Download as PDF, PPTX










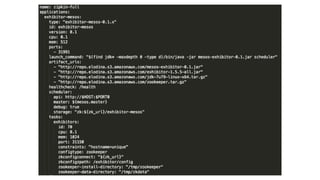









![Storm Nimbus
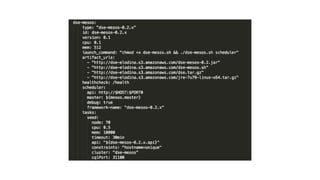
{
"id": "storm-nimbus",
"cmd": "cp storm.yaml storm-mesos-0.9.6/conf && cd storm-mesos-0.9.6 && ./bin/storm-mesos nimbus -c mesos.master.url=zk:
//zookeeper.service:2181/mesos -c storm.zookeeper.servers="["zookeeper.service"]" -c nimbus.thrift.port=$PORT0 -c topology.
mesos.worker.cpu=0.5 -c topology.mesos.worker.mem.mb=615 -c worker.childopts=-Xmx512m -c topology.mesos.executor.cpu=0.1 -c
topology.mesos.executor.mem.mb=160 -c supervisor.childopts=-Xmx128m -c mesos.executor.uri=http://repo.elodina.s3.amazonaws.
com/storm-mesos-0.9.6.tgz -c storm.log.dir=$(pwd)/logs",
"cpus": 1.0,
"mem": 1024,
"ports": [31056],
"requirePorts": true,
"instances": 1,
"uris": [
"http://repo.elodina.s3.amazonaws.com/storm-mesos-0.9.6.tgz",
"http://repo.elodina.s3.amazonaws.com/storm.yaml"
]
}](https://image.slidesharecdn.com/smackstack1-160330152334/85/SMACK-Stack-1-1-55-320.jpg)
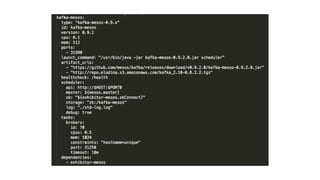
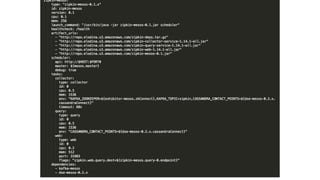
![Storm UI
{
"id": "storm-ui",
"cmd": "cp storm.yaml storm-mesos-0.9.6/conf && cd storm-mesos-0.9.6 && ./bin/storm ui -c ui.port=$PORT0 -c nimbus.thrift.port=31056 -c nimbus.
host=storm-nimbus.service -c storm.log.dir=$(pwd)/logs",
"cpus": 0.2,
"mem": 512,
"ports": [31067],
"requirePorts": true,
"instances": 1,
"uris": [
"http://repo.elodina.s3.amazonaws.com/storm-mesos-0.9.6.tgz",
"http://repo.elodina.s3.amazonaws.com/storm.yaml"
],
"healthChecks": [
{
"protocol": "HTTP",
"portIndex": 0,
"path": "/",
"gracePeriodSeconds": 120,
"intervalSeconds": 20,
"maxConsecutiveFailures": 3
}
]
}](https://image.slidesharecdn.com/smackstack1-160330152334/85/SMACK-Stack-1-1-56-320.jpg)

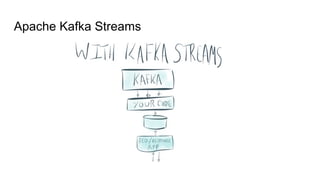
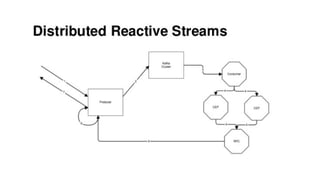
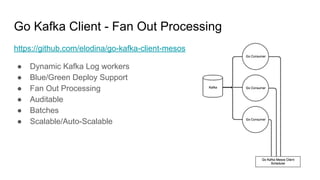


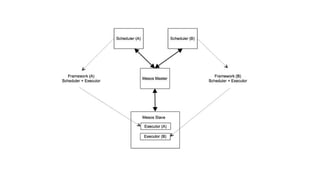
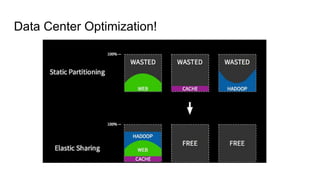
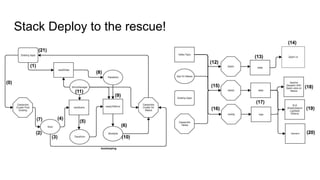
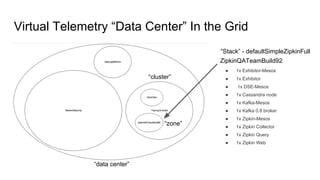
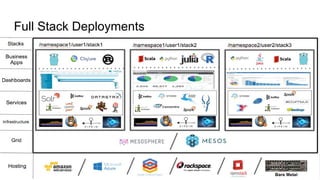
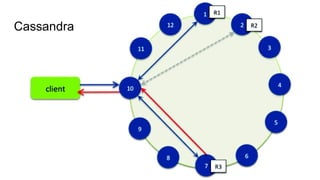
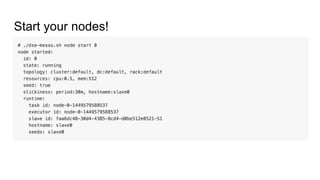
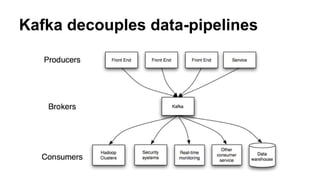
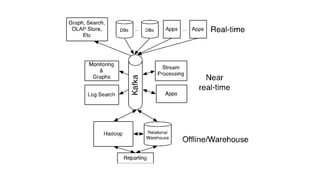
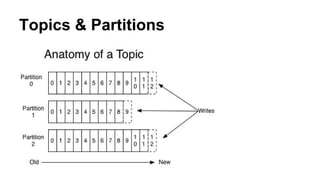
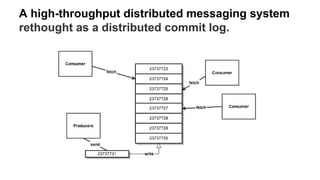
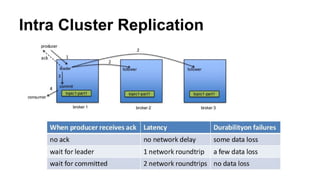
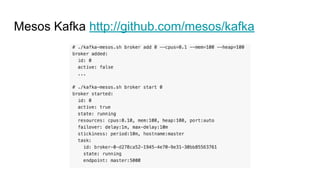
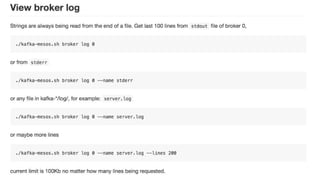
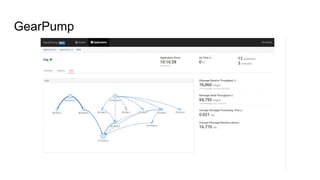
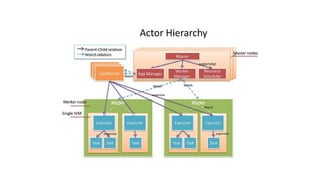
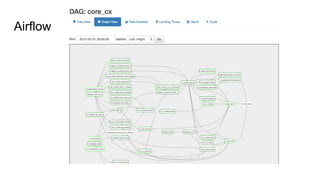
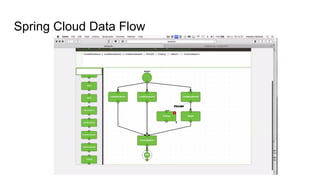
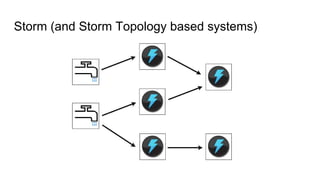
The document discusses the SMACK stack 1.1, which includes tools for streaming, Mesos, analytics, Cassandra, and Kafka. It describes how SMACK stack 1.1 adds capabilities for dynamic compute, microservices, orchestration, and microsegmentation. It also provides examples of running Storm on Mesos and using Apache Kafka for decoupling data pipelines.









































![[DO16] Mesosphere : Microservices meet Fast Data on Azure](https://cdn.slidesharecdn.com/ss_thumbnails/do16-170616021542-thumbnail.jpg?width=640&height=640&fit=bounds)







































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)



