Download as PDF, PPTX




![Really Quick Start
1) Install Vagrant http://www.vagrantup.com/
2) Install Virtual Box https://www.virtualbox.org/
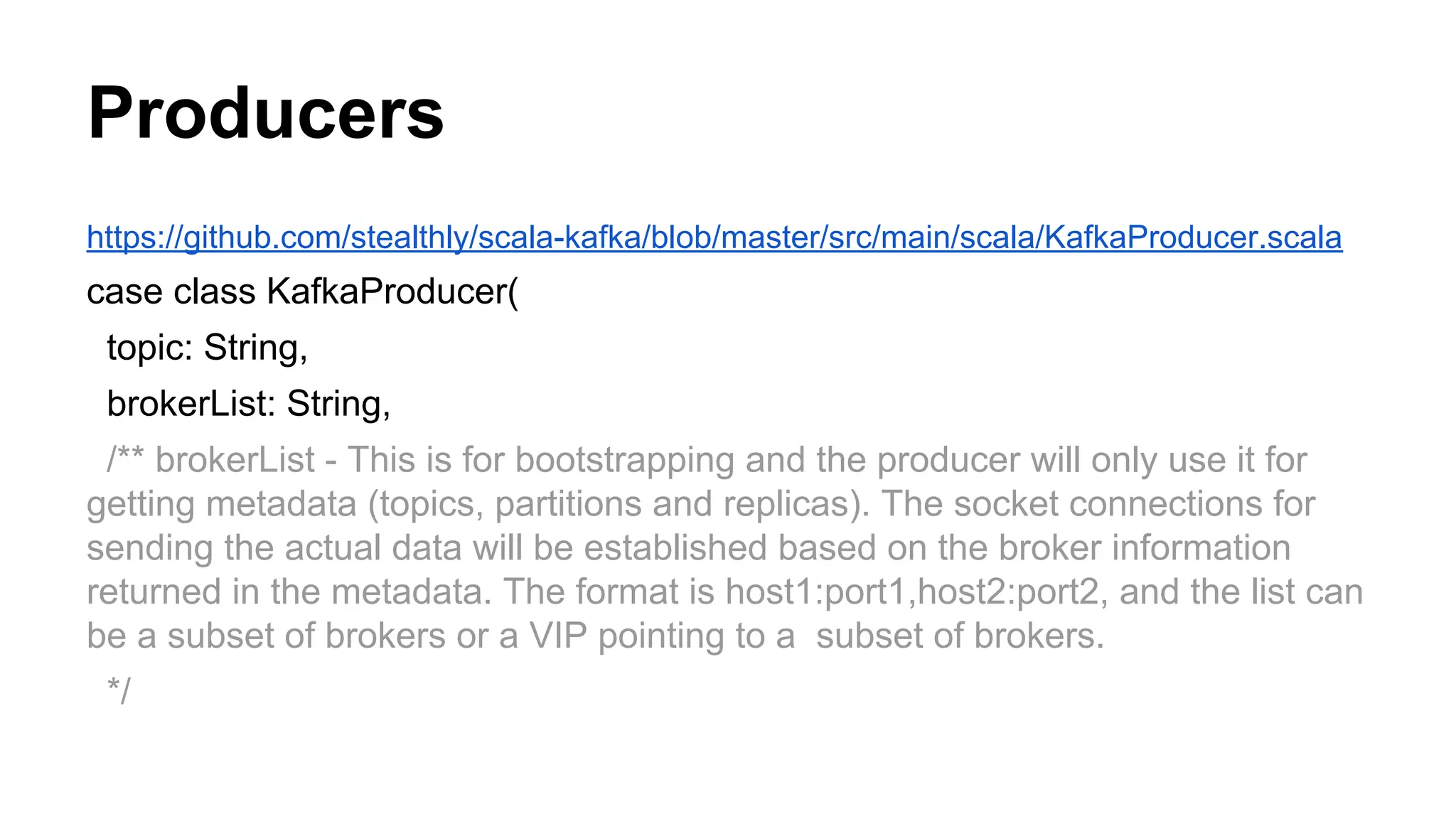
3) git clone https://github.com/stealthly/scala-kafka
4) cd scala-kafka
5) vagrant up
Zookeeper will be running on 192.168.86.5
BrokerOne will be running on 192.168.86.10
All the tests in ./src/test/scala/* should pass (which is also /vagrant/src/test/scala/* in the vm)
6) ./sbt test
[success] Total time: 37 s, completed Dec 19, 2013 11:21:13 AM](https://image.slidesharecdn.com/developing-140111112317-phpapp01/75/Developing-Real-Time-Data-Pipelines-with-Apache-Kafka-16-2048.jpg)




)
def kafkaMesssage(message: Array[Byte], partition: Array[Byte]): KeyedMessage[AnyRef, AnyRef] = {
if (partition == null) {
new KeyedMessage(topic,message)
} else {
new KeyedMessage(topic,message, partition)
}
}](https://image.slidesharecdn.com/developing-140111112317-phpapp01/75/Developing-Real-Time-Data-Pipelines-with-Apache-Kafka-25-2048.jpg)
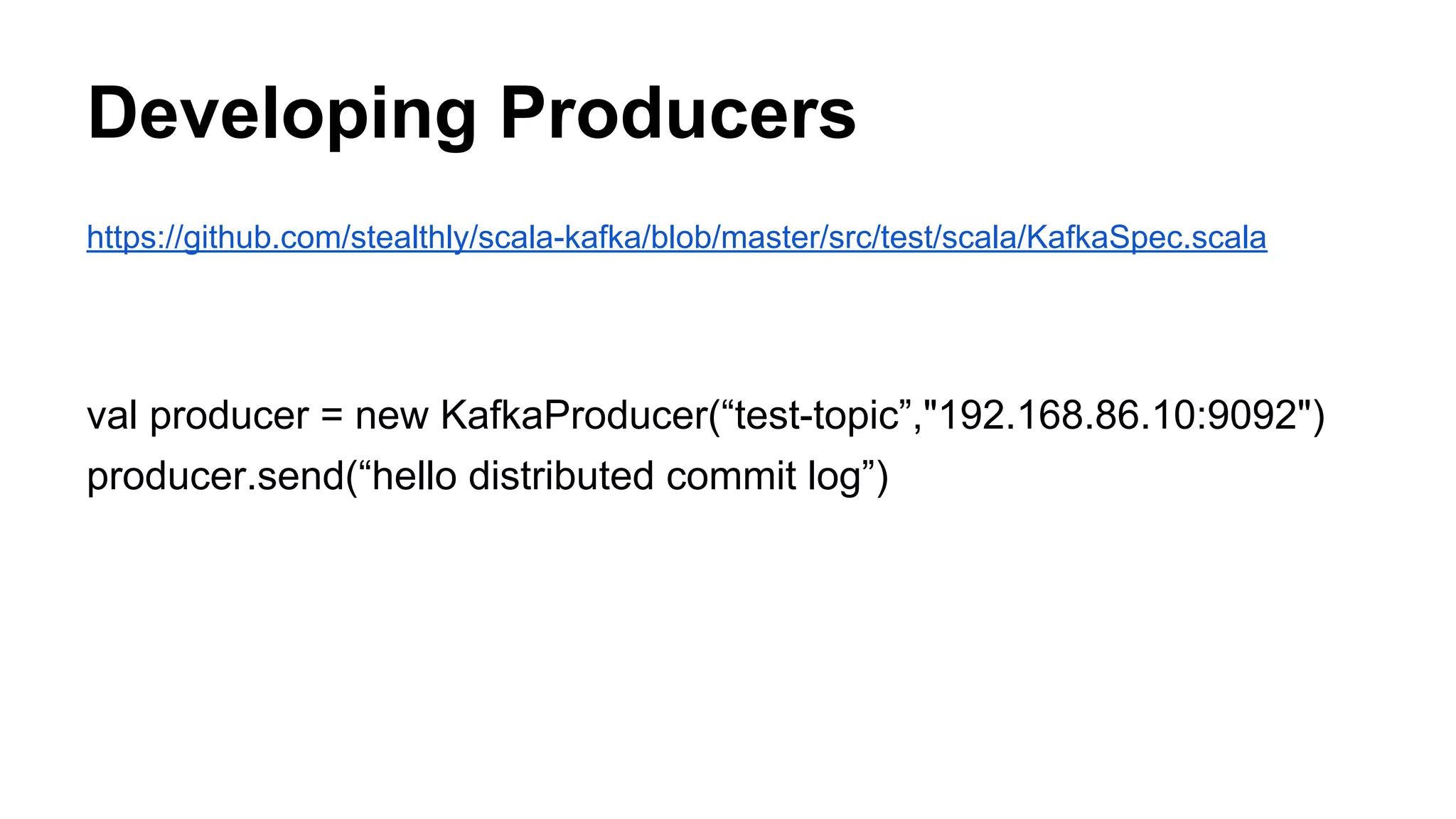
![Producer
def send(message: String, partition: String = null): Unit = {
send(message.getBytes("UTF8"), if (partition == null) null else partition.getBytes("UTF8"))
}
def send(message: Array[Byte], partition: Array[Byte]): Unit = {
try {
producer.send(kafkaMesssage(message, partition))
} catch {
case e: Exception =>
e.printStackTrace
System.exit(1)
}
}](https://image.slidesharecdn.com/developing-140111112317-phpapp01/75/Developing-Real-Time-Data-Pipelines-with-Apache-Kafka-26-2048.jpg)



![High Level Consumer
def read(write: (Array[Byte])=>Unit) = {
for(messageAndTopic <- stream) {
try {
write(messageAndTopic.message)
} catch {
case e: Throwable => error("Error processing message, skipping this message: ", e)
}
}
}](https://image.slidesharecdn.com/developing-140111112317-phpapp01/75/Developing-Real-Time-Data-Pipelines-with-Apache-Kafka-30-2048.jpg)
![High Level Consumer
https://github.com/stealthly/scala-kafka/blob/master/src/test/scala/KafkaSpec.scala
val consumer = new KafkaConsumer(“test-topic”,”groupTest”,"192.168.86.5:2181")
def exec(binaryObject: Array[Byte]) = {
//magic happens
}
consumer.read(exec)](https://image.slidesharecdn.com/developing-140111112317-phpapp01/75/Developing-Real-Time-Data-Pipelines-with-Apache-Kafka-31-2048.jpg)





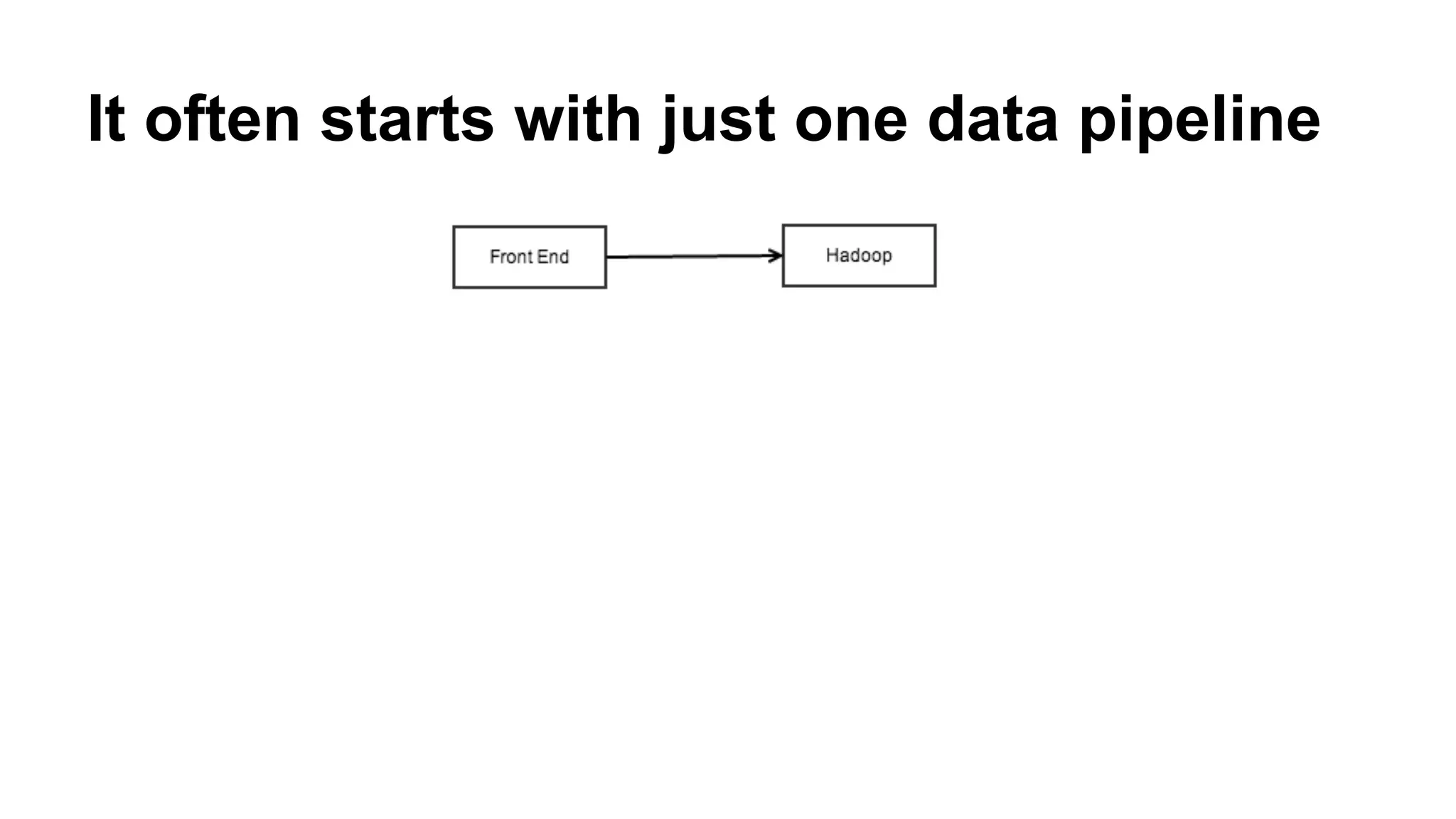
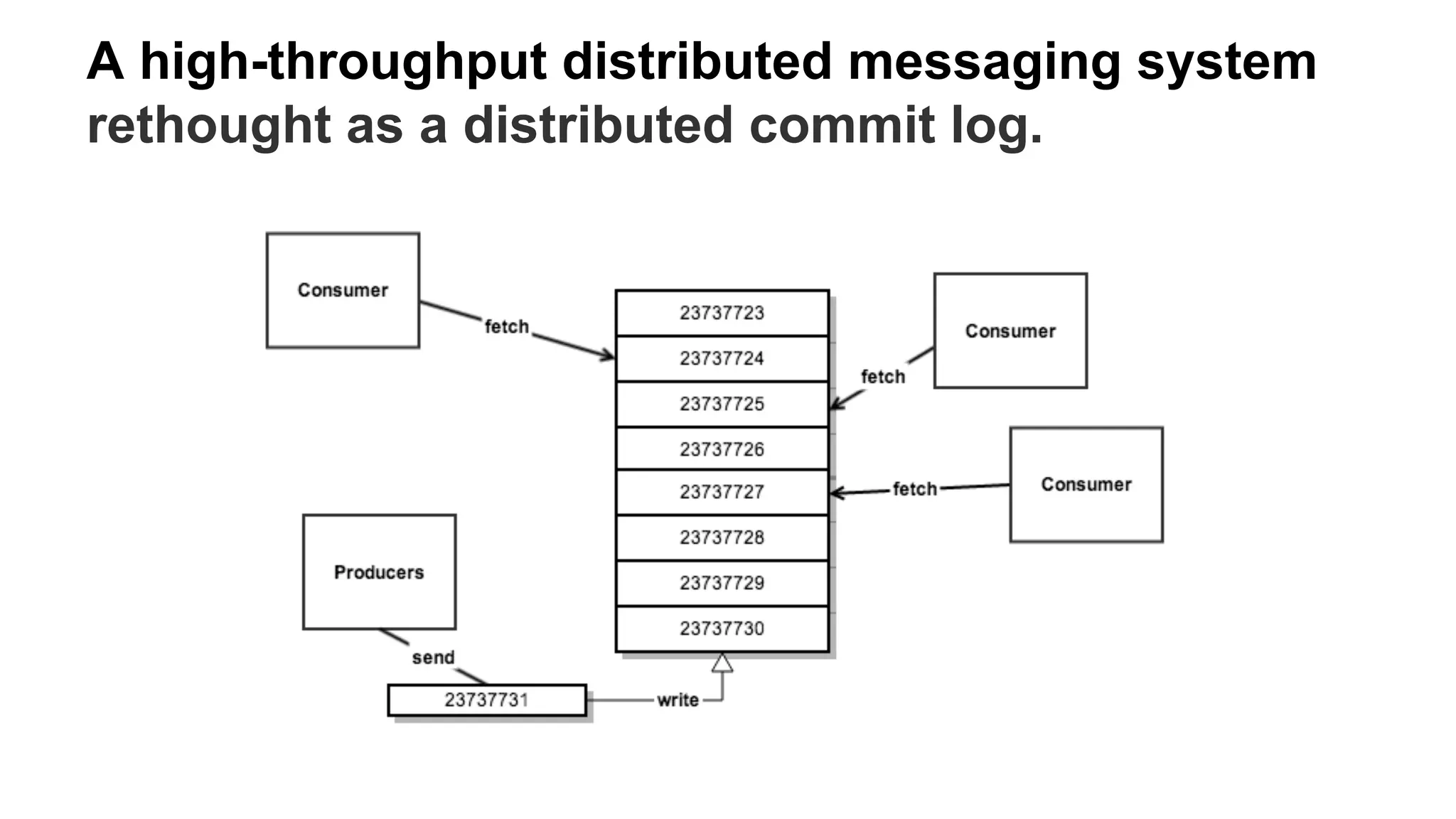
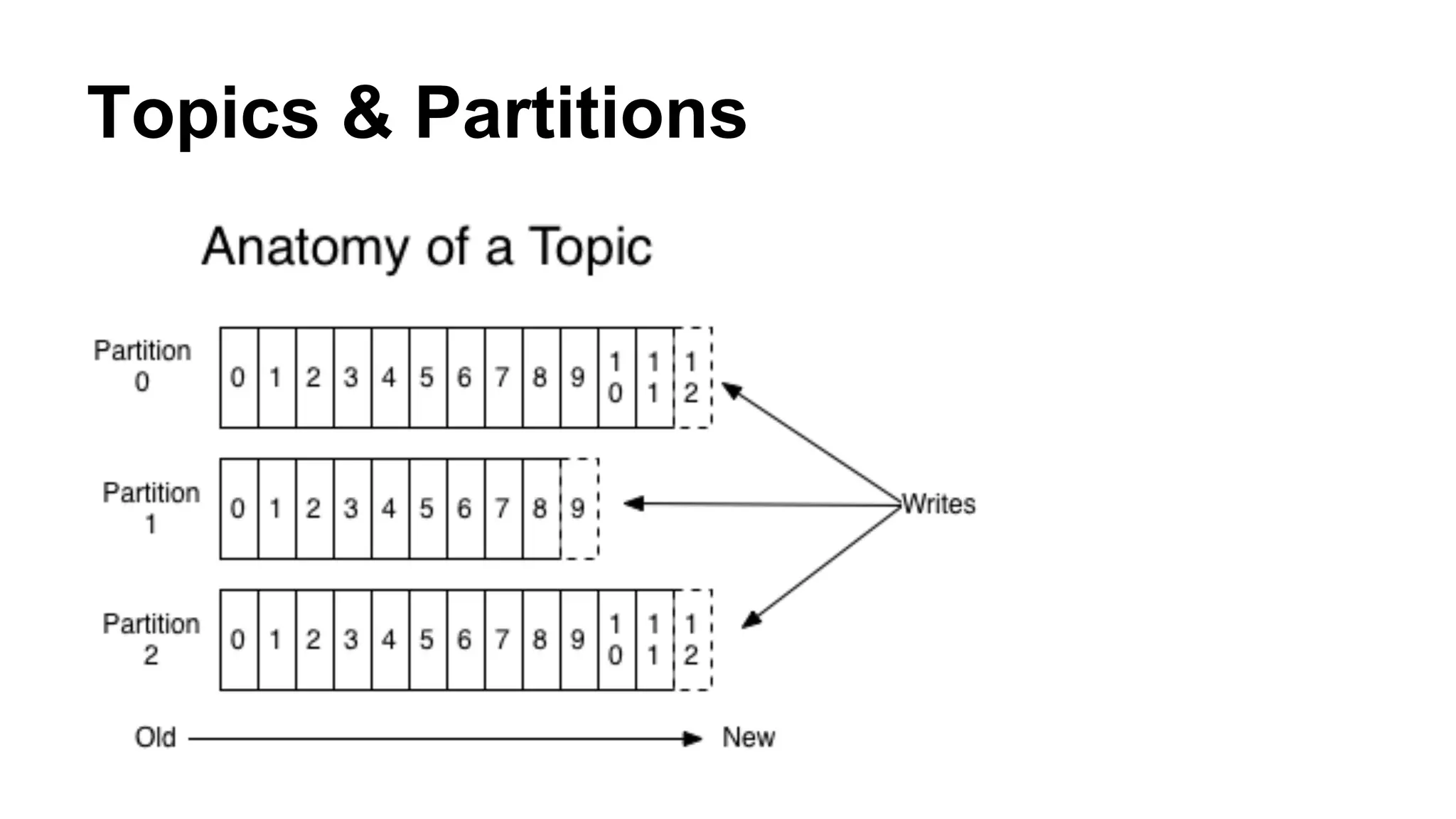
Apache Kafka is a distributed streaming platform that allows for building real-time data pipelines and streaming apps. It provides a publish-subscribe messaging system with persistence that allows for building real-time streaming applications. Producers publish data to topics which are divided into partitions. Consumers subscribe to topics and process the streaming data. The system handles scaling and data distribution to allow for high throughput and fault tolerance.
Introduction to Apache Kafka and its components, including producers, brokers, consumers, topics, and partitions.
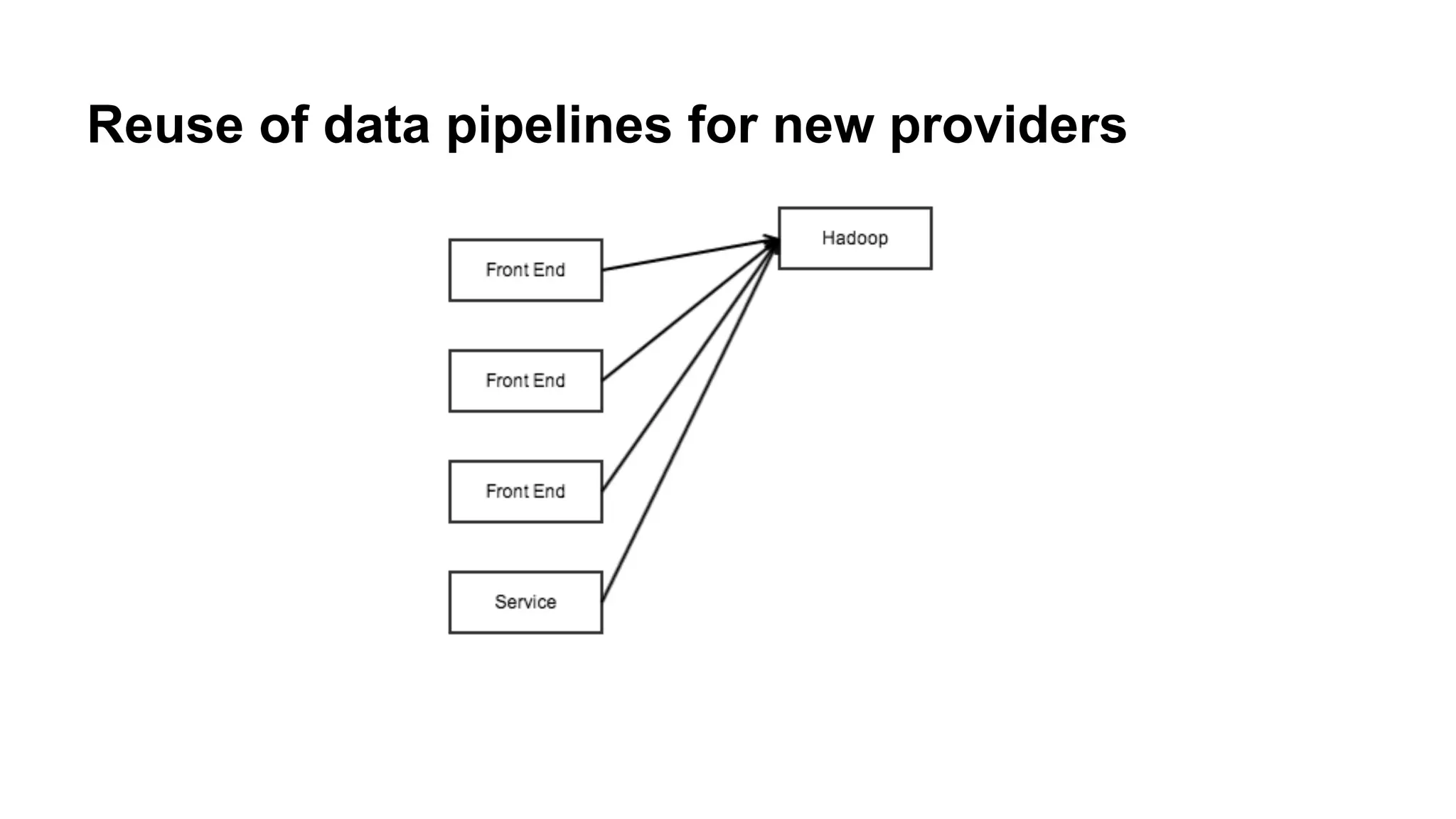
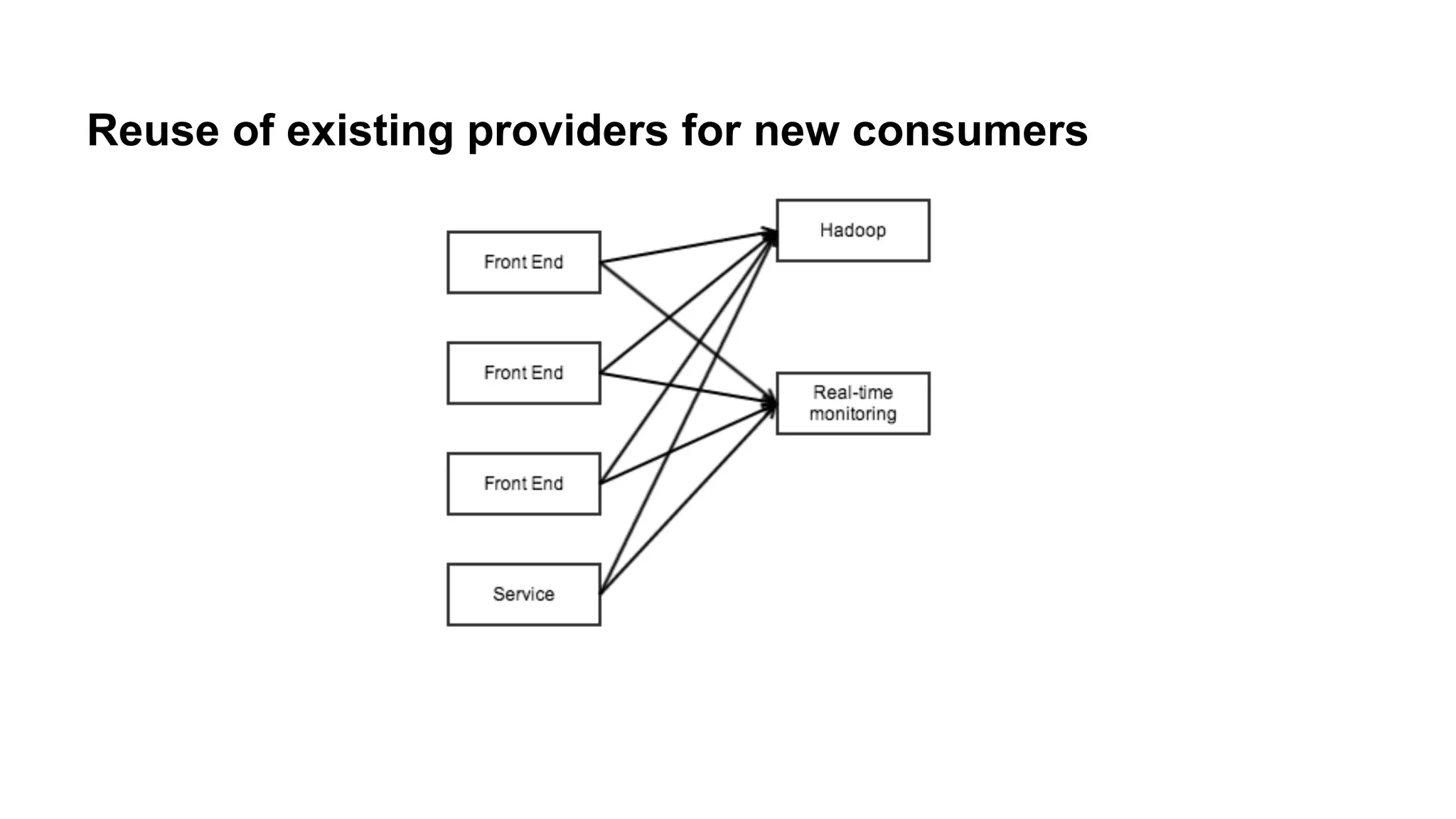
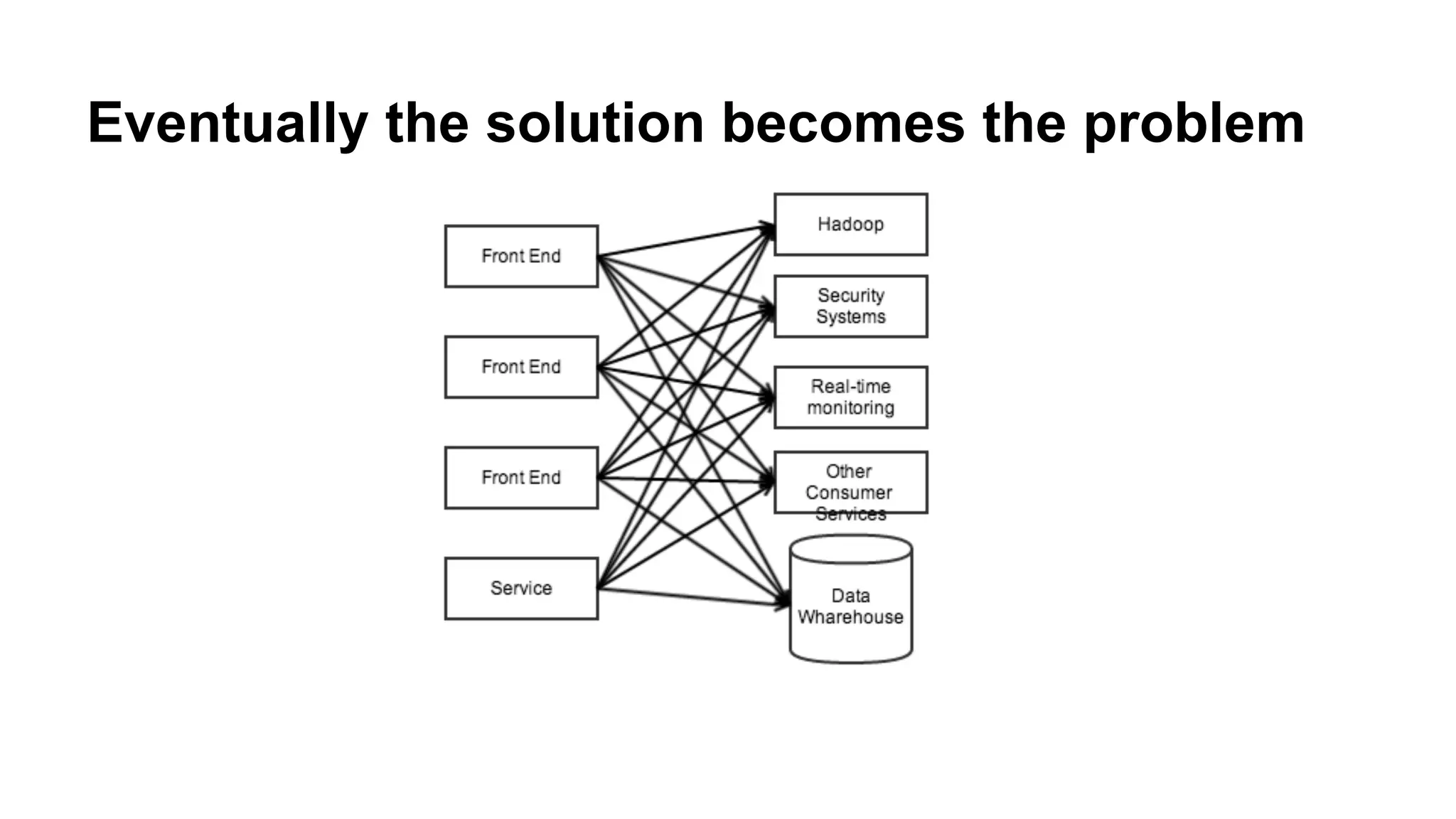
Discusses the reuse of data pipelines, highlighting how existing providers and consumers can be repurposed.
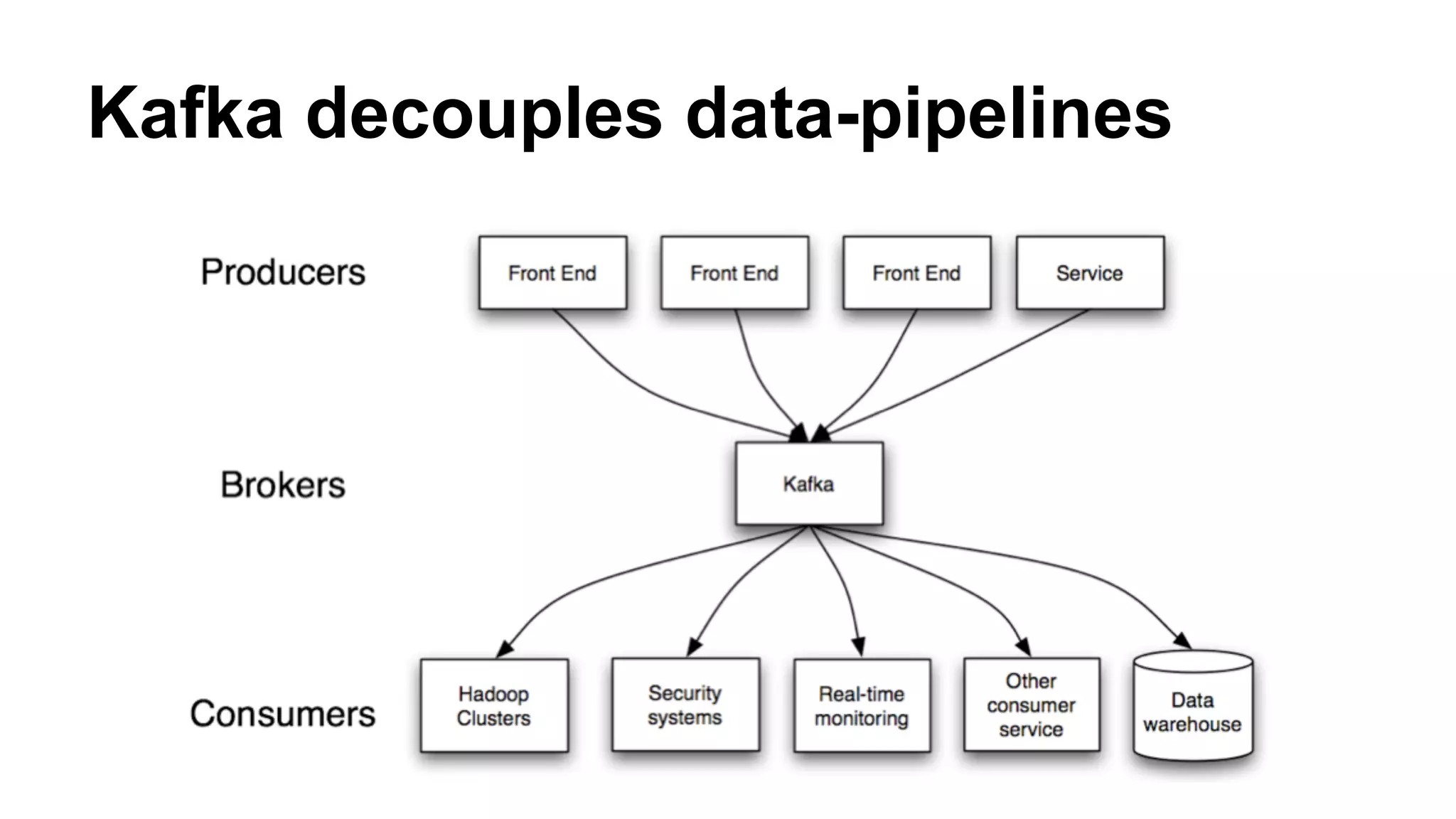
Explains how Kafka decouples data pipelines and presents a high-throughput distributed messaging system.
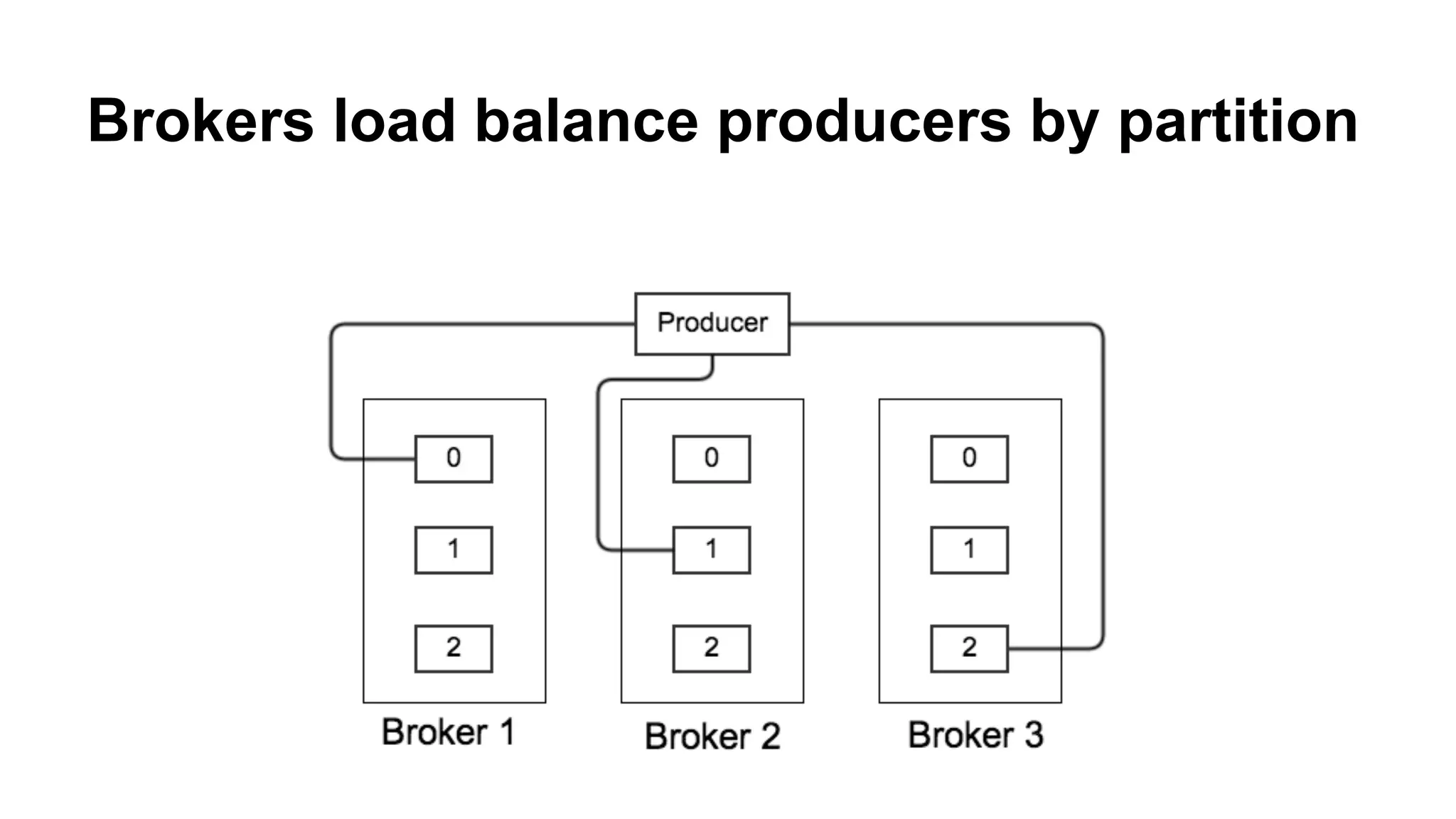
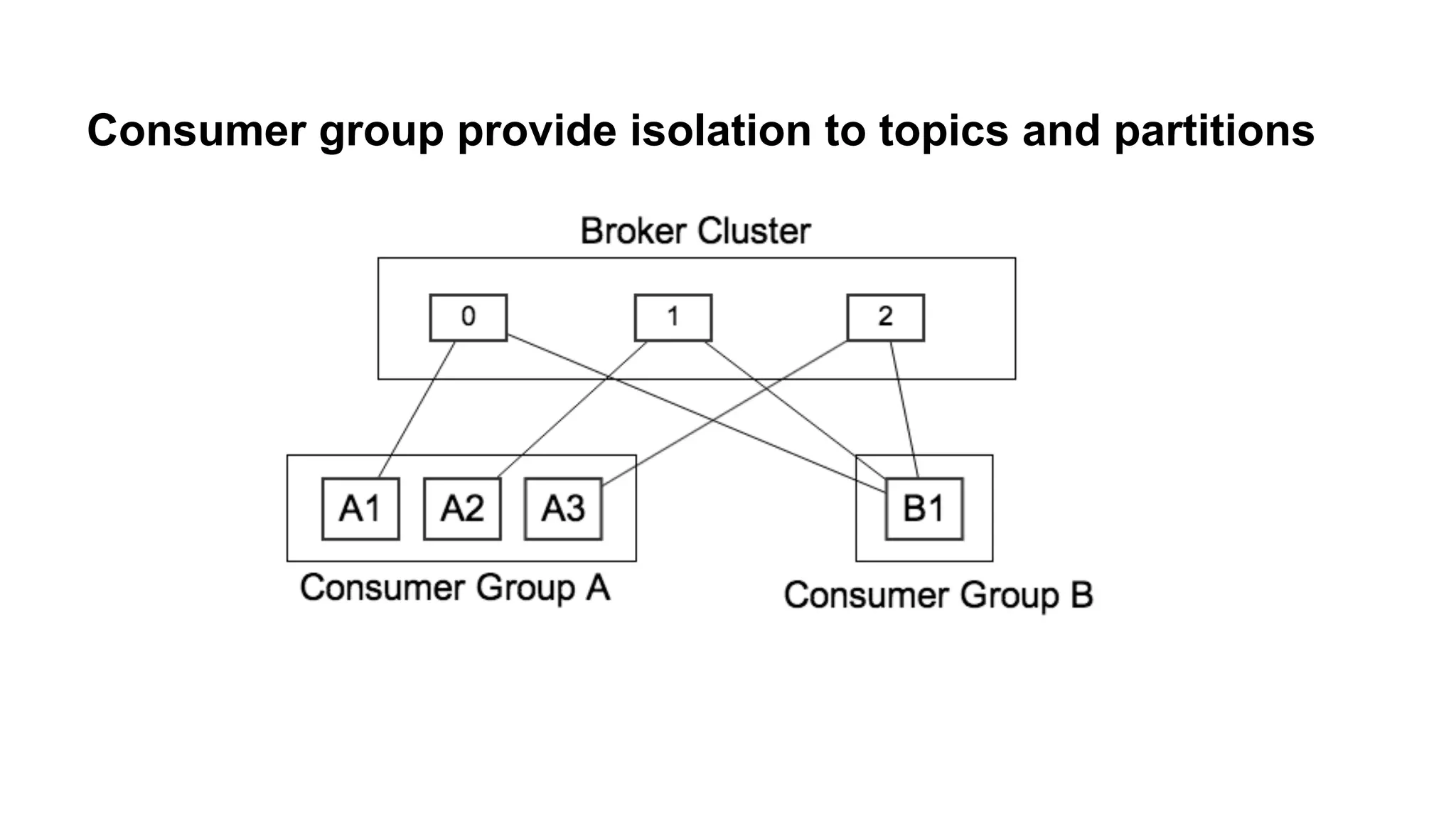
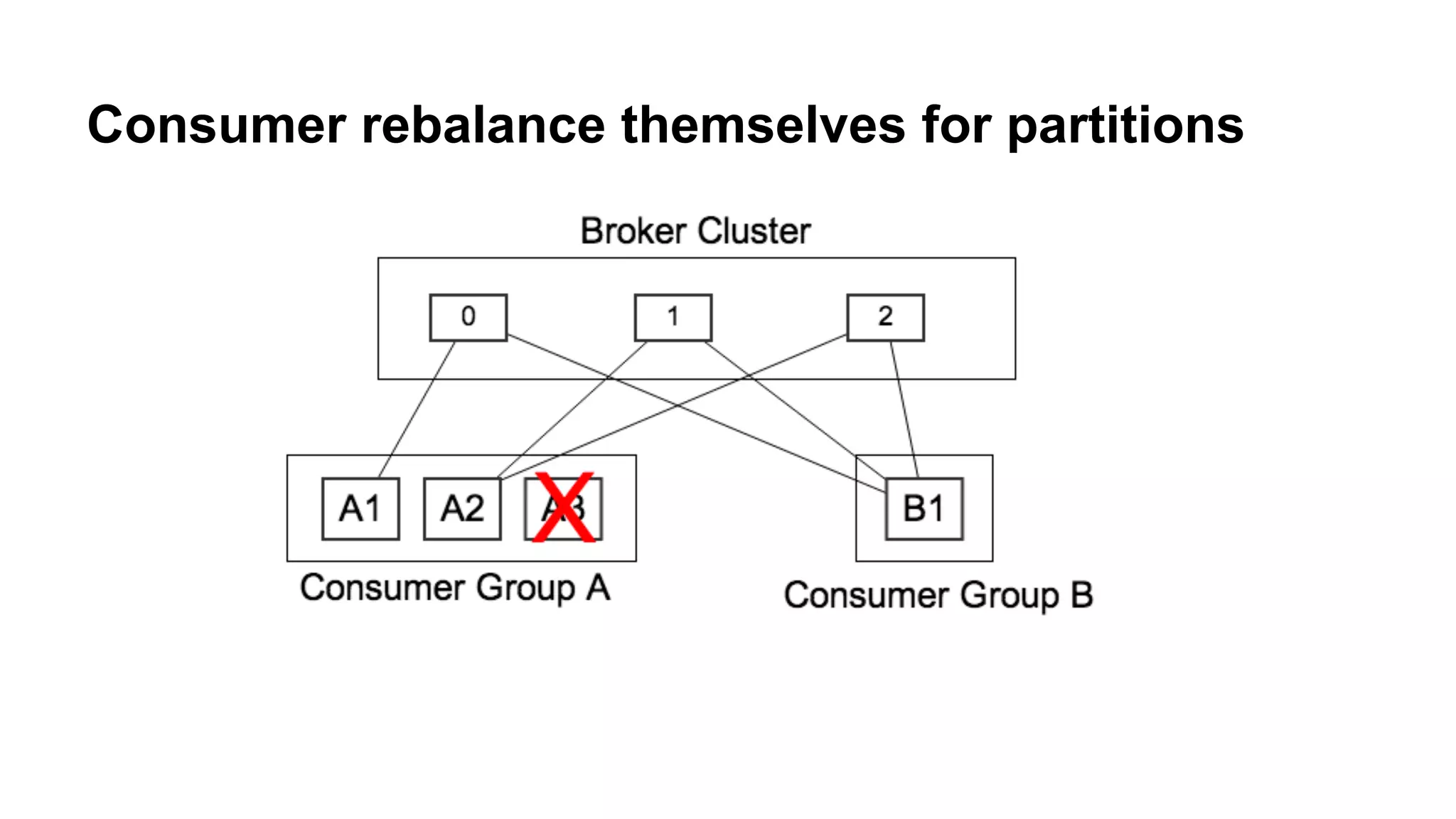
Describes the mechanics of Kafka's architecture, including producer and consumer functionalities, partitioning, and load balancing.
Gives an overview of existing integrations with others such as Apache Storm and client libraries available for diverse programming languages.
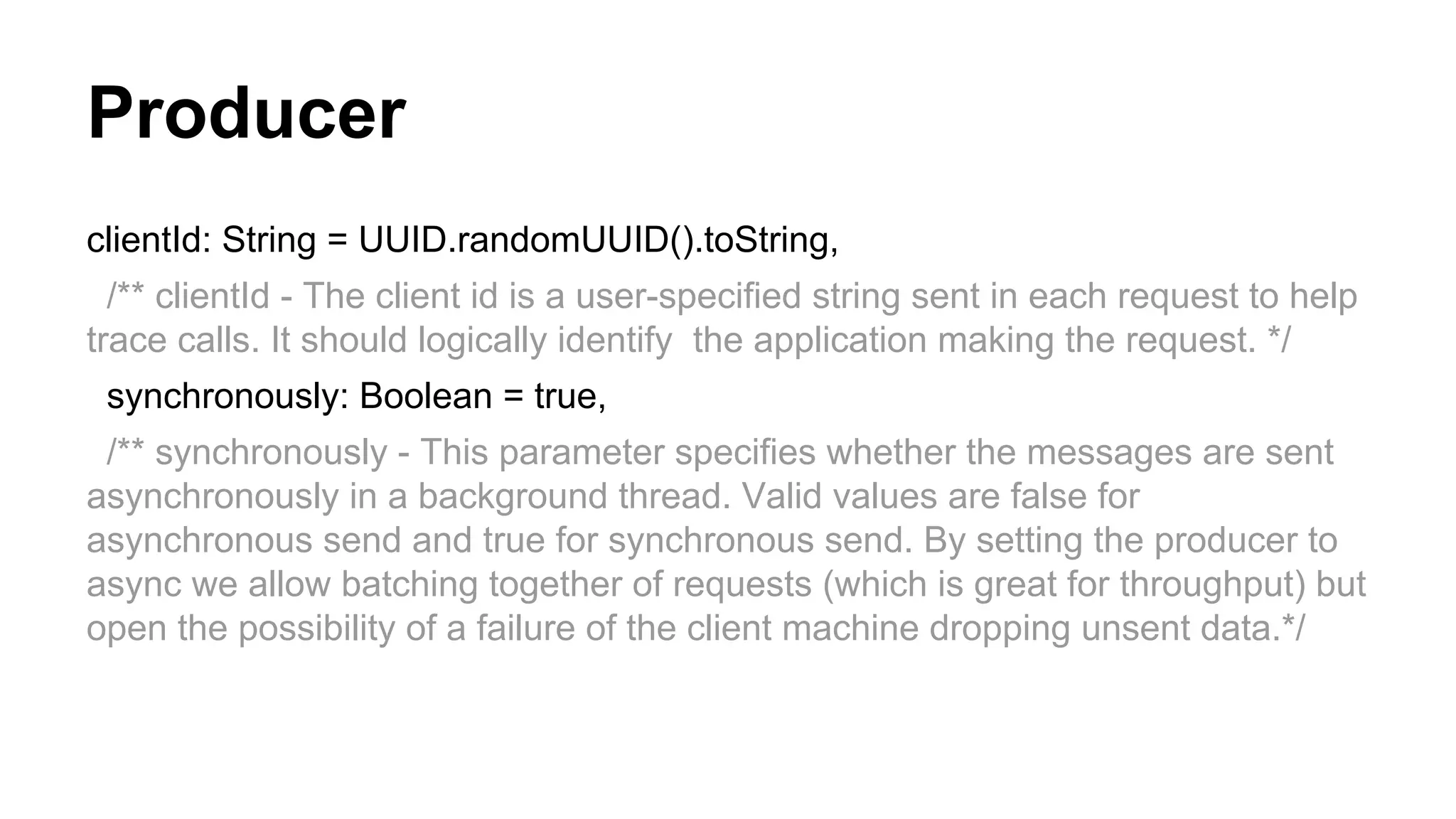
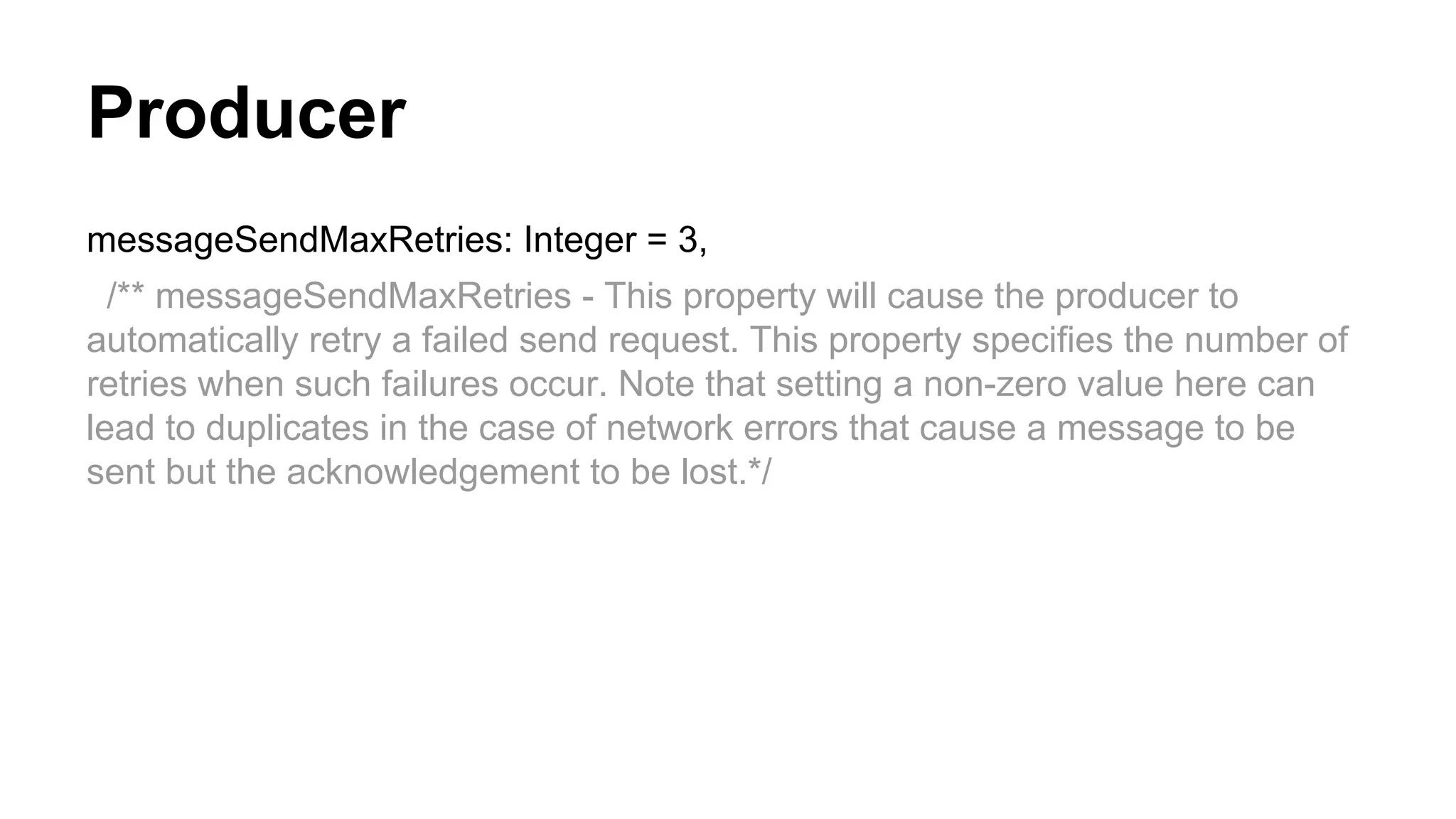
Details on developing Kafka producers, including the API, properties settings, message sending methods, and compression options.
Guidelines on developing high-level and simple consumers, their group settings, and how to handle messages.
Lists system and replication tools available in Kafka for managing consumer offsets, log segments, and partition reassignment.
Q&A session led by Joe Stein, inviting questions regarding Kafka and its usage.