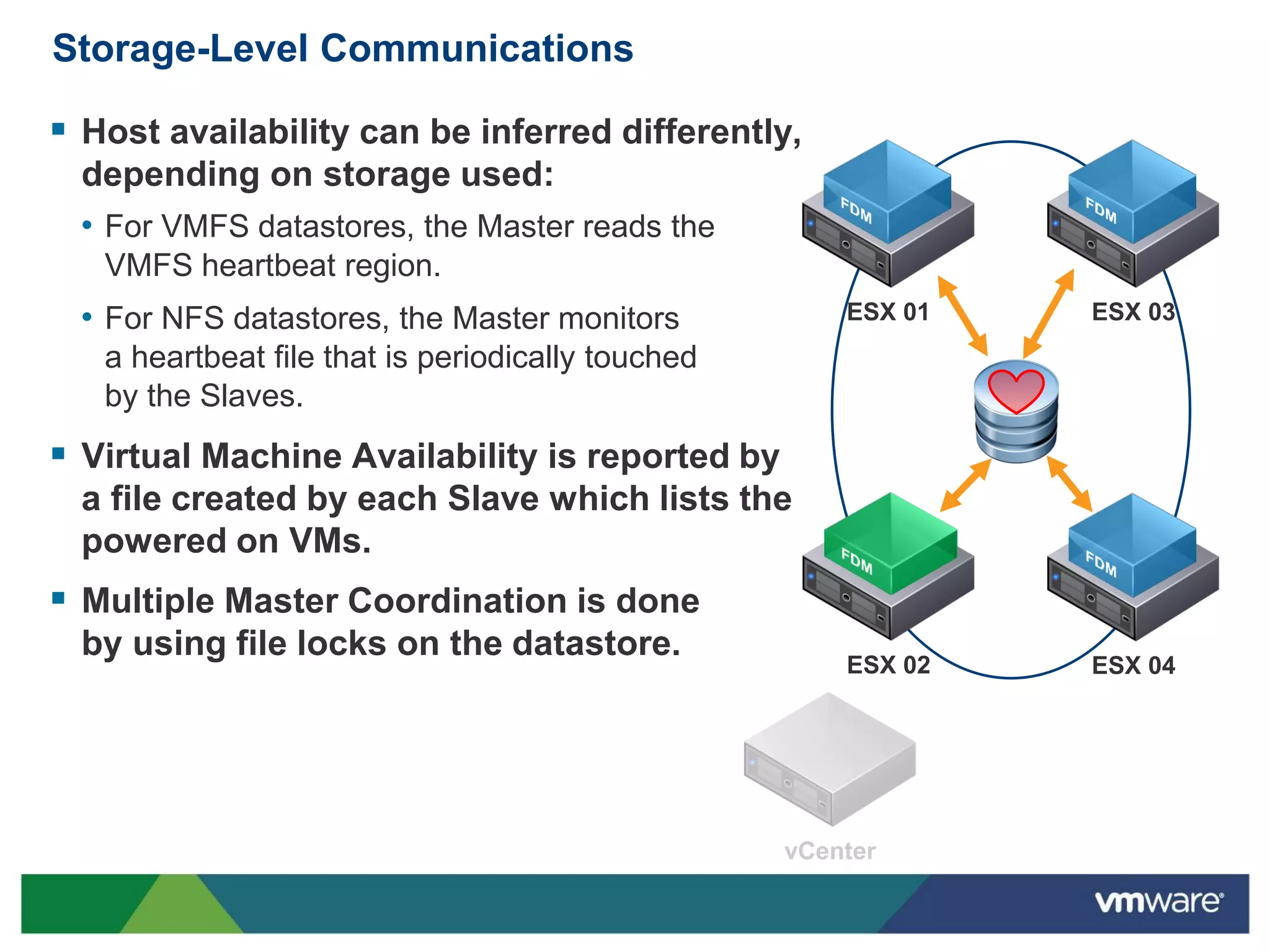




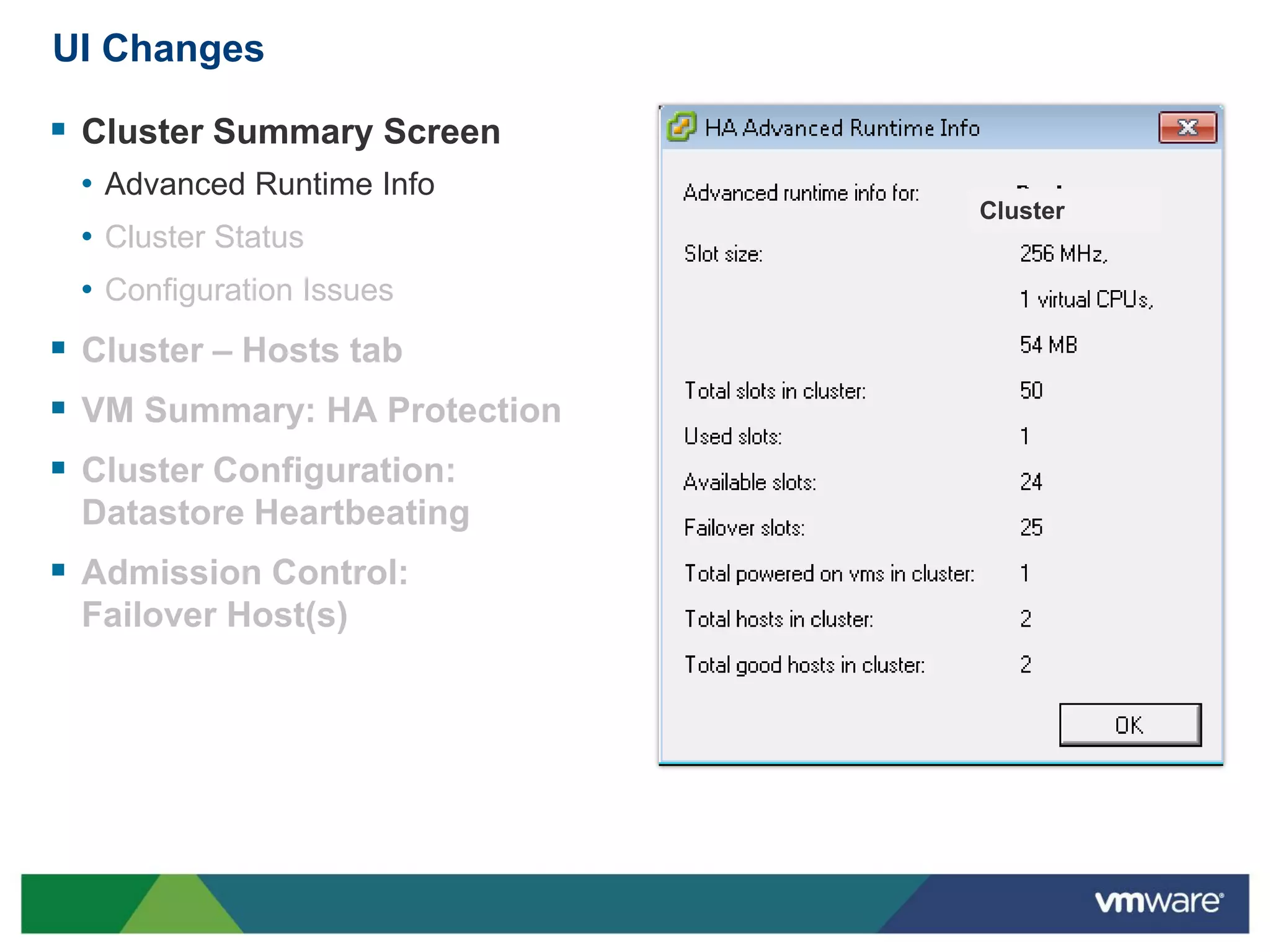
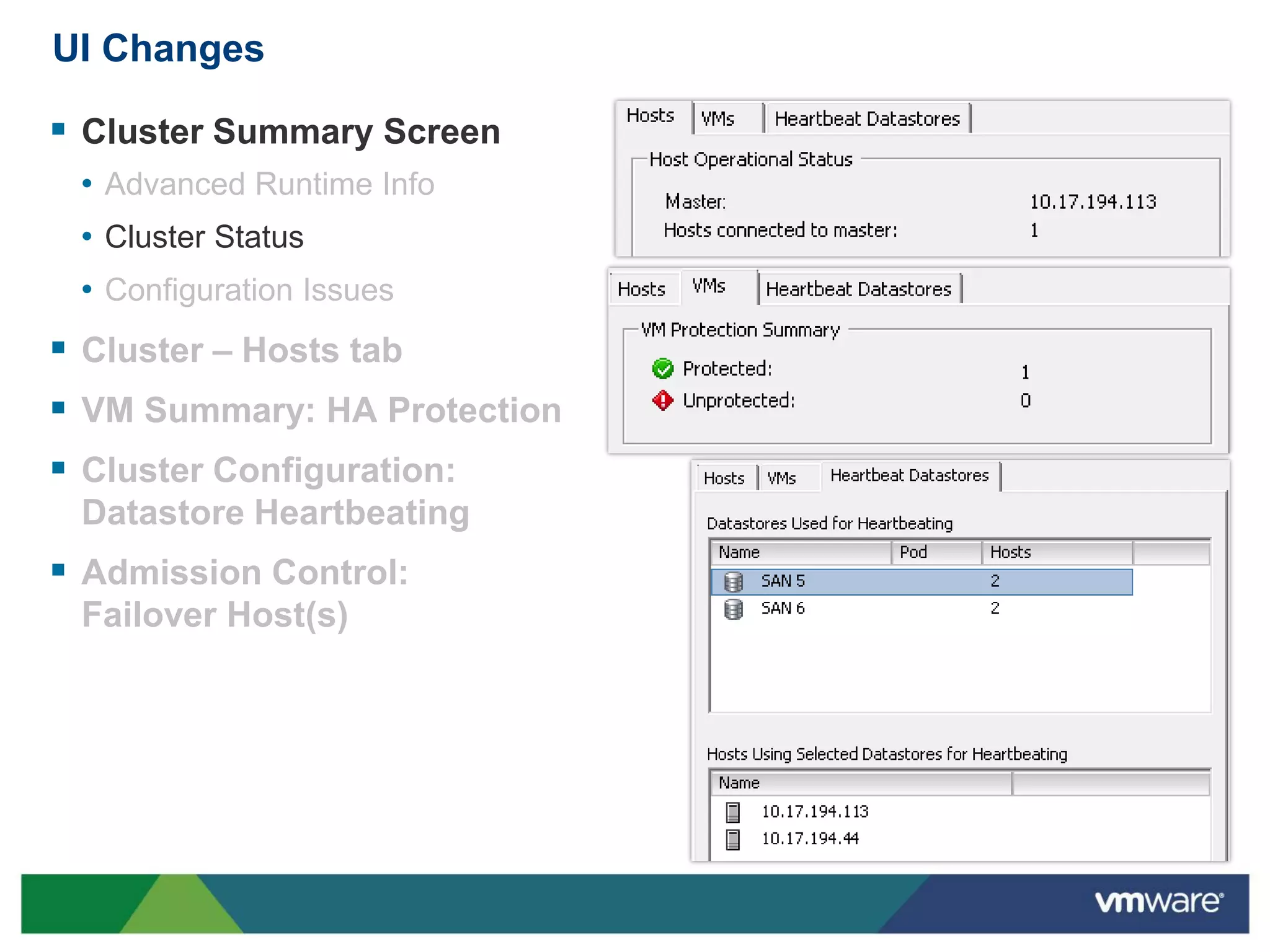
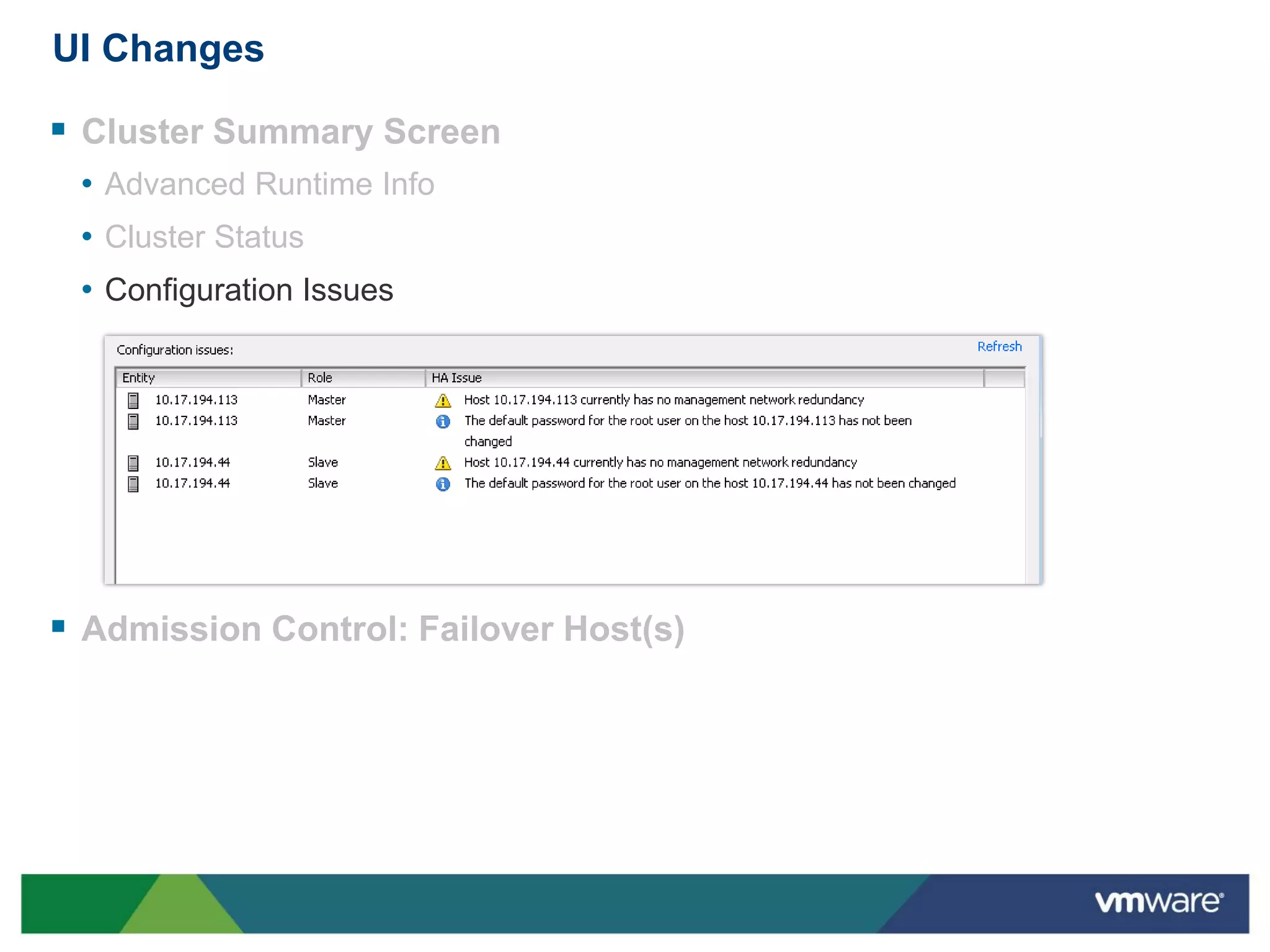
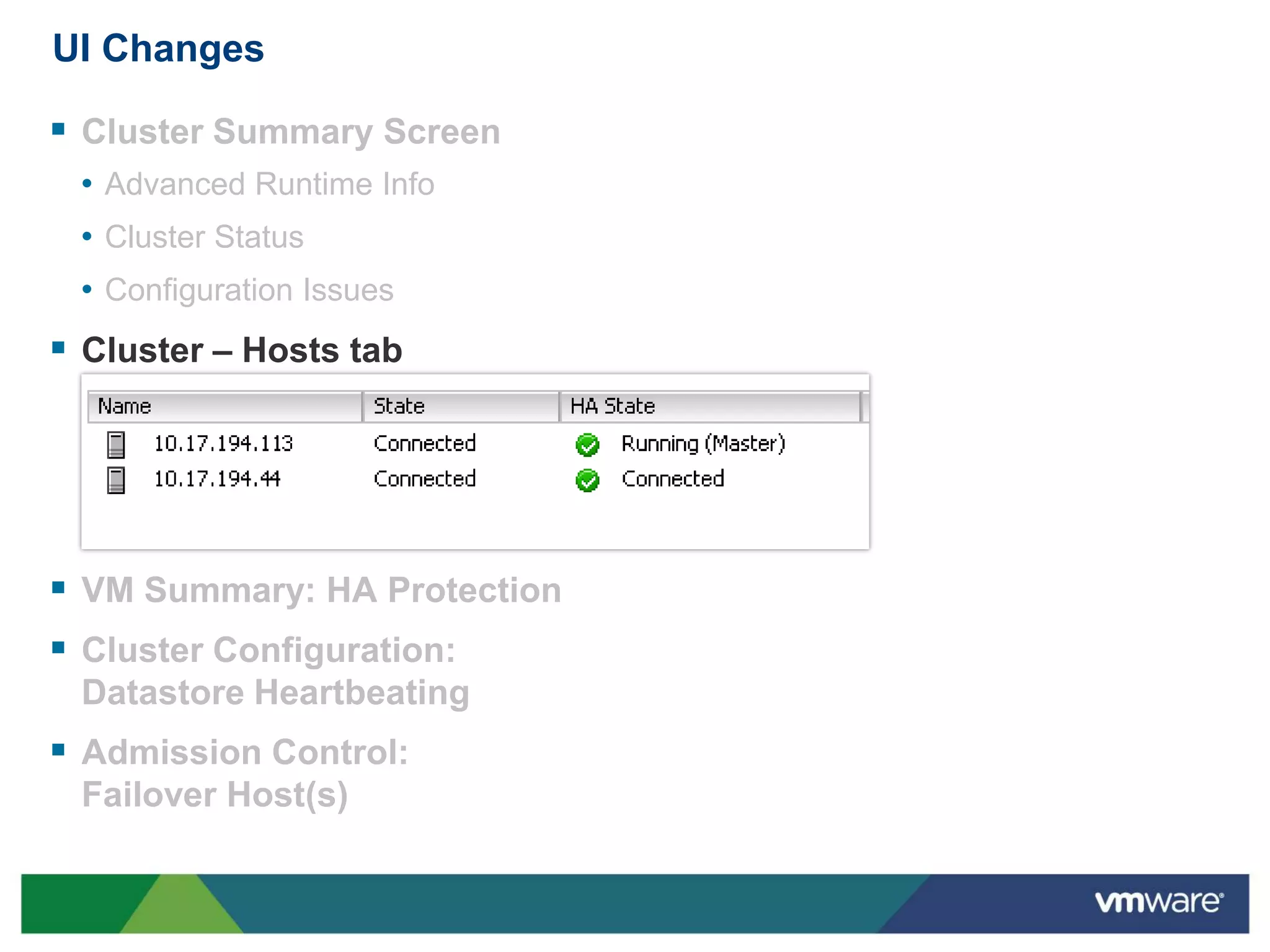
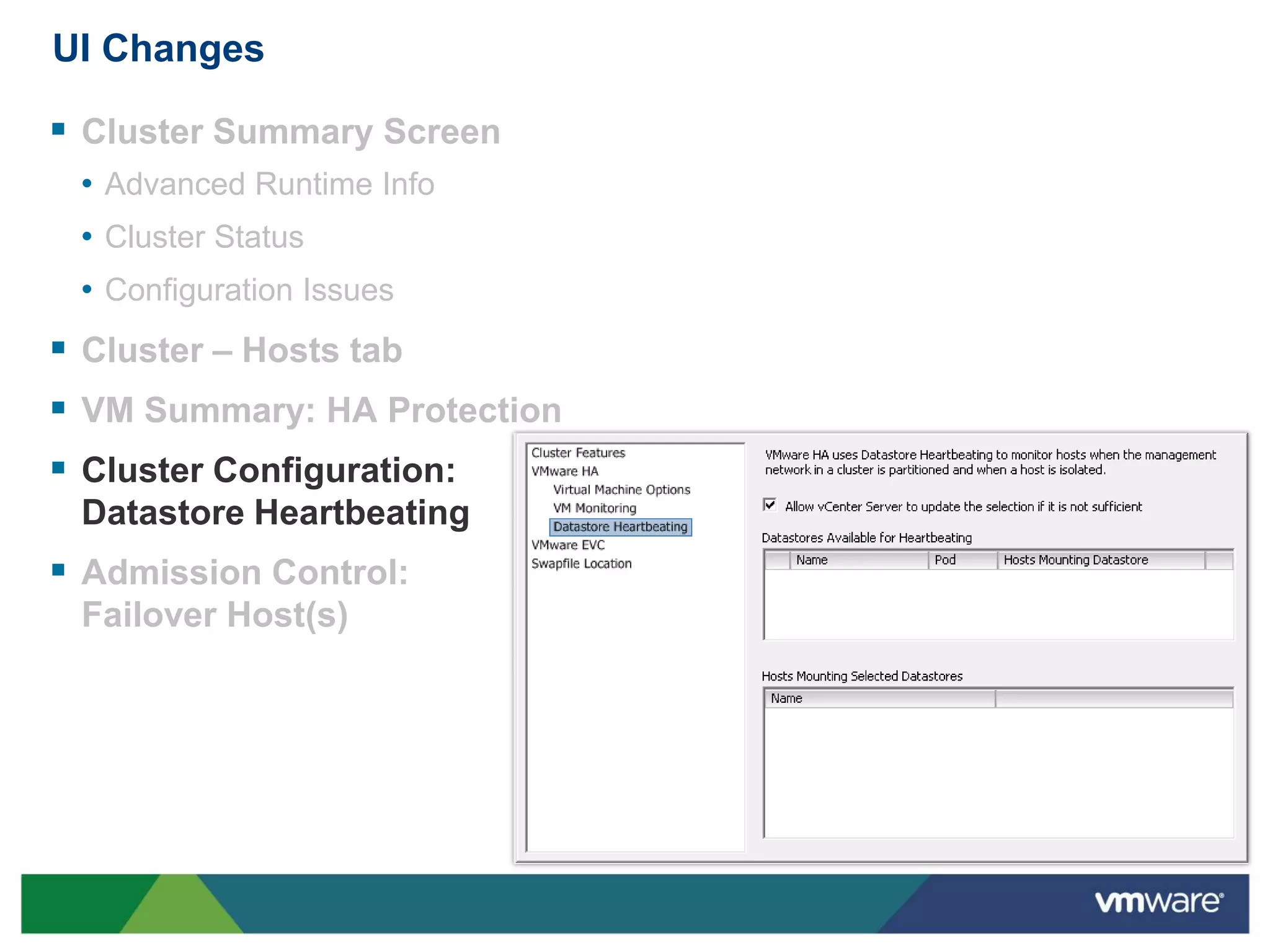
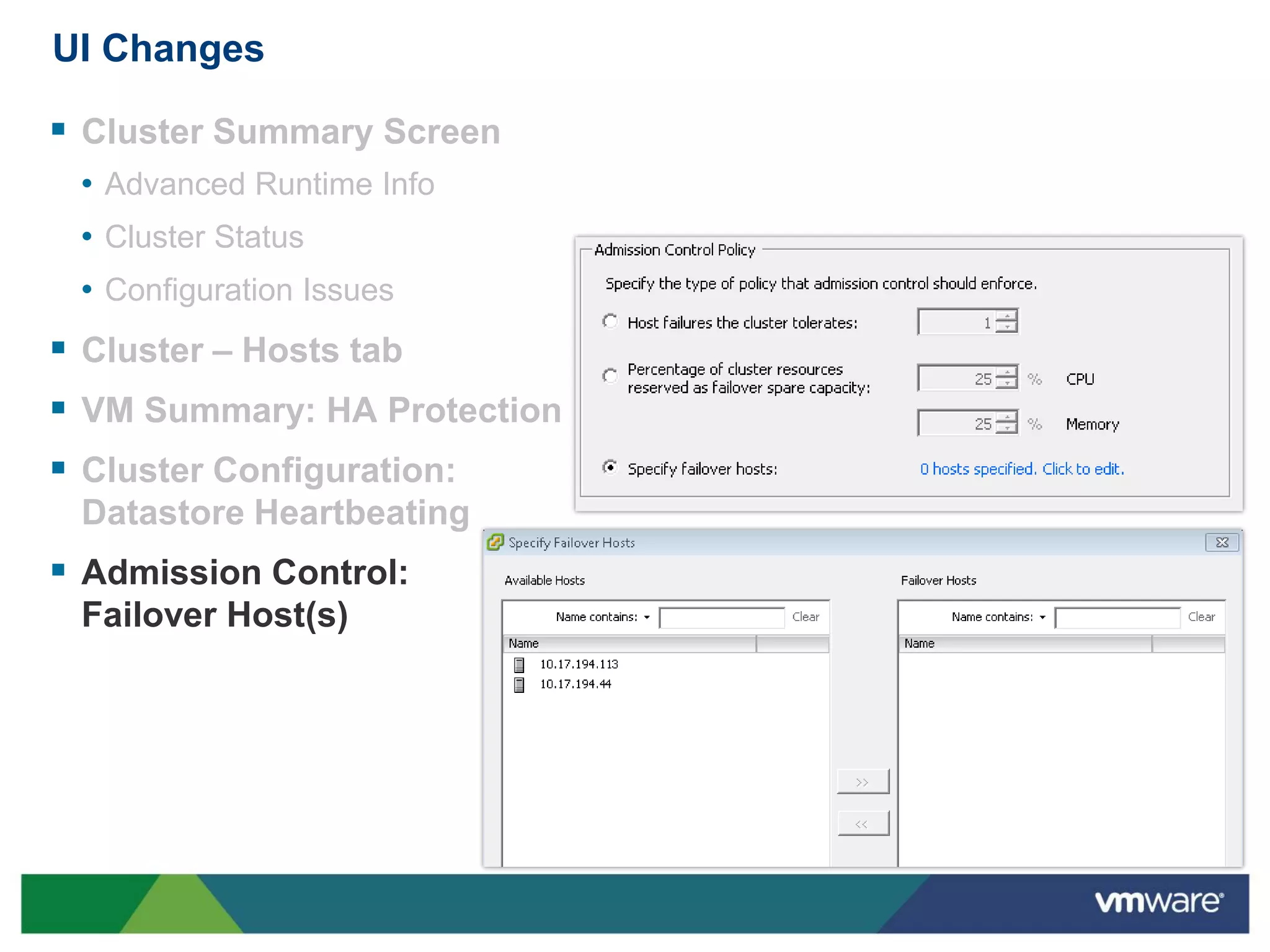


vSphere 5 High Availability (HA) enhances protection for critical applications by ensuring they can restart automatically upon failure and monitoring their health. Key improvements include the elimination of common issues, enhanced error reporting, and the ability to use storage for communication as a backup, thereby increasing redundancy and efficiency. The system architecture consists of master and slave agents that manage and monitor virtual machines and hosts, providing streamlined processes for failure recovery and state management.






















































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)














